1.hashmap是按照存储结构来讲是数组(散列桶)与链表的组合体.

2. 如何计算hashmap中的散列桶的位置。
首先hashcode的值是用来辅助计算散列桶的位置的。如何散列有不同的算法,比如%或 & (散列桶的length-1)
hashmap内部实现会把hashcode的值通过移位等运算再加工一下,保证加工之后的值二进制串中的01分布更加均匀. 数组的index或散列桶的位置等于h & (length-1); 由于length初始值是16, 将来也是基于2的倍数进行自动扩展. 所以length - 1的binary形式一定是一堆1,然后做与运算的结果就是取优化后哈希值的低位
index一定会<=length-1. 正好做为数组的下标. 注意,通常根据hashcode计算散列桶的算法是%。
由于数组的长度默认是16,并且会以2的倍数resize,当数组变大之后,会将以前数组中的每个entry的key重新hash到新的数组里:index=h & (newlength-1)
3.与运算会将计算出的哈希值转换成正的吧?上面有提到过溢出的问题,这样可能会导致二进制符号位为1,得出的值是负数
->HashMap的代码实现,里面的MAX_CAPACITY是Integer Max Value的一半,也就是低位的部分不可能出现在符号位上
注:int是32位,通常最左边的位是符号位. 如果数组的容量length最大的值才是Integer Max Value的一半,那么与之后不会肯定影响到符号位的值.
4.字符串如何计算hashcode
for (int i = 0; i < len; i++) {
h = 31*h + val[off++];
}
如果h的值随着字符串的增长而超过32整型的值. 不管它如何增大,它只取32位(即使超过32位),所以说会出现负数(超过32位时,32位应该是1. 这样截取之后,首位是1就会表示负数)。 hashcode的范围就是一个int的范围-2^32到2^31 5.
5. 散列的目的是索引化访问
如果一个map使用array来实现,第一个array里面存放key,第二个存放value,k-v的index一致。这样的存储结构,如果要去匹配某个key,需要遍历key array的元素,才能找到。这样查找的效率与array的长度成反比。散列表的出现就是在速度与存储空间找到一个平衡并且每次查找的时间是恒定的, 散列表的目的就象通过index访问array那样,将一切索引化。比如通过hashcode去定位散列桶。散列桶中的元素有可能冲突。hashmap的解决是继续通过equal去比较冲突的元素是否相等。
又例如hashmap的数组位置是0~7。又假如要把某个类的实例存放在以上8个位置中,如果不用hashcode而任意存放,那么当查找时就需要到每个位置去找。 假如类中字段ID,如果hash算法是hashcode=ID%8,以后在查找该类时就可以通过ID除8 求余数直接找到存放的位置。 但是如果两个类的实例的hashcode被散列到同一个桶,例如9除以8和17除以8的余数都是1,这时9和17就存在冲突,这时就需要equals去进一步比较冲突的元素是否相等。
hashcode来定位实例的散列桶位置然后再通过 equals判断该桶里面的元素是否逻辑相等。
所以二者的用途一定要区分:equals是用来判断是否逻辑相等。hashCode是与hashset,hashtable,hashmap之类的数据结构使用时,用来快速定位散列桶。
6.数据结构get/add与hashcode和equal
6.1 HashSet
对于Set接口的实现类HashSet,它是按照哈希算法来存取集合中的对象,并且因为其继承了Set接口,所以不允许加入相同的元素,这就要使用到equals()和hashCode()方法了。在往HashSet里面添加对象的时候,在Add()的方法内部,它首先调用该对象的hashCode()方法,如果返回的哈希码与集合已存在对象的哈希码不一致(HashMap会缓存放入元素的hashcode值,方便比较,HashSet有可能一样,如果存在一样的hashcode,add失败,直接返回),则add()方法认定该对象没有与集合中的其它对象重复,那么该对象将被添加进集合中。如果hashCode()方法返回的哈希码与集合已存在对象的哈希码一致,那么将调用该对象的equals方法,进一步判断其是否为同一对象(根据java规范,并不强制不相等的二个对象拥有不相等的hashcode,这样就导致不相等的二个对象可能存在一样的hashcode,所以,倒过来,先判断hashcode相等并不能决定二个对象也一定相等,所以,还需要进一步判断equal来决定,以便add即使hashcode相同,但是equal不同的元素到hashset里).
