如果系统只有一个处理器,那么给定时刻只有一个程序可以运行。在多处理器系统中,真正并行运行的进程数目取决于物理CPU的数目。内核和处理器建立了多任务的错觉,是通过以很短的间隔在系统运行的应用程序之间不停切换做到的。由此,以下两个问题必须由内核解决:除非明确要求,否则应用程序不能彼此干扰;CPU时间必须在各种应用程序之间尽可能公平共享(一些程序可能比其他程序更重要)。本篇博文主要涉及内核共享CPU时间的方法以及如何在进程之间切换(内核为各进程分配时间,保证切换之后从上次撤销其资源时执行环境完全相同)。
一、进程优先级
并非所有进程的重要程度都相同,对于进程,首先比较粗糙的划分,进程可以分为实时进程和非实时进程。
- 硬实时进程:有严格的时间限制,某些任务必须在指定时限内完成。比如汽车的安全气囊,一旦发生碰撞,必须保证在一定时间内触发,超过时限则产生灾难性的后果。主流的Linux内核不支持实时处理,但有一些修改版本如RTLinux、Xenomai、RATI提供了这些特性,这些方案中,将Linux内核作为独立的“进程”运行处理次要软件,实时工作在Linux内核外部完成。
- 软实时进程:软实时进程是硬实时进程的一种弱化形式,优先于其他普通进程,稍微晚一点不会造成巨大影响。比如对CD的写入操作。
- 普通进程:没有特定时间约束的进程,可以根据重要性对其进行分配优先级。
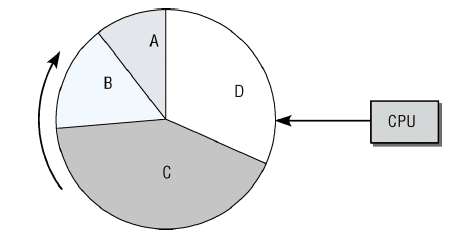
图1 通过时间片分配CPU时间调度示意图
图1是CPU分配时间的一个简图。进程运行按时间片调度,分配进程的时间片额与其相对重要性相当。系统中时间的流动对应于圆盘的转动,重要的进程会比次要的进程得到更多CPU时间,进程被切换时,所有的CPU寄存器内容和页表都会被保存,下次该进程恢复执行时,其执行环境可以完全恢复。这种简化模型忽略了一些进程状态相关的信息,不能使CPU时间利益回报尽可能最大化。但是为调度器的质量确立一种定量标准非常困难。自Linux内核诞生以来,调度器的代码已经重写了好几次。按时间先后顺序,主要有O(n)调度器,O(1)调度器和CFS(completely fair scheduler)调度器。详细区别戳这里。
二、进程生命周期
进程并不总是可以立即运行,有时候它需要等待来自外部信号源、不受其控制的事件(如文本编辑等待输入)。在调度器进行进程切换时,必须知道每个进程的状态,因为将CPU事件分配给无事可做的进程没有意义,进程在各个状态之间的转换也同样重要。
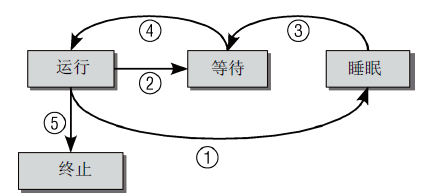
图2 进程状态之间的切换示意图
进程可能存在的状态有:运行、等待和睡眠。图2描述了进程的几种状态及其转换。除了图中所示的几种状态以外,还有一种状态被称为僵尸态。
- 运行:该进程正在运行。
- 等待(就绪):进程能够运行,但没有得到许可,因为CPU分配给了另一个进程。调度器可能在下一次任务切换时选择该进程。
- 睡眠:进程正在睡眠无法运行(“睡眠”状态有两种)。因为它在等待一个外部事件,调度器无法在任务切换时选择该进程。
- 僵尸:进程已经死亡,但是它的数据还没有从进程表中删除。(在UNIX操作系统下销毁进程需要两步,第一步由另一个进程或一个用户杀死(通过信号完成);第二步是进程的父进程在子进程终止时必须调用或已经调用wait4系统调用,使内核释放为子进程保留的资源。当条件一发生,第二个条件不成立的情况,便会出现“僵尸”状态)
为了维持系统中现存的各个进程,防止它们与系统其他部分相互干扰,Linux进程管理结构中还需要两种进程状态选项:用户状态和核心态。进程通常处于用户状态,只能访问自身的数据,无法干扰系统中其他进程。如果进程想要访问系统数据,则必须切换到核心态,这种访问必须经由明确定义的路径(系统调用)。从用户状态进入核心态的第二种方法是通过中断,此时切换是自动触发的,处理中断操作,通常与中断发生时执行的程序无关。(系统调用是由用户应用程序有意调用的,中断则是不可预测的)
内核的抢占调度模型是优先让优先级高的进程占用CPU,它建立了一个层次结构,用于判断哪些进程状态可由其他状态抢占。
- 普通进程总是可能被抢占,甚至由其他进程抢占。
- 如果系统处于核心态并正在处理系统调用,那么其他进程是无法夺取CPU时间的。
