千里之行,始于足下。把别人的变成自己,再把自己的分享给别人,这也是一次提升的过程。本文的目的是以一篇文章从整体把握集合体系又不失一些细节上的实现,高手路过。
集合的作用与特点
Java是一门面向对象语言,数据多了用对象封装存储(比如,人有姓名、年龄、性别等数据信息,我们就抽象一个Person对象来封装存储),对象多了又用什么来存储呢?集合,集合就是用来存储对象的。
集合的特点就是适用于存储对象而且可以存储不同类型的对象,集合的长度是可变的。
集合框架图
集合既然能存储不同类型的的对象,那么集合体系中肯定有不同类型的容器,集合中主要有List、Set、Map三种容器,每种容器的数据结构都不一样。集合体系的类、接口非常多,方便记忆,我们将下面这个相对简洁的集合框架图分为从5个模块来学习:
1.Collection集合
2.Map集合
3.集合遍历
4.集合比较
5.集合工具类

先对图做一下解析:
l 点线框表示接口
l 实现框表示具体的类
l 带有空心箭头的点线表示一个具体的类实现了一个接口
l 实心箭头表示某一个类可以生成箭头所指向的类
l 常用的容器用黑色粗线表示
Collection集合
Collection接口
Collection是一个接口,是高度抽象出来的集合,包含了集合的基本操作:添加、删除、清空、遍历、是否为空、获取大小等等。定义如下:
public interface Collection<E> extends Iterable<E> {}
Collection接口下主要有两个子接口:List和Set。
List接口
List是Collection的一个子接口,List中的元素是有序的,可以重复,有索引。
定义如下:
public interface List<E> extends Collection<E> {}

List是继承于Collection接口,它自然就包含了Collection中的全部函数接口,由于List有自己的特点(素是有序的,可以重复,有索引),因此List也有自己特有的一些操作,如上红色框框中的。List特有的操作主要是带有索引的操作和List自身的迭代器(如上图)。List接口的常用实现类有ArrayList和LinkedList。
ArrayList
ArrayList是List接口的一个具体的实现类。ArrayList的底层数据结构是数组结构,相当于一个动态数组。ArrayList的特点是随机查询速度快、增删慢、线程不安全。ArrayList和Vector的区别是:Vector是线程安全的(synchronized实现)。定义如下:
public class ArrayList<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable {}
l ArrayList 继承AbstractList,AbstractList是对一些公有操作的再次抽象,抽出一些特性操作,如根据索引操作元素,生产迭代器等。
l ArrayList 实现了RandmoAccess接口,即提供了随机访问功能,可以通过元素的索引快速获取元素对象。
l ArrayList 实现了Cloneable接口,即覆盖了函数clone(),能被克隆。
l ArrayList 实现java.io.Serializable接口,这意味着ArrayList支持序列化,能通过序列化去传输。
ArrayList源码分析总结(源码略,建议先整体认识再打开源码对着看):
l 可以通过构造函数指定ArrayList的容量大小,若不指定则默认是10。
l 添加新元素时,容量不足以容纳全部元素时,会重新创建一个新的足以容纳全部元素的数组,把旧数组中的元素拷贝到新的数组中并返回新的数组。增量具体看源码。
l 添加的新元素添加到数组末尾。
l 查找、删除元素使用equals方法比较对象。
l ArrayList的克隆函数,即是将全部元素克隆到一个数组中。
l ArrayList的序列化,即通过java.io.ObjectOutputStream将ArrayList的长度和每一个元素写到输出流中,或者通过java.io.ObjectInputStream从输入流中读出长度和每一个元素到一个数组中。
LinkedList
LinkedList是List接口的一个具体的实现类。LinkedList底层数据结构是双向的链表结构,可以当成堆栈或者队列来使用。LinkedList的特点是增删速度很快,顺序查询效率较高,随机查询稍慢。定义如下:
public class LinkedList<E> extends AbstractSequentialList<E> implements List<E>, Deque<E>, Cloneable, java.io.Serializable {}
l LinkedList 是继承AbstractSequentialList,AbstractSequentialList是AbstractList的一个子类。
l LinkedList 实现 Deque 接口,即能将LinkedList当作双端队列使用。
l 同ArrayList,LinkedList同样支持克隆和序列化。
LinkedList 源码分析总结(源码略,建议先整体认识再打开源码对着看):
l LinkedList的本质是一个双向链表,各有一个头节点和尾节点,每一个节点都有个数据域、一个指向上一个节点的指针域、一个指向上下一个节点的指针域。
l 添加元素时,将元素添加到双向链表的末端。
l 查找、删除元素时,使用equals方法比较对象。
l 根据索引查找元素时,若索引值index < 双向链表长度的1/2,则从表头往后查找,否则从表尾往前找。
l LinkedList的克隆和序列化原理同ArrayList。