6.2 HashMap 具体可以参考effective java 39~40
hashmap的contains方法与get类似,在使用contains之前,先检查元素的类里面是否实现了hashcode,equal方法。下面的示例中equal中使用id去判断是否相等,hashcode里面一样,也只能使用id去生成。尽量使hashcode里面的元素与equal里面的元素一致。 具体原因可以参考effective java 39~41. 下面示例中直接使用id是因为从第三方调用返回的数据都有id值,并不是需要保存后才会生成id的场景。后一种就不能使用id去判断了。
@Override
public int hashCode()
{
final int prime = 31;
int result = 1;
result = prime * result + ((m_sId == null) ? 0 : m_sId.hashCode());
return result;
}
@Override
public boolean equals(Object obj)
{
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
SNSProfile other = (SNSProfile) obj;
if (m_sId == null)
{
if (other.m_sId != null)
return false;
}
else if (!m_sId.equals(other.m_sId))
return false;
return true;
}
7.String 类的hashcode的生成函数中
for (int i = 0; i < len; i++) { h = 31*h + val[off++]; }
为什么要用31×h,这个数字是怎么算出来的或者说用31有什么好处
->
这 种方法HashCode的计算方法可能最早出现在Brian W. Kernighan和Dennis M. Ritchie的《The C Programming Language》中,被认为是性价比最高的算法(又被称为times33算法,因为C中乘数常量为33,JAVA中改为31),实际上,包括List在 内的大多数的对象都是用这种方法计算Hash值。
9.hashmap的容量是按照2的次方增长,所以length-1的二进制值都是1.
8.resize中的transfer方法
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
for (int j =0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e !=null) {
src[j] =null;
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);
//将newTable[i]的引用(C里面的指针)赋给了e.next。也就是使用了单链表的头插入方式(还有种是在尾插入方式)
e.next = newTable[i];
newTable[i] = e;//将e插入后做为第一个节点。上一步e.next的指向是旧的第一个节点。
e = next;
} while (e !=null);
}
}
}
HashMap与LinkedHashMap的区别:LinkedHashMap中的key是按照插入的顺序排序。不象HashMap的key是无序的。主要用在有序访问map的场景
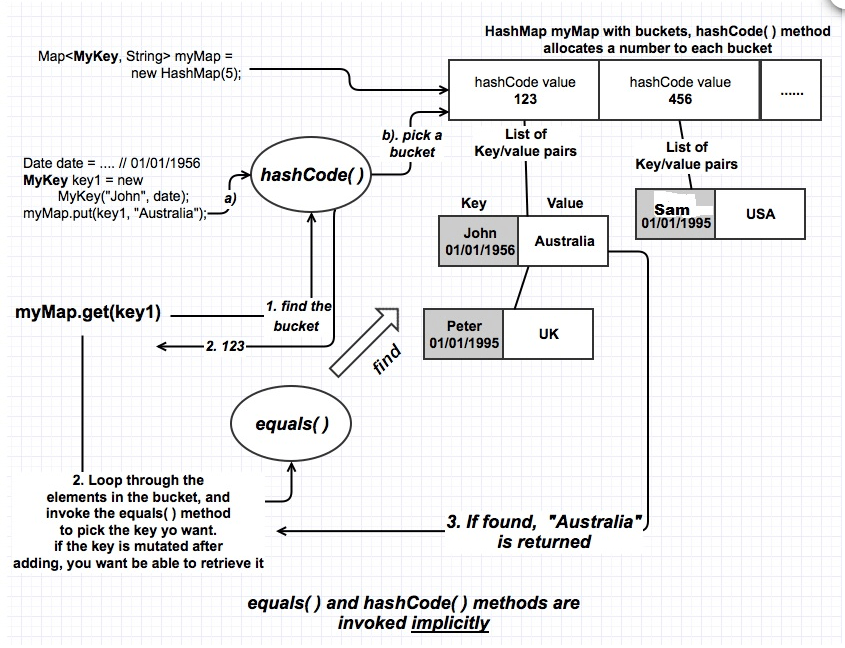
Hashmap是在性能与存储找到了一个平衡
参考 http://www.iteye.com/topic/838030