- 中断可以暂停处于用户态和和心态的进程,具有最高优先级。
在内核2.5开发期间,内核抢占(kernel preemption)选项被添加到内核,它支持紧急情况下切换到另一个进程,甚至当前进程处于系统调用也行。内核抢占可以减少等待时间,但代价是增加了内核的复杂度,因为抢占时有许多数据结构需要针对并发访问进行保护。
三、进程表示
Linux内核涉及进程和程序的所有算法都围绕数据结构task_struct建立,该结构定义在include/sched.h中。task_struct包含很多成员,将进程与各内核子系统联系起来。task_struct定义的简化版本如下:


1 struct task_struct { 2 volatile long state; /* -1表示不可运行,0表示可运行,>0表示停止 */ 3 void *stack; 4 atomic_t usage; 5 unsigned long flags; /* 每进程标志,下文定义 */ 6 unsigned long ptrace; 7 int lock_depth; /* 大内核锁深度 */ 8 int prio, static_prio, normal_prio; 9 struct list_head run_list; 10 const struct sched_class *sched_class; 11 struct sched_entity se; 12 unsigned short ioprio; 13 unsigned long policy; 14 cpumask_t cpus_allowed; 15 unsigned int time_slice; 16 #if defined(CONFIG_SCHEDSTATS) || defined(CONFIG_TASK_DELAY_ACCT) 17 struct sched_info sched_info; 18 #endif 19 struct list_head tasks; 20 /* 21 * ptrace_list/ptrace_children链表是ptrace能够看到的当前进程的子进程列表。 22 */ 23 struct list_head ptrace_children; 24 struct list_head ptrace_list; 25 struct mm_struct *mm, *active_mm; 26 /* 进程状态 */ 27 struct linux_binfmt *binfmt; 28 long exit_state; 29 int exit_code, exit_signal; 30 int pdeath_signal; /* 在父进程终止时发送的信号 */ 31 unsigned int personality; 32 unsigned did_exec:1; 33 pid_t pid; 34 pid_t tgid; 35 /* 36 * 分别是指向(原)父进程、最年轻的子进程、年幼的兄弟进程、年长的兄弟进程的指针。 37 *(p->father可以替换为p->parent->pid) 38 */ 39 struct task_struct *real_parent; /* 真正的父进程(在被调试的情况下) */ 40 struct task_struct *parent; /* 父进程 */ 41 /* 42 * children/sibling链表外加当前调试的进程,构成了当前进程的所有子进程 43 */ 44 struct list_head children; /* 子进程链表 */ 45 struct list_head sibling; /* 连接到父进程的子进程链表 */ 46 struct task_struct *group_leader; /* 线程组组长 */ 47 /* PID与PID散列表的联系。 */ 48 struct pid_link pids[PIDTYPE_MAX]; 49 struct list_head thread_group; 50 struct completion *vfork_done; /* 用于vfork() */ 51 int __user *set_child_tid; /* CLONE_CHILD_SETTID */ 52 int __user *clear_child_tid; /* CLONE_CHILD_CLEARTID */ 53 unsigned long rt_priority; 54 cputime_t utime, stime, utimescaled, stimescaled; 55 unsigned long nvcsw, nivcsw; /* 上下文切换计数 */ 56 struct timespec start_time; /* 单调时间 */ 57 struct timespec real_start_time; /* 启动以来的时间 */ 58 /* 内存管理器失效和页交换信息,这个有一点争论。它既可以看作是特定于内存管理器的, 59 也可以看作是特定于线程的 */ 60 unsigned long min_flt, maj_flt; 61 cputime_t it_prof_expires, it_virt_expires; 62 unsigned long long it_sched_expires; 63 struct list_head cpu_timers[3]; 64 /* 进程身份凭据 */ 65 uid_t uid,euid,suid,fsuid; 66 gid_t gid,egid,sgid,fsgid; 67 struct group_info *group_info; 68 kernel_cap_t cap_effective, cap_inheritable, cap_permitted; 69 unsigned keep_capabilities:1; 70 struct user_struct *user; 71 char comm[TASK_COMM_LEN]; /* 除去路径后的可执行文件名称-用[gs]et_task_comm访问(其中用task_lock()锁定它)-通常由flush_old_exec初始化 */ 72 /* 文件系统信息 */ 73 int link_count, total_link_count; 74 /* ipc相关 */ 75 struct sysv_sem sysvsem; 76 /* 当前进程特定于CPU的状态信息 */ 77 struct thread_struct thread; 78 /* 文件系统信息 */ 79 struct fs_struct *fs; 80 /* 打开文件信息 */ 81 struct files_struct *files; 82 /* 命名空间 */ 83 struct nsproxy *nsproxy; 84 /* 信号处理程序 */ 85 struct signal_struct *signal; 86 struct sighand_struct *sighand; 87 sigset_t blocked, real_blocked; 88 sigset_t saved_sigmask; /* 用TIF_RESTORE_SIGMASK恢复 */ 89 struct sigpending pending; 90 unsigned long sas_ss_sp; 91 size_t sas_ss_size; 92 int (*notifier)(void *priv); 93 void *notifier_data; 94 sigset_t *notifier_mask; 95 #ifdef CONFIG_SECURITY 96 void *security; 97 #endif 98 /* 线程组跟踪 */ 99 u32 parent_exec_id; 100 u32 self_exec_id; 101 /* 日志文件系统信息 */ 102 void *journal_info; 103 /* 虚拟内存状态 */ 104 struct reclaim_state *reclaim_state; 105 struct backing_dev_info *backing_dev_info; 106 struct io_context *io_context; 107 unsigned long ptrace_message; 108 siginfo_t *last_siginfo; /* 由ptrace使用。*/ 109 ... 110 };