l LinkedList实现了Deque,Deque接口定义了在双端队列两端访问元素的方法,每种方法都存在两种形式:一种是在操作失败时抛出异常,另一种是返回一个特殊值(null 或 false)。
l LinkedList有自己特有的迭代器ListIterator。
l LinkedList不存在扩容增量的问题。
List应用举例
LinkedList实现堆栈和队列
LinkedList可以当成堆栈和队列使用,因为实现了Deque接口,Deque接口提供了一些了出栈入栈和出队入队的方法。


class MyQueueStack { private LinkedList link; MyQueueStack() { link = new LinkedList(); } public void add(Object obj) { link.addFirst(obj); } public Object remove() { //return link.removeLast();//队列 return link.removeFirst();//栈 } public boolean isNull() { if(!link.isEmpty()) { return false; } return true; } } public class LinkedListQueueStack { public static void main(String[] args) { MyQueueStack q = new MyQueueStack(); q.add("001"); q.add("002"); q.add("003"); while(!q.isNull()) System.out.println(q.remove()); } } 队列运行结果: 001 002 003 栈运行结果: 003 002 001
ArrayList保证唯一性
List中的元素是可以重复的,可以通过重写equals方法实现唯一性。下面是ArrayList实现元素去重(依据equals)的一个例子。
class Teacher { private String name; private String age; Teacher(String name,String age) { this.name = name; this.age = age; } public String getName() { return name; } public void setName(String name) { this.name = name; } public String getAge() { return age; } public void setAge(String age) { this.age = age; } @Override public boolean equals(Object obj) { if(!(obj instanceof Teacher)) { return false; } Teacher p = (Teacher)obj; System.out.println("调用equals比较" + p.name + "与" + this.name); return p.name.equals(this.name) && p.age.equals(this.age); } } public class ArrayListDuplicate { public static void main(String[] args) { ArrayList al = new ArrayList(); al.add(new Teacher("zhangsan","20")); al.add(new Teacher("lingsi","21")); al.add(new Teacher("wangwu","22")); al.add(new Teacher("wangwu","22")); print("-----------原始ArrayList----------"); Iterator it = al.iterator(); while(it.hasNext()) { Teacher obj = (Teacher)it.next(); print(obj.getName() + "-" + obj.getAge()); } print("-----------删除重复元素----------"); ArrayList al2 = removeSameObj(al); Iterator it2 = al2.iterator(); while(it2.hasNext()) { Teacher obj = (Teacher)it2.next(); print(obj.getName() + "-" + obj.getAge()); } print("-----------删除lingsi元素----------"); al2.remove(new Teacher("lingsi","21")); Iterator it3 = al2.iterator(); while(it3.hasNext()) { Teacher obj = (Teacher)it3.next(); print(obj.getName() + "-" + obj.getAge()); } } public static ArrayList removeSameObj(ArrayList al) { ArrayList newAl = new ArrayList(); Iterator it = al.iterator(); while(it.hasNext()) { Object obj = it.next(); if(!newAl.contains(obj)) { newAl.add(obj); } } return newAl; } public static