一:自定义输出
需求:将多个小文件合并为SequenceFile(存储了多个小文件)
存储格式:文件路径+文件的内容
c:/a.txt i am hunter henshuai
c:/b.txt i love delireba
inputFormat(自定义加上路径)
代码编写:
1:自定义FileInputFormat编写
package it.dawn.YARNPra.自定义.inputformate;
import java.io.IOException;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.JobContext;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
/**
* @author Dawn
* @date 2019年5月9日22:58:19
* @version 1.0
* 自定义输入,自己编写框架
* 需求?
* 将多个小文件合并为SequenceFile(存储了多个小文件)
* 存储格式:文件路径+文件的内容
* c:/a.txt i am hunter henshuai
* c:/b.txt i love delireba
*
* inputFormat(自定义加上路径)
*/
//1.创建自定义inputformat
//为什么是用NullWritable, BytesWritable,
//因为,这里的key我们暂时处理为空。到后面Map输出阶段的时候,我们再讲输出类型改成Text 和BytesWritable
public class FuncFileInputFormat extends FileInputFormat<NullWritable, BytesWritable>{
@Override
protected boolean isSplitable(JobContext context,Path filename) {
//不切原来的文件
return false;
}
@Override
public RecordReader<NullWritable, BytesWritable> createRecordReader(InputSplit split, TaskAttemptContext context)
throws IOException, InterruptedException {
FuncRecordReader RecordReader=new FuncRecordReader();
return RecordReader;
}
}
2:自定义RecordReader类编写
package it.dawn.YARNPra.自定义.inputformate;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
/**
* @author Dawn
* @date 2019年5月9日23:12:03
* @version 1.0
*
*/
//2.编写RecordReader
public class FuncRecordReader extends RecordReader<NullWritable, BytesWritable>{
boolean isProcess = false;
FileSplit split;
Configuration conf;
BytesWritable value = new BytesWritable();
@Override
public void initialize(InputSplit split, TaskAttemptContext context) {
//初始化切片
this.split=(FileSplit) split;
//初始化配置信息
conf=context.getConfiguration();
}
@Override
public boolean nextKeyValue() throws IOException, InterruptedException {
if(!isProcess) {
//1.根据切片的长度来创建缓冲区
byte[] buf= new byte[(int)split.getLength()];
FSDataInputStream fis = null;
FileSystem fs = null;
try {
//2.获取路径
Path path=split.getPath();
//3.根据路径获取文件系统
fs=path.getFileSystem(conf);
//4:拿到输入流
fis=fs.open(path);
//5:数据拷贝
IOUtils.readFully(fis, buf, 0, buf.length);
//6.拷贝缓存到最终的输出
value.set(buf, 0, buf.length);
}catch (IOException e) {
e.printStackTrace();
}finally {
IOUtils.closeStream(fis);
IOUtils.closeStream(fs);
}
isProcess=true;
return true;
}
return false;
}
@Override
public NullWritable getCurrentKey() throws IOException, InterruptedException {
// TODO Auto-generated method stub
return NullWritable.get();
}
@Override
public BytesWritable getCurrentValue() throws IOException, InterruptedException {
// TODO Auto-generated method stub
return value;
}
@Override
public float getProgress() throws IOException, InterruptedException {
// TODO Auto-generated method stub
return 0;
}
@Override
public void close() throws IOException {
// TODO Auto-generated method stub
}
}
3:编写MR
map:
package it.dawn.YARNPra.自定义.inputformate;
import java.io.IOException;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
/**
* @author Dawn
* @date 2019年5月9日23:25:29
* @version 1.0
*
*/
public class SequenceFileMapper extends Mapper<NullWritable, BytesWritable, Text, BytesWritable>{
Text k=new Text();
@Override
protected void setup(Context context)
throws IOException, InterruptedException {
//1拿到切片信息
FileSplit split=(FileSplit) context.getInputSplit();
//2路径
Path path=split.getPath();
//3.即带路径又带名称
k.set(path.toString());
}
@Override
protected void map(NullWritable key, BytesWritable value,Context context)
throws IOException, InterruptedException {
context.write(k, value);
}
}
Reducer:
package it.dawn.YARNPra.自定义.inputformate;
import java.io.IOException;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class SequenceFileReducer extends Reducer<Text, BytesWritable, Text, BytesWritable>{
@Override
protected void reduce(Text key, Iterable<BytesWritable> value,
Context context) throws IOException, InterruptedException {
for(BytesWritable v:value) {
context.write(key, v);
}
}
}
driver:
package it.dawn.YARNPra.自定义.inputformate;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
/**
* @author Dawn
* @date 2019年5月9日23:32:39
* @version 1.0
*
*/
public class SequenceDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 1.获取job信息
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 2.获取jar包
job.setJarByClass(SequenceDriver.class);
// 3.获取自定义的mapper与reducer类
job.setMapperClass(SequenceFileMapper.class);
job.setReducerClass(SequenceFileReducer.class);
//设置自定义读取方式
job.setInputFormatClass(FuncFileInputFormat.class);
//设置默认的输出方式
job.setOutputFormatClass(SequenceFileOutputFormat.class);
// 4.设置map输出的数据类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(BytesWritable.class);
// 5.设置reduce输出的数据类型(最终的数据类型)
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(BytesWritable.class);
// 6.设置输入存在的路径与处理后的结果路径
FileInputFormat.setInputPaths(job, new Path("f:/temp/inputSelf/*.txt"));
FileOutputFormat.setOutputPath(job, new Path("f:/temp/inputSelfout1"));
// 7.提交任务
boolean rs = job.waitForCompletion(true);
System.out.println(rs ? 0 : 1);
}
}
运行结果截图:
输入:
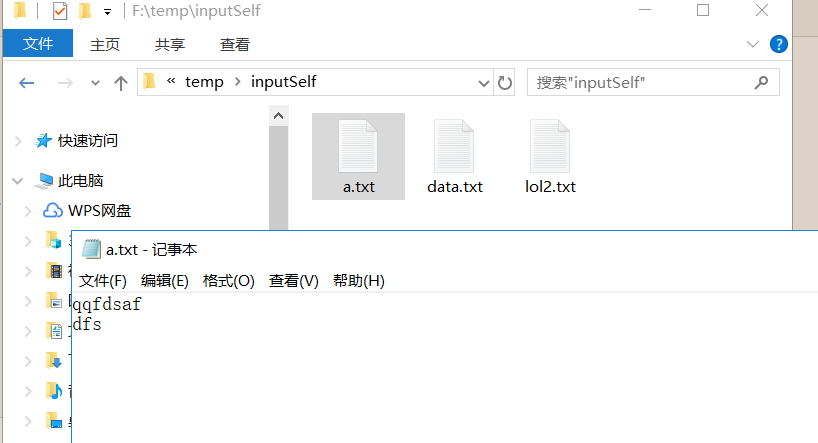
输出(将就看吧!输出格式是BytesWriteble字节的输出,看起来不是很好):