task_struct结构体的内容可以分解为各个部分,每个部分表示进程的一个方面。
- 状态和执行信息;
- 有关已经分配的虚拟内存信息;
- 进程身份凭据;
- 使用的文件信息;
- 线程信息记录该进程特定于CPU的运行时间数据(与硬件无关);
- 与其他应用程序协作时所需的进程间通信相关信息;
- 该进程所用的信号处理程序,用于响应信号的到来。
对于进程管理,task_struct中state指定了当前状态(TASK_RUNNING运行;TASK_INTERRUPTIBLE等待某事件/资源的睡眠状态;TASK_UNINTERRUPTIBLE年内和指示停用的睡眠状态;TASK_STOPPED特意停止运行(多用于调试);TASK_TRACED(用于调试区分常规进程);EXIT_ZOMBIE僵尸状态;EXIT_DEAD指wait系统调用已发出)。
此外,Linux提供资源限制(resource limit)机制,对进程使用系统资源施加某些限制。在task_struct中反应在rlim数组上,系统调用setrlimit来增减当前限制。rlim数组中的位置标识了受限制资源的类型,这也是内核需要定义预处理器常数,将资源与位置关联起来的原因。具体代码以及不同硬件上的值的设置手册上有详细描述。init进程的限制在系统启动时生效, 定义在include/asm-generic-resource.h中的INIT_RLIMITS。
1、进程类型
典型的UNIX进程包括:二进制代码组成的应用程序、单线程、分配给应用程序的一组资源。新进程使用fork和exec系统调用产生。
- fork生成当前进程一个相同副本,该副本称为子进程,子进程复制所有父进程的资源,父子进程相互独立。
- exec从一个可执行文件加载另一个应用程序,来替代当前运行的程序。(不创建新进程,必须首先使用fork复制一个旧进程,然后调用exec在系统上创建另一个应用程序)
除此以外,Linux还提供了clone系统调用,用于实现线程,但仅仅系统调用还不足以做到,还需要用户空间库配合实现。
- clone工作原理基本与fork相同,但新进程不独立于父进程,而可以指定与父进程共享某些资源。
2、命名空间
命名空间提供了虚拟化的一种轻量级形式,使得我们可以从不同方面查看运行系统的全局属性。
传统上,在Linux以及其它衍生的UNIX变体中,许多资源是全局管理的。系统中所有进程都通过PID标识,内核必须管理一个全局的PID列表,用户ID的管理方式类似,通过全局唯一的UID标识。全局ID使内核可以有选择允许或拒绝某些特权,但不能阻止若干个用户能看到彼此。如果Web主机打算向用户提供计算机的全部访问权限,传统意义上需要为每个用户提供一台物理机,使用KVM或VMWare时资源分配做得不是非常好。
对于计算机的各个用户都需要建立独立内核,和一份完全安装好的配套用户层应用这个问题,命名空间提供了一种不同的解决方案。虚拟化系统中,一台物理计算机可以运行多个内核,可能是并行的多个不同的操作系统,命名空间只使用一个内核在一台物理机上运作,将前述的所有资源通过命名空间抽象,使得可以将一组进程放置到容器中,各个容器彼此隔离。
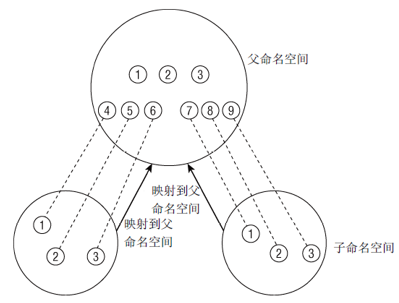
图3 命名空间按层次关联图
图3描述了命名空间可以组织为层次关系。一个命名空间是父命名空间,衍生了两个子命名空间,子命名空间中各进程拥有自己的PID号。虽然子容器不了解系统中其他容器,但父容器知道子命名空间的存在,也可以看到其中执行的所有进程,因此自子容器中的进程可以映射到父容器中,获取全局中唯一的PID号。若命名空间比较简单,也可以设计成非层次的(UTS命名空间,父子命名空间没有联系)。
新的命名空间创建方式有两种:fork或clone系统调用创建进程时,有特定选项可以控制是与父进程共享命名空间,还是新建命名空间;unshare系统调用将进程的某些部分从父进程分离,其中也包括命名空间。