void print(Object obj) { System.out.println(obj); } } 运行结果: -----------原始ArrayList---------- zhangsan-20 lingsi-21 wangwu-22 wangwu-22 -----------删除重复元素---------- 调用equals比较zhangsan与lingsi 调用equals比较zhangsan与wangwu 调用equals比较lingsi与wangwu 调用equals比较zhangsan与wangwu 调用equals比较lingsi与wangwu 调用equals比较wangwu与wangwu zhangsan-20 lingsi-21 wangwu-22 -----------删除lingsi元素---------- 调用equals比较zhangsan与lingsi 调用equals比较lingsi与lingsi zhangsan-20 wangwu-22
从运行结果中可以看出,调用list的contains方法和remove方法时,调用了equals方法进行比较(List集合中判断元素是否相等依据的是equals方法)。
Set接口
Set是Collection的一个子接口,Set中的元素是无序的,不可以重复。定义如下:
public interface Set<E> extends Collection<E> {}
Set是继承于Collection接口,它自然就包含了Collection中的全部函数接口。Set接口的常用实现类有HashSet和TreeSet。实际上HashSet是通过HashMap实现的,TreeSet是通过TreeMap实现的。在此只简要列举它们的一些特点,可以直接看下面的HashMap和TreeMap的分析,理解了HashMap和TreeMap,也就理解了HashSet和TreeSet。
HashSet
HashSet是Set接口的一个具体的实现类。其特点是元素是无序的(取出顺序和存入顺序不一定一样),不可以重复。定义如下:
public class HashSet<E> extends AbstractSet<E> implements Set<E>, Cloneable, java.io.Serializable {}
l HashSet继承AbstractSet,AbstractSet抽象了equals()、hashCode()、removeAll()三个方法。
l HashSet实现了Cloneable,Serializable接口以便支持克隆和序列化。
l HashSet保证元素唯一性依赖equals()方法和hashCode()方法。
TreeSet
TreeSet是Set接口的一个具体的实现类。其特点是元素是有序的,不可以重复。定义如下:
public class TreeSet<E> extends AbstractSet<E> implements NavigableSet<E>, Cloneable, java.io.Serializable {}
l TreeSet继承AbstractSet,AbstractSet抽象了equals()、hashCode()、removeAll()三个方法。
l TreeMap实现了NavigableMap接口,支持一系列的导航方法,比如返回有序的key集合。
l TreeSet实现了Cloneable,Serializable接口以便支持克隆和序列化。
l TreeSet保证元素唯一性依赖Comparator接口和Comparable接口。
Map集合
Map接口
不同于List和Set,集合体系中的Map是“双列集合”,存储的是内容是键值对(key-value),Map集合的特点是不能包含重复的键,每一个键最多能映射一个值。Map接口抽象出了基本的增删改查操作。定义如下:
public interface Map<K,V> {}
主要方法
/**添加**/ V put(K key, V value); void putAll(Map<? extends K, ? extends V> m); /**删除**/ void clear(); V remove(Object key); /**判断**/ boolean isEmpty(); boolean containsKey(Object key); boolean containsValue(Object value); /**获取**/ int size(); V get(Object key); Collection<V> values(); Set<K> keySet(); Set<Map.Entry<K, V>> entrySet();
Map接口的主要实现类有HashMap和TreeMap。
HashMap
HashMap是Map接口的一个实现类,它存储的内容是键值对(key-value)。HashMap的底层是哈希表数据结构,允许存储null的键和值,同时HashMap是线程不安全的。HashMap与HashTable的区别是:HashTable不可以存储null的键和值,HashTable是线程安全的(synchronized实现)。
哈希表的定义:给定表M,存在函数f(key),对任意给定的关键字值key,代入函数后若能得到包含该关键字的记录在表中的地址,则称表M为哈希(Hash)表,函数f(key)为哈希(Hash) 函数。通过把关键字值key映射到哈希表中的一个位置来访问记录,以加快查找的速度。
HashMap定义如下:
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable {}
l HashMap继承AbstractMap,AbstractMap抽象了Map集合的一些基本操作。
