1:Azkaban概述
Azkaban是一个分布式工作流管理器,在LinkedIn上实现,以解决Hadoop作业依赖性问题。我们有需要按顺序运行的工作,从ETL工作到数据分析产品。
2:为什么需要工作流调度系统
1)一个完整的数据分析系统通常都是由大量任务单元组成:
shell 脚本程序,java 程序,mapreduce 程序、hive 脚本等。
2)各任务单元之间存在时间先后及前后依赖关系。
3)为了很好地组织起这样的复杂执行计划,需要一个工作流调度系统来调度执行。
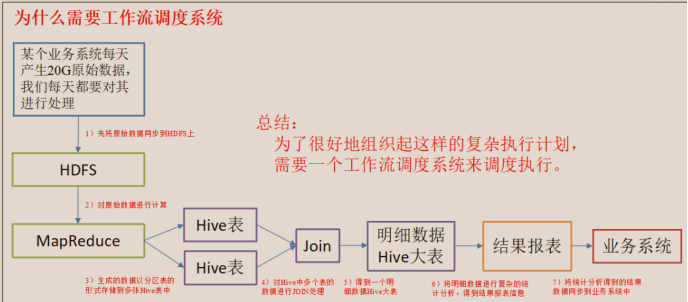
例如,我们可能有这样一个需求,某个业务系统每天产生 20G 原始数据,我们每天都要对其进行处理,处理步骤如下所示:
(1)通过 Hadoop 先将原始数据同步到 HDFS 上;
(2)借助 MapReduce 计算框架对原始数据进行计算,生成的数据以分区表的形式存储到多张 Hive 表中;
(3)需要对 Hive 中多个表的数据进行 JOIN 处理,得到一个明细数据 Hive 大表;
(4)将明细数据进行复杂的统计分析,得到结果报表信息;
(5)需要将统计分析得到的结果数据同步到业务系统中,供业务调用使用。
如下图所示:
2:特点:
1)给用户提供了一个非常友好的可视化界面->web界面
2)非常方便的上传工作流-》打成压缩包
3)设置任务间的关系
4)权限设置-》删库到跑路
5)模块化
6)随时停止和启动任务
7)可以查看日志记录
3:与Oozie对比
和Oozie相对比,azkaban是一个轻量级调度工具。
企业应用的功能并非小众的功能可以使用Azkaban。
1)功能
两个任务流调度器可以调度使用mr,java,脚本工作流任务
都可以进行定时调度...
2)使用
az直接传参
Oozie直接传参,支持EL表达式...
3)定时
az定时执行任务基于时间
Oozie任务基于时间和数据
4)资源
az有严格的权限控制
Oozie无雅阁权限控制
4:Azkaban安装部署
准备工作
1)快照
2)上传安装包
alt+p
3)解压重命名
tar -zxvf
mv
4)mysql中azkaban脚本导入
source /root/hd/azkaban/azkaban-2.5.0/create-all-sql-2.5.0.sql
安装部署
1)创建SSL(安全连接)配置
服务器需要一个证书
keytool -keystore keystore -alias jetty -genkey -keyalg RSA
2)时间同步设置
生成时区文件
tzselect生成
5->9->1->yes
拷贝时区文件
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
集群时间同步
crt中开启交互窗口 发送
sudo date -s '2018-11-28 20:41:33'
3)修改配置文件
4)启动web服务器
bin/azkaban-web-start.sh
5)启动执行器
bin/azkaban-executor-start.sh
6)访问web
这里安装步骤我写的很粗略,可以参照这篇文章来安装部署
https://www.cnblogs.com/chenmingjun/p/10506488.html
实战操作
案例一:Command类型之单job
创建job描述文件:

然后打包成zip文件上传到azkaban中

案例二:Command类型之多job案例
创建f.job
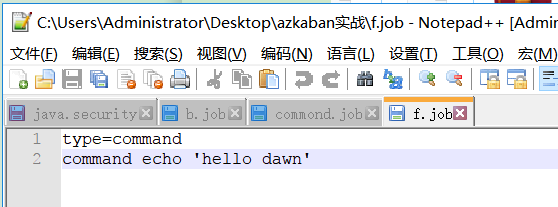
创建b.job

其中b依赖f
然后将这2个job文件打包在一个zip并上传到azkaban中。
案例三:hdfs任务操作
创建job文件

注意这里使用到的hdfs命令必须是Linux中该命令的全路径
然后将这个job文件打包成zip并上传到azkaban中。
案例4:运行MapReduce程序
这里我们用的是hadoop自带的一个例子程序。下面编写job文件
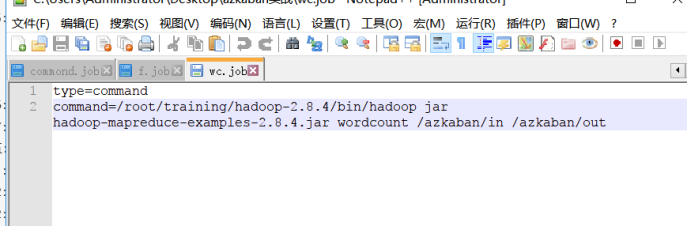
将单词计数的jar文件 和job文件打包上传到azkaban任务中
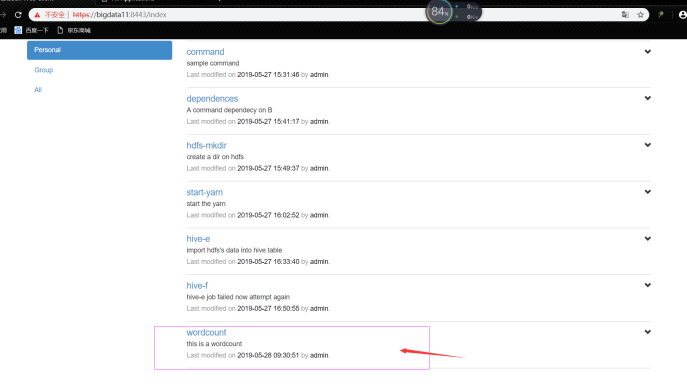
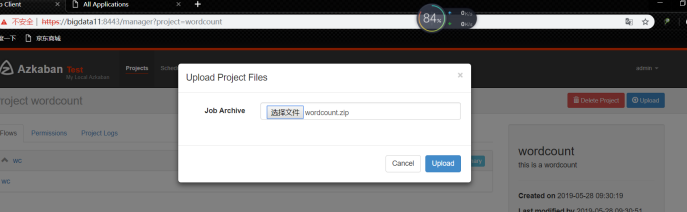
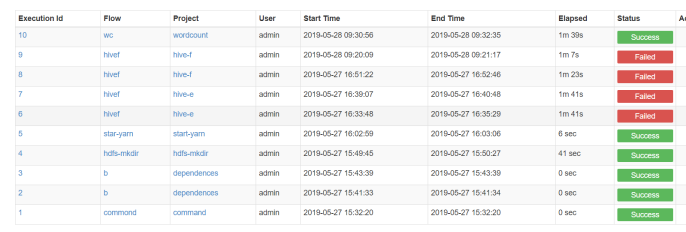
案例5 hive脚本任务
1:创建hive脚本
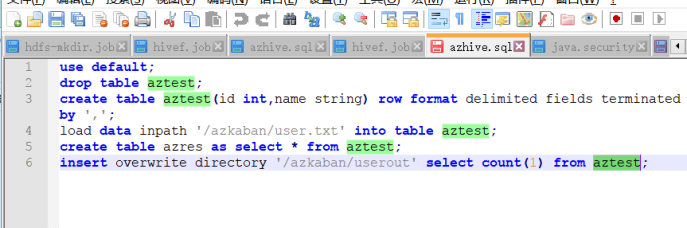
2:编写job文件
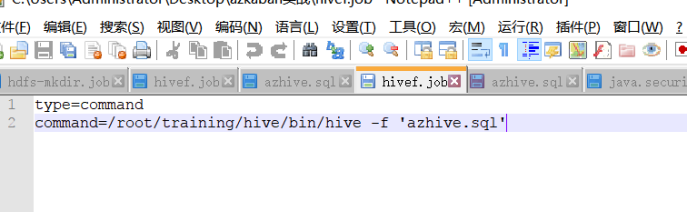
然后将这个job文件和sql文件打包成zip并上传到azkaban中。
这里有毒啊!!不知道为什么运行hive有问题
Execute报错信息

WebServer报错信息