命名空间的实现分为两个部分:每个子系统的命名空间结构;将给定进程关联到所属各命名空间的机制。图4是进程与命名空间之间的联系示意图。

图4 进程和命名空间之间的联系
子系统的全局属性封装到命名空间中,每个进程关联到选定的命名该空间。每个可以感知命名空间的内核子系统都提供了一个数据结构struct_nsproxy(汇集了指向特定于子系统的命名空间包装器的指针),将所有通过命名空间形式提供的对象集中起来。
1 struct nsproxy { 2 atomic_t count; 3 struct uts_namespace *uts_ns; //包含了运行内核的名称、版本、底层体系结构类型信息 4 struct ipc_namespace *ipc_ns; //所有进程间通信(IPC)相关信息 5 struct mnt_namespace *mnt_ns; //已装载文件系统视图 6 struct pid_namespace *pid_ns; //有关进程的ID信息 7 struct user_namespace *user_ns; //用于限制每个用户资源的使用信息 8 struct net *net_ns; //包含所有网络相关的命名空间参数 9 };
每个命名空间都提供了相应的标志用于fork建立一个新的命名空间。因为在每个进程关联到自身命名空间时,使用了指针,所以多个进程可以共享一组子命名空间,修改给定的命名空间,对所有属于该命名空间的进程都是可见的。
- UTS(UNIX Timesharing System)命名空间
它存储了系统的名称(Linux...)、内核发布版本、机器名等。使用uname工具可以取得这些属性的当前值。它几乎不需要特别处理,因为它只需要简单量,没有层次组织。所有相关信息都汇集到结构uts_namespace中。
1 struct uts_namespace { 2 struct kref kref; //嵌入的引用计数器,用于跟踪内核有多少的地方使用了该命名空间实例 3 struct new_utsname name; //命名空间所提供的属性信息 4 };
内核通过copy_utsname函数创建UTS命名空间,在读取或设置UTS属性值时,内核会保证总是操作特定于当前进程的uts_namespace实例,在当前进程修改UTS属性不会反映到父进程,而父进程的修改也不会传播到子进程。
- 用户命名空间
用户命名空间维护了一些统计数据(如进程和打开文件数目),它在数据结构管理方面类似于UTS,在要求创建新的用户命名空间时,生成当前用户命名空间的一份副本,并关联到当前进程nsproxy实例。
1 struct user_namespace { 2 struct kref kref; //嵌入的计数器 3 struct hlist_head uidhash_table[UIDHASH_SZ]; //访问各个实例列表 4 struct user_struct *root_user; //负责记录其资源消耗 5 };
每个用户命名空间对其用户资源使用的统计,与其他命名空间完全无关,对root用户的统计也是如此。这是因为在克隆一个用户命名空间时,为当前用户和root都创建了新的user_struct实例。
3、进程ID号
UNIX进程会分配一个ID号(简称PID)作为其命名空间中唯一的标识。ID有的多类型:
- 进程处于某个线程组时,拥有线程组ID(TGID)(若进程没有使用线程,则PID与TGID相同);
- 独立进程可以合并成进程组,进程组成员的task_struct的pgrp属性值相同(为进程组组长PID)(用管道连接的进程便包含在同一个进程组中);
- 几个进程组可以合并成一个会话,会话中所有进程都有会话ID(SID),保存在task_struct的session中。
命名空间增加了PID管理的复杂性。PID命名空间按层次组织,因此必须区分局部ID和全局ID。
- 全局ID是在内核本身和初始命名空间中唯一的ID号,对每个ID类型,都有一个全局ID,保证在整个系统中唯一;
- 局部ID属于某特定命名空间,不具备全局有效性。在所属的命名空间内部有效,因此类型相同、值也相同的ID可能出现在不同的命名空间中。