l HashMap实现了Cloneable,Serializable接口以便支持克隆和序列化。
HashMap源码分析总结(源码略,建议先整体认识再打开源码对着看):
l HashMap的几个重要成员:table, DEFAULT_INITIAL_CAPACITY ,MAXIMUM_CAPACITY ,
size, threshold, loadFactor, modCount。
(1)table是一个Entry[]数组类型,Map.Entry是一个Map接口里的一个内部接口。而Entry实际上就是一个单向链表,也称为HashMap的“数组+链式存储法”,链式存储是为了解决哈希冲突而存在。HashMap的键值对就是存储在Entry对象中(一个Entry对象包含一个key、一个value、key对应的hash和指向下一个Entry的对象)。
(2)DEFAULT_INITIAL_CAPACITY是默认的初始容量是16。
(3)MAXIMUM_CAPACITY, 最大容量(初始化容量大于这个值时将被这个值替换)。
(4)size是HashMap的大小,保存的键值对的数量。
(5)threshold是HashMap的阈值,用于判断是否需要调整HashMap的容量。threshold的值="容量*加载因子",当HashMap中存储数据的数量达到threshold时,就需要将HashMap进行rehash 操作(即重建内部数据结构)是容量*2。
(6)loadFactor就是加载因子。
(7)modCount是记录HashMap被修改的次数。
l table分配空间。不同版本略有差异。在1.6的源码中,为table分配空间是在HashMap的构造函数中,而1.7的中,则在put的时候先判断table是否为空,为空则分配空间。
l get(Object key)。先计算key的hash,根据hash计算索引,根据索引在table数组中查找出对应的Entry,返回Entry中的value。
l put(K key, V value)。若key为null,则创建一个key为null的Entry对象并存储到table[0]中。否则计算其hash以及索引i,创建一个键值对和哈希值分别为key、value、hash的Entry对象并存储到table[i]中(若table[i]处为空即没有Entry链表则直接存入,否则将Entry对象添加到table[i]处的Entry链表的表头中)。需要注意的是,如果该hash已经存在Entry链表中,则用新的value取代旧的value并返回旧的value。
l putAll(Map<? extends K, ? extends V> m)。当当前实际容量小于需要的容量,则将容量*2。调用put()方法逐个添加到HashMap中。
l remove(Object key)。计算key的hash以及索引i,根据索引在table数组中查找出对应的Entry,从Entry链表删除对应的Entry节点,期间会比较hash和key(equals判断)来判断是否是要删除的节点。
l clear()。把每一个table[i]设置为null。
l Entry类中重写了equals()方法和hashCode()来判断两个Entry是否相等。
l containsKey(Object key)。比较hash和key(equals判断)来判断是否是包含该key。
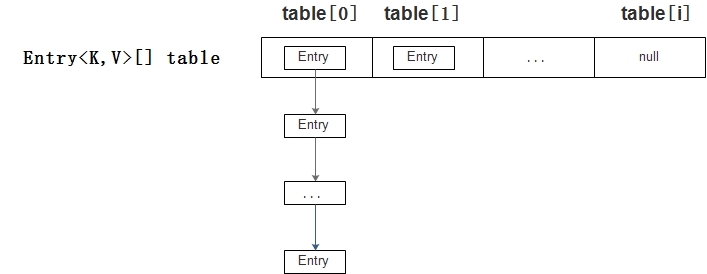
HashMap内存结构示意图
HashMap举例
通过keyset遍历
public class HashMapTest { public static void main(String[] args) { HashMap<String,String> map = new HashMap<String,String>(); map.put("001", "zhangsan1"); map.put("002", "zhangsan2"); map.put("003", "zhangsan3"); map.put("004", "zhangsan4"); Set<String> keySet = map.keySet(); Iterator<String> it = keySet.iterator(); while(it.hasNext()) { String obj = (String)it.next(); System.out.println(obj + "-" + map.get(obj)); } } } 运行结果: 004-zhangsan4 001-zhangsan1 002-zhangsan2 003-zhangsan3
通过entrySet遍历
public class HashMapTest { public static void main(String[] args) { HashMap<String,String> map = new HashMap<String,String>(); map.put("001", "zhangsan1"); map.put("002", "zhangsan2"); map.put("003", "zhangsan3"); map.put("004", "zhangsan4"); Set<Entry<String, String>> se = map.entrySet(); Iterator<Entry<String, String>> it = se.iterator(); while(it.hasNext()) { Entry<String, String> en = (Entry<String, String>)it.next(); System.out.println(en.getKey() + "-" + en.getValue()); } } } 运行结果: 004-zhangsan4 001-zhangsan1 002-zhangsan2 003-zhangsan3
