辅助排序 WritableComparator排序(类):
1:原理:(借鉴别人的,个人觉得这个要好理解点)
它是用来给Key分组的
它在ReduceTask中进行,默认的类型是GroupingComparator也可以自定义
WritableComparator为辅助排序手段提供基础(继承它),用来应对不同的业务需求
比如GroupingComparator会在ReduceTask将文件写入磁盘并排序后按照Key进行分组,判断下一个key是否相同,将同组的Key传给reduce()执行
2:编写案例
需求:订单数据
求出每个订单中最贵的商品?
订单id正序,成交金额倒序。
结果文件三个,每个结果文件只要一条数据。
还是使用那个订单的数据,大概有哪些数据上面已经看了。根据需求编写MR程序
数据预览:
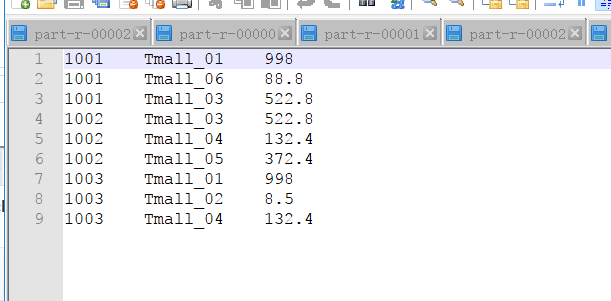
1:编写OrderBean实现序列化,并且完成排序
package it.dawn.YARNPra.基本用法.排序.辅助排序;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
/**
* @author Dawn
* @date 2019年5月8日12:37:44
* @version 1.0
* 实现序列化和第一次排序
*/
public class OrderBean implements WritableComparable<OrderBean>{
private int order_id;//订单id
private double price;//价格
public OrderBean() {
}
public OrderBean(int order_id, double price) {
this.order_id=order_id;
this.price=price;
}
public int getOrder_id() {
return order_id;
}
public void setOrder_id(int order_id) {
this.order_id = order_id;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
//序列化
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(order_id);
out.writeDouble(price);
}
//反序列化
@Override
public void readFields(DataInput in) throws IOException {
order_id=in.readInt();
price=in.readDouble();
}
@Override
public String toString() {
return order_id+" "+price;
}
//排序 需要比较id 再比较价格
@Override
public int compareTo(OrderBean o) {
int rs;
//根据id排序
if(order_id>o.order_id) {
//id大的往下排
rs = 1;
}else if(order_id<o.order_id) {
//id小的往上排
rs = -1;
}else {
//id相等 价格高的上排
rs=price>o.getPrice()? -1 :1;
}
return rs;
}
}
2:编写Map阶段
package it.dawn.YARNPra.基本用法.排序.辅助排序;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
/**
* @author Dawn
* @date 2019年5月8日12:52:06
* @version 1.0
* Map阶段直接读取数据,输出到reduce阶段
*/
public class OrderMapper extends Mapper<LongWritable, Text, OrderBean, NullWritable>{
@Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException {
//1.获取每行数据
String line=value.toString();
//2.切分数据
String[] fields=line.split(" ");
//3.取出字段
Integer order_id=Integer.valueOf(fields[0]);
Double price=Double.valueOf(fields[2]);
//4.输出
context.write(new OrderBean(order_id, price), NullWritable.get());
}
}
3:编写分区:
package it.dawn.YARNPra.基本用法.排序.辅助排序;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Partitioner;
/**
* @author Dawn
* @date 2019年5月8日12:52:58
* @version 1.0
* 分区 参照源码,使用hash算法
*/
public class OrderPartitioner extends Partitioner<OrderBean, NullWritable>{
@Override
public int getPartition(OrderBean key, NullWritable value, int numPartitions) {
return (key.getOrder_id() & Integer.MAX_VALUE) % numPartitions;
}
}
4:编写辅助排序(这里其实就起了一个作用,就是取第一个元素)
package it.dawn.YARNPra.基本用法.排序.辅助排序;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
/**
* @author Dawn
* @date 2019年5月8日12:57:20
* @version 1.0
* 辅助排序
*/
public class OrderGroupingComparator extends WritableComparator{
//构造必须加
protected OrderGroupingComparator() {
//我也不是很清楚这里。。。。。打脑壳
//反正说的是必须写这一步,不写会出错
super(OrderBean.class,true);
}
//重写比较
public int compare(WritableComparable a,WritableComparable b) {
OrderBean aBean=(OrderBean)a;
OrderBean bBean=(OrderBean)b;
int rs;
//id不是同一个对象
if(aBean.getOrder_id()>bBean.getOrder_id()) {
rs=1;
}else if(aBean.getOrder_id()<bBean.getOrder_id()) {
rs=-1;//个人觉得这2个if没必要要了。应为在序列化排序的时候就已经实现这部分,直接反回个0,取第一个元素就OK了
}else {
//取第一个元素
rs=0;
}
return rs;
}
}
5:编写Reduce阶段
package it.dawn.YARNPra.基本用法.排序.辅助排序;
import java.io.IOException;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Reducer;
/**
* @author Dawn
* @date 2019年5月8日12:55:41
* @version 1.0
*
*/
public class OrderReducer extends Reducer<OrderBean, NullWritable, OrderBean, NullWritable>{
@Override
protected void reduce(OrderBean key, Iterable<NullWritable> value,Context context)
throws IOException, InterruptedException {
context.write(key, NullWritable.get());
}
}
6:编写driver类:
package it.dawn.YARNPra.基本用法.排序.辅助排序;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* @author Dawn
* @date 2019年5月8日13:03:14
* @version 1.0
* 需求?订单数据
* 求出每个订单中最贵的商品?
*
* 1:订单id正序,成交金额倒序。
* 2:结果文件三个,每个结果文件只要一条数据。
*/
public class OrderDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf=new Configuration();
Job job=Job.getInstance(conf);
job.setJarByClass(OrderDriver.class);
job.setMapperClass(OrderMapper.class);
job.setReducerClass(OrderReducer.class);
job.setMapOutputKeyClass(OrderBean.class);
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(OrderBean.class);
job.setOutputValueClass(NullWritable.class);
//设置reducer端的分组
job.setGroupingComparatorClass(OrderGroupingComparator.class);
//设置分区,和reduceTask个数
job.setPartitionerClass(OrderPartitioner.class);
job.setNumReduceTasks(3);
FileInputFormat.setInputPaths(job, new Path("f:/temp/order.txt"));
FileOutputFormat.setOutputPath(job, new Path("f:/temp/Order结果"));
boolean rs=job.waitForCompletion(true);
System.out.println(rs?"成功":"失败");
}
}
运行结果如下


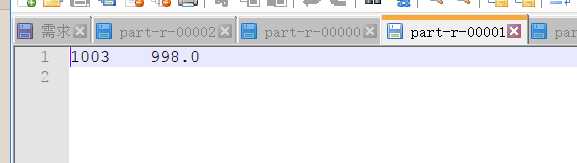
个人总结:辅助排序应该用的很少吧!应为在第一次排序的时候感觉就可以完成很多辅助排序的逻辑了!我也是菜鸟,期待大神的指点