PID分配器(pid allocator)用于加速新ID的分配(此处ID是广义的包括TGID,SID等)。内核提供辅助函数,实现通过ID及其类型查找进程的task_struct的功能,以及将ID的内核表示形式和用户空间可见的数值进行转换的功能。
PID命名空间的表示方式以及含义:
1 struct pid_namespace { 2 ... 3 struct task_struct *child_reaper; //每个PID命名空间都具有一个进程,其发挥的作用相当于全局的init进程。child_reaper保存了指向该进程的task_struct的指针。 4 ... 5 int level; //表示当前命名空间在命名空间层次结构中的深度,初始命名空间的level为0。 6 struct pid_namespace *parent; //指向父命名空间的指针 7 };
PID的管理围绕struct_pid和struct_upid展开,struct pid是内核对PID的内部表示,而struct upid则表示特定的命名空间中可见的信息。
1 struct upid { 2 int nr; //ID的数值 3 struct pid_namespace *ns; //指向该ID所属的命名空间的指针 4 struct hlist_node pid_chain; //将所有的upid链接在一起的散链表 5 };
1 truct pid 2 { 3 atomic_t count; //引用计数器 4 /* 使用该pid的进程的列表 */ 5 struct hlist_head tasks[PIDTYPE_MAX]; //每一项对应一个id类型,作为散列表头。对于其中的每项,因为一个ID可能用于几个进程,所有共享同一给定ID的task_struct实例都通过该列表连接 6 int level; //表示可以看到该进程的命名空间的数目 7 struct upid numbers[1]; //upid实例数组,每个数组项都对应于一个命名空间 8 };
1 enum pid_type 2 { 3 PIDTYPE_PID, 4 PIDTYPE_PGID, 5 PIDTYPE_SID, 6 PIDTYPE_MAX //ID类型的数目 7 };
枚举类型中定义的ID类型不包括线程组ID,因为线程组ID无非是线程组组长的PID。图5对pid和upid两个结构的关系进行了概述。对于members数组,形式上只有一个数组项,如果一个进程只包含在全局命名空间中,那么确实如此。由于该数组位于结构的末尾,因此只要分配更多的内存空间,即可向数组添加附加的项。
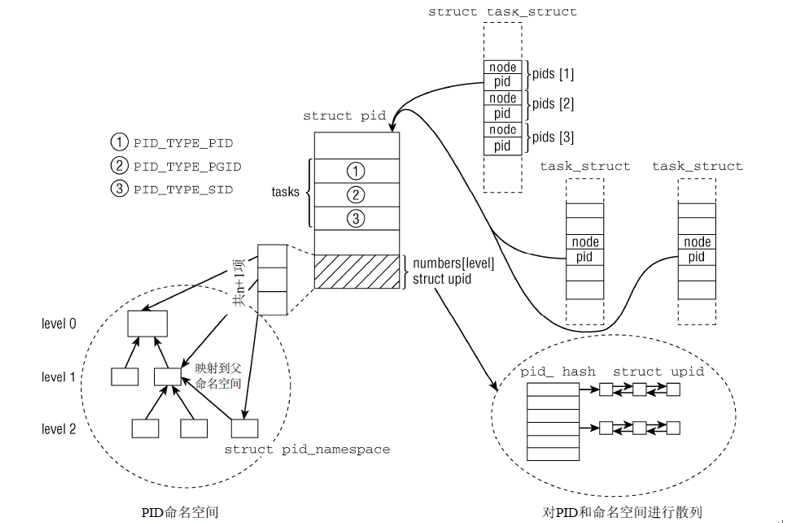
图5 实现可感知命名空间的ID表示所用的数据结构
内核提供了若干辅助函数,用于操作和扫描上述复杂结构,完成以下两个任务:
- 给出局部数字id和对应的命名空间,查找此二元组的task_struct;
- 给出task_struct、id类型、命名空间,取得命名空间局部的数字ID。
此外,内核还负责提供机制来生成唯一PID,具体方法:为跟踪已经分配和仍然可用的PID,内核使用一个大的位图,其中每个PID由一个比特标识。PID的值可通过对应比特在位图中的位置计算而来。所有其他的ID都可以派生自PID。
4、进程关系
完成了ID连接关系之后,内核还负责管理建立在UNIX进程创建模型之上的“家族关系”(如果由进程A形成了进程B,则A是父进程,B是子进程;若进程A形成了若干个子进程,则这些子进程之间成为兄弟关系)。图6说明了进程家族中的父子关系和兄弟关系,以及task_struct中children和sibling两个链表表头实现这些关系的方式。
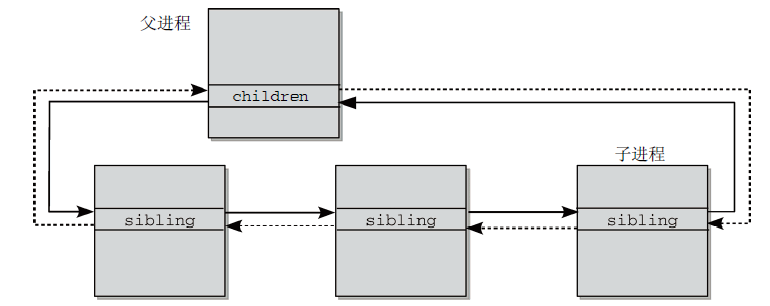
图6 进程间家族关系
四、进程管理相关的系统调用
1、进程复制
Linux的进程复制有三种方式:
- fork,重量级调用,它建立了父进程的完整副本,然后作为子进程执行。(为了减少工作量,提高效率,使用了写时复制技术)
- vfork,类似于fork,不创建父进程副本。相反,父子进程之间共享数据。(节省了大量CPU时间)vfork设计用于子进程形成后立即执行execve系统调用加载新程序的情形。在子进程退出或开始