TreeMap
TreeMap是Map接口的一个实现类,因此它存储的也是键值对(key-value)。TreeMap的底层数据结构是二叉树(红黑树),其特点是可以对元素进行排序,TreeMap是线程不安全的。定义如下:
public class TreeMap<K,V> extends AbstractMap<K,V> implements NavigableMap<K,V>, Cloneable, java.io.Serializable {}
l TreeMap继承AbstractMap,AbstractMap抽象了Map集合的一些基本操作。
l TreeMap实现了NavigableMap接口,支持一系列的导航方法,比如返回有序的key集合。
l TreeMap实现了Cloneable,Serializable接口以便支持克隆和序列化。
TreeMap源码分析总结(源码略,建议先整体认识再打开源码对着看):
l TreeMap的几个重要成员:root, size, comparator。
(1)root是红黑树的根节点,它是Entry类型,Entry是红黑数的节点,它包含了红黑数的6个基本组成成分:key(键)、value(值)、left(左孩子)、right(右孩子)、parent(父节点)、color(颜色)。Entry节点根据key进行排序,Entry节点包含的内容为value。
(2)comparator是比较器,使红黑树的节点具有比较性,用来给TreeMap排序。红黑数排序时,根据Entry中的key进行排序,Entry中的key比较大小是根据比较器comparator来进行判断的。
(3)size是红黑树节点的个数。
l TreeMap(Comparator<? super K> comparator)。带比较器的构造函数可以在TreeMap外部自定义TreeMap元素(红黑树节点)的比较器。
l get(Object key)。若比较器comparator不为空(即通过构造函数外部传入的),则通过Comparator接口的compare()方法从根节点开始和key逐个比较直到找出相等的节点。若比较器为空,则使用Comparable接口的compareTo()比较查找。
l put(K key, V value)。若根节点root为空,则根据key-value创建一个Entry对象插入到根节点。否则在红黑树中找到找到(key, value)的插入位置。查找插入位置还是若比较器comparator不为空则通过Comparator接口的compare()方法比较查找,否则通过Comparable接口的compareTo()方法比较查找。过程比较复杂。
l putAll(Map<? extends K, ? extends V> map)。调用AbstractMap中的putAll(),AbstractMap中的putAll()又会调用到TreeMap的put()。
l remove(Object key)。先根据key查找出对应的Entry,从红黑树中删除对应的Entry节点。
l clear()。clear把根节点设置为null即可。
l containsKey(Object key)。判断是否是包含该key的元素,查找方法同get()。
TreeMap举例
public class TreeMapTest { public static void main(String[] args) { System.out.println("---TreeMap默认按key升序排序---"); TreeMap<Integer,String> map = new TreeMap<Integer,String>(); map.put(200,"sha"); map.put(300,"can"); map.put(100,"pek"); map.put(400,"szx"); Set<Entry<Integer,String>> se = map.entrySet(); Iterator<Entry<Integer,String>> it = se.iterator(); while(it.hasNext()) { Entry<Integer,String> en = (Entry<Integer,String>)it.next(); System.out.println(en.getKey() + "-" + en.getValue()); } System.out.println("---TreeMap使用自定义比较器降序排序---"); TreeMap<Integer,String> map2 = new TreeMap<Integer,String>(new CityNumComparator()); map2.put(200,"sha"); map2.put(300,"can"); map2.put(100,"pek"); map2.put(400,"szx"); Set<Entry<Integer,String>> se2 = map2.entrySet(); Iterator<Entry<Integer,String>> it2 = se2.iterator(); while(it2.hasNext()) { Entry<Integer,String> en = (Entry<Integer,String>)it2.next(); System.out.println(en.getKey() + "-" + en.getValue()); } } } class CityNumComparator implements Comparator { @Override public int compare(Object o1, Object o2) { if(!