评估方法
当我们只有一个数据集(D)时,为了让模型有更好的泛化能力,我们不能用训练集中的数据作为测试集来评估模型的好坏,而是要将数据集进行处理。以下是一些常用处理方式
1. 留出法
直接将数据集(D)划分为两个互斥的数据集,分别时训练集(E)和测试集(T)。为了尽量保证两个数据集有相同的分布,需要采用“分层采样”来选取测试集(T)。由于采样的随机性,单次评估结果不够稳定可靠,因此可以进行若干次采样和评估,使用平均值作为最终的评估结果。
利弊
- 如果选择较小的(T),那么评估结果就不稳定准确
- 如果选择较大的(T),那么训练集(S)训练出的模型和用(D)训练出的模型可能相差较大,从而降低评估结果的保真性
为了平衡以上两个点,一般将2/3~4/5的样本作为训练集,剩下的用于测试。
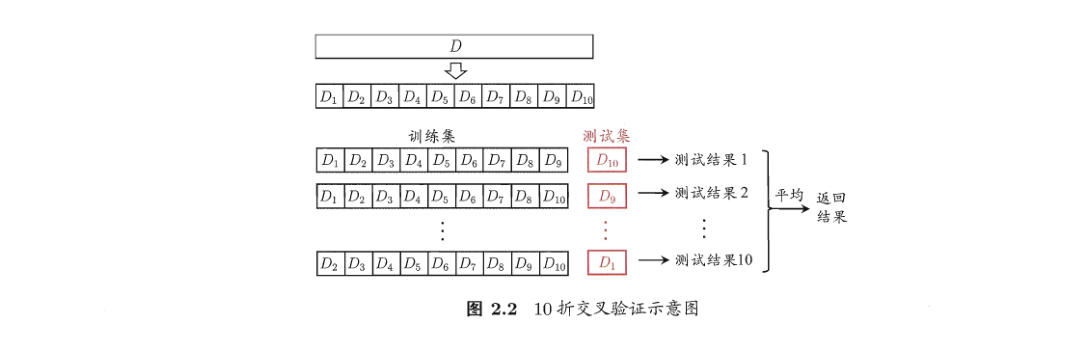
2. 交叉验证法
交叉验证法(cross validation)也被称为k折交叉验证(k-fold cross validation)。将数据集(D)划分为(k)个大小类似的互斥子集,并且每个子集尽可能保持分布一致。然后每次抽一个出来作为测试集,剩下的作为训练集,将每次训练的测试结果取均值作为最终的评估结果。常用的(k)值为5、10、20。
留一法
数据集(D)的样本数为(m),如果取(k=m),就是一个特例,被称为留一法(Leave-One-Out)LOO。每次只有一个样本作为测试集,这对保真性影响非常小,但是需要同时训练(m)个模型,当(m)非常大时计算开销难以接受。
3. 自助法
从数据集(D)中随机挑选一个样本复制到(D'),直到(D')的样本数达到(m)。使用(D')作为训练集,(D setminus D')(差集)作为测试集。
这样可以保证有(m)个训练集,并且测试集又没有出现在训练集中,测试集的期望大小约是(0.368*m)。
[lim_{m o infty}(1-frac{1}{m})^m o frac{1}{e} approx 0.368
]