(o1 instanceof Integer) || !(o2 instanceof Integer)) { throw new RuntimeException("不可比较的对象"); } Integer num1 = (Integer)o1; Integer num2 = (Integer)o2; if(num1 < num2) { return 1; } if(num1 > num2) { return -1; } return 0; //Integer类型自身已经自有比较性,或者 //return num2.compareTo(num1); } } 运行结果: ---TreeMap默认按key升序排序--- 100-pek 200-sha 300-can 400-szx ---TreeMap使用自定义比较器降序排序--- 400-szx 300-can 200-sha 100-pek
由此可见,要想按照自己的方式对TreeMap进行排序,可以自定义比较器重写compare()方法重写自己的比较逻辑。
集合遍历
迭代器的设计原理
在上面List和Map的分析和举例中,已经提到迭代器了。因为每一种容器的底层数据结构不同,所以迭代的方式也不同,但是也有共同的部分,把这些共同的部分再次抽象,Iterator接口就是迭代器的顶层抽象。
List集合中有自己特有的迭代器ListIterator,ListIterator接口是Iterator接口的子接口。实现类ArrayList和LinkedList中有迭代器的具体实现(内部类)。把迭代器设计在集合的内部,这样,迭代器就可以轻松的访问集合的成员了。
private class ListItr extends Itr implements ListIterator<E>{}
而在HashMap和TreeMap的遍历中,我们经常将Map的键存到Set集合中,Set属于List的子接口,当然也继承了List特有的迭代器,通过迭代key来获取value。另一种方式是将Map中的映射关系Entry取出存储到Set集合,通过迭代每一个映射Entry关系获取Entry中的key和value。可以说,Map是借List的迭代器实现了对自身的遍历。
集合遍历效率总结
l ArrayList是数组结构,ArrayList常用遍历有for循环(索引访问)、增强for循环、迭代器迭代。其中按索引访问效率最高,其次是增强for循环,使用迭代器的效率最低。
(1)按索引访问时间复杂度为O(1),即一次定位寻址即可。
(2)查找某一个值,需要遍历数组逐个对比,时间复杂度为O(n),即需要对比n次。
(3)对于二分查找(元素有序是前提)时间复杂度为O(logn)。
(4)对于插入和删除,因为涉及到元素移动的问题,时间复杂度也为O(n)。
l LinkedList是链表结构,常用遍历也有for循环(索引访问)、增强for循环、迭代器迭代。建议不要采用随机访问的方式去遍历LinkedList,而采用逐个遍历的方式。
(1)查找某一个值,需要遍历链表逐个对比,时间复杂度为O(n)。
(2)对于插入、删除等操作,由于只需要改变前后节点之间的指针,时间复杂度为O(1)。
l HashMap是“数组+链表”的结构。其遍历方式也很多,可以通过keyset遍历、通过entrySet遍历、通过Map.values()遍历(这种方式只能获得value)。
(1)如果table[i]处没有链表,对于查找一次定位,时间复杂度为O(1),对于增加、删除,本质上也是对链表的增加、删除(可以理解table[i]处是只有一个节点的链表),所以时间复杂度为O(1)。
(2)如果table[i]处有链表,查找时需要遍历链表,时间复杂度为O(n),增加、删除时间复杂度为O(1)。
l TreeMap是二叉树结构,可以通过keyset、entrySet等方式遍历。
(1)对于二叉树的遍历,给定某一个值,它会先和二叉树的root节点对比,如果值比root节点大则在右子树遍历,否则就在左子树遍历,以此类推。因此,对于查找、增加、删除等操作,都不会遍历完整棵树,平均复杂度均为O(logn)。
集合比较
Comparator与Comparable
在TreeMap的分析和举例中,我们提到了TreeMap中的元素排序比较采用的是Comparator接口的compare()方法和Comparable接口的compareTo()。当元素本身不具备比较性或者具备的比较性不满足我们的需求时,我们就可以使用Comparator接口或者Comparable接口来重写我们需要的比较逻辑。Comparator接口和Comparable接口实现比较的主要区别是:Comparator 是在元素外部实现的排序,这是一种策略模式,就是不改变元素自身,而用一个策略对象(自定义比较器)来改变比较行为。而Comparable接口则需要修改要比较的元素,让元素具有比较性,在元素内部重新修改比较行为。看下面的两个列子。
让元素具有比较性
//实现Comparable接口强制让Passenger对象具有可比性 class Passenger implements Comparable { private String name; private int age; Passenger(String name,int age) { this.name = name; this.age = age; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } @Override public int compareTo(Object obj) { if(!(obj instanceof Passenger)) { return -1; } Passenger p = (Passenger)obj; System.out.println("调用compareTo比较"+ p.name + "与" + this.name); if(this.age> p.age) { return 1; } if(this.age == p.age) { return this.name.compareTo(p.name); } return -1; } } public class TreeSetTest { public static void main(String[] args) { TreeSet ts = new TreeSet(); print("-----------添加元素到TreeSet----------"); ts.add(new Passenger("zhangsan",20)); ts.add(new Passenger("lingsi",21)); ts.add(new Passenger("wangwu",22)); ts.add(new Passenger("wangwu",22)); Iterator it = ts.iterator(); while(it.hasNext()) { Passenger obj = (Passenger)it.next(); print(obj.getName() + "-" + obj.getAge()); } } public static void print(Object obj) { System.out.println(obj); } } 运行结果: -----------添加元素到TreeSet---------- 调用compareTo比较zhangsan与zhangsan 调用compareTo比较zhangsan与lingsi 调用compareTo比较zhangsan与wangwu 调用compareTo比较lingsi与wangwu 调用compareTo比较lingsi与wangwu 调用compareTo比较wangwu与wangwu zhangsan-20 lingsi-21 wangwu-22
上面的例子中,Passenger本身并不具备比较性,但是通过修改Passenger,让其实现了Comparable 接口重写了compareTo()方法让其根据年龄具有比较性。
自定义比较器
public class TreeSetTest2 { public static void main(String[] args) { TreeSet ts = new TreeSet(new MyComparator()); print("-----------添加元素到TreeSet----------"); ts.add(new Passenger("zhangsan",20)); ts.add(new Passenger("lingsi",21)); ts.add(new Passenger("wangwu",22)); ts.add(new Passenger("chenliu",23)); Iterator it = ts.iterator(); while(it.hasNext()) { Passenger obj = (Passenger)it.next(); print(obj.getName() + "-" + obj.getAge()); } } public static void print(Object obj) { System.out.println(obj); } } class MyComparator implements Comparator { @Override public int compare(Object o1, Object o2) { if(!(o1 instanceof Passenger) || !(o2 instanceof Passenger)) { throw new RuntimeException("不可比较的对象"); } Passenger p1 = (Passenger)o1; Passenger p2 = (Passenger)o2; System.out.println("调用compare比较"+ p1.getName() + "与" + p2.getName()); if(p1.getAge() > p2.getAge()) { return 1; } if(p1.getAge() < p2.getAge()) { return -1; } return 0; } } 运行结果: -----------添加元素到TreeSet---------- 调用compare比较zhangsan与zhangsan 调用compare比较lingsi与zhangsan 调用compare比较wangwu与zhangsan 调用compare比较wangwu与lingsi 调用compare比较chenliu与lingsi 调用compare比较chenliu与wangwu zhangsan-20 lingsi-21 wangwu-22
从上面的例子可以看出,Passenger本身并不具备比较性,我们也没有修改Passenger,而是在外部自定义一个比较器,传入TreeSet中,使得TreeSet中存储的Passenger具有了比较性。
集合工具类
Collections
Collections是一个工具类,提供了操作集合的常用方法:
<!--排序, 对list中元素按升序进行排序,list中的所有元素都必须实现 Comparable 接口--> void sort(List<T> list) <!--混排,打乱list中元素的顺序--> void shuffle(List<?> list) <!--反转,反转list中元素的顺序--> void reverse(List<?> list) <!--使用指定元素替换指定列表中的所有元素--> void fill(List<? super T> list, T obj) <!-- 将源list中的元素拷贝到目标list--> void copy(List<? super T> dest, List<? extends T> src) <!-- 返回集合中最小的元素--> T min(Collection<? extends T> coll) <!-- 返回集合中最大的元素--> T max(Collection<? extends T> coll)
Collections举例
public class CollectionsTest { public static void main(String[] args) { ArrayList al = new ArrayList(); al.add("zhangsan"); al.add("lisi"); al.add("wangwu"); System.out.println("集合未排序前"); System.out.println(al); System.out.println("使用Collections.sort()方法自然排序"); Collections.sort(al); System.out.println(al); System.out.println("使用Comparator按长度自定义排序"); Collections.sort(al,new StringLengthComparator()); System.out.println(al); System.out.println("al中最长的元素"); System.out.println(Collections.max(al,new StringLengthComparator())); System.out.println("已排序的前提下,wangwu元素下标索引"); System.out.println(Collections.binarySearch(al, "wangwu")); System.out.println("逆序"); Collections.reverse(al); System.out.println(al); } } class StringLengthComparator implements Comparator<String> { @Override public int compare(String o1, String o2) { if(o1.length() > o2.length()) return 1; if(o1.length() < o2.length()) return -1; return 0; } } 运行结果: 集合未排序前 [zhangsan, lisi, wangwu] 使用Collections.sort()方法自然排序 [lisi, wangwu, zhangsan] 使用Comparator按长度自定义排序 [lisi, wangwu, zhangsan] al中最长的元素 zhangsan 已排序的前提下,wangwu元素下标索引 1 逆序 [zhangsan, wangwu, lisi]
Arrays
Arrays也是一个工具类,提供了操作数组以及在数组和集合之间转换的一些常用方法。
/**可以对各种类型的数组进行排序**/ void sort(Object[] a) /** 数组变集合**/ <T> List<T> asList(T... a) /** 数组转成字符串**/ String toString(Object[] a)
Arrays举例
public class ArraysTest { public static void main(String[] args) { String[] array = new String[]{"abc","def","hig"}; System.out.println(Arrays.toString(array)); List<String> list = Arrays.asList(array); System.out.println(list.contains("def")); //list.add("lmn");//UnsupportedOperationException int[] array2 = new int[]{1,2,3}; List<int[]> list2 = Arrays.asList(array2); System.out.println(list2); Integer[] array3 = new Integer[]{1,2,3}; List<Integer> list3 = Arrays.asList(array3); System.out.println(list3); } } 运行结果: [abc, def, hig] true [[I@36db4bcf] [1, 2, 3]
需要注意的是,将数组变成集合后,不能使用集合的增加或者删除方法,因此数组的长度是固定的,使用这些方法将会报UnsupportedOperationException异常。从上面的例子也可以看出,如果数组中的元素都是对象,那么转换成集合时,数组中的元素就直接转换成集合中的元素;如果数组中的元素是基本类型,那么整个数组将作为集合的元素存在。
小结
其实只要理解了集合体系各个主要实现类底层的数据结构类型,根据数据结构的特性,就能联想到该集合有什么特点,也很容易理解它们主要方法上的实现过程。文章主要介绍了常用的接口和实现类,还有很多没提到,通过集合框架图分模块记忆,整体把握,再根据需要扩展其它没提到的内容。