新程序之前,内核保证父进程处于堵塞状态。 - clone,产生线程,可以对父子进程之间的共享、复制进行精确控制。
(1)写时复制(COW)
写时复制技术(copy-on-write),用来防止在fork执行时将父进程的所有数据复制到子进程。为了解决很多情况下不需要复制父进程信息时,复制父进程副本使用大量内存,耗费很长时间的问题。
fork之后,父子进程的地址空间指向同样的物理内存页,此时,物理内存页处于只读状态。如果确实要对内存进行写入操作,会产生缺页异常,然后由内核分配内存空间。
(2)执行系统调用
fork、vfork和clone系统调用的入口点分别是sys_fork、sys_vfork和sys_clone函数。这些入口函数都调用体系结构无关的do_fork函数,通过clone_flags这个标志集合区分不同入口。区别也可以戳这里。
1 long do_fork( 2 unsigned long clone_flags, //标志集合,指定控制复制过程的属性 3 unsigned long stack_start, //用户状态下栈的起始地址 4 struct pt_regs *regs, //指向寄存器集合的指针,以原始形式保存了调用参数 5 unsigned long stack_size, //用户状态下栈的大小,通常设为0 6 int __user *parent_tidptr, //指向用户空间中父进程的PID 7 int __user *child_tidptr //指向用户空间中子进程的PID 8 )
(3)do_fork的实现
do_fork的代码流程图如图7所示。

图7 do_fork代码流程图
子进程生产成功后,内核必须执行收尾操作:
- 如果设置了CLONE_PID标志,fork操作可能会创建新的pid命名空间。如果创建了新的命名空间,则需要在新命名空间获取pid,否则直接获取局部pid。
- 如果用了ptrace监控,创建进程后,就向它发送SIGSTOP信号,让调试器检查数据。
- 子进程使用wake_up_new_task唤醒(将它的task_struct添加到调度器队列,让它有机会执行)。
- 如果使用vfork机制,必须启用子进程的完成机制,子进程的task_struct的vfork_done成员即用于该目的,父进程用wait_for_completion函数在该变量中进入睡眠,直至子进程退出。子进程终止时,内核调用complete(vfork_done)唤醒因该变量睡眠的进程。
(4)复制进程
在do_fork中大多数工作是由copy_process函数完成的,该函数根据标志的控制,处理了3个系统调用(fork、vfork和clone)的主要工作。copy_process流程图如图8所示。(详见手册)
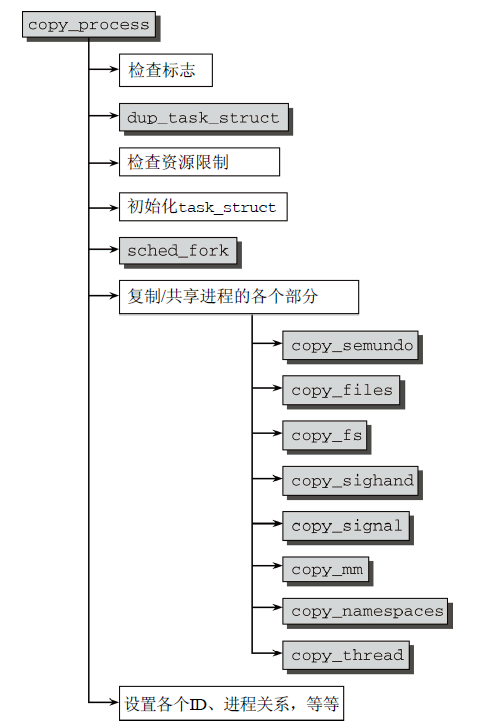
图8 copy_process的代码流程图
(5)创建线程特别问题
用户空间线程库使用clone系统调用来生成新线程。该调用支持(上文讨论之外的)标志,对copy_process(及其调用的函数)具有某些特殊影响。
- CLONE_PARENT_SETTID将生成线程的PID复制到clone调用指定的用户空间中的某个地址
- CLONE_CHILD_SETTID首先会将另一个传递到clone的用户空间指针(child_tidptr)保存在新进程的task_struct中。
- CLONE_CHILD_CLEARTID首先会在copy_process中将用户空间指针child_tidptr保存在task_struct中,这次是另一个不同的成员。
上述标志可用于从用户空间检测内核中线程的产生和销毁。CLONE_CHILD_SETTID和CLONE_PARENT_SETTID用于检测线程的生成。CLONE_CHILD_CLEARTID用于在线程结束时从内核向用户空间传递信息,在多处理器系统上这些检测可以真正地并行执行。
2、内核线程
内核线程是直接由内核本身启动的进程。内核线程实际上是将内核函数委托给独立的进程,与系统中其他进程“并行”执行(实际上,也并行于内核自身的执行)。内核线程经常称之为(内核)守护进程,它们用于执行下列任务:
- 周期性地将修改的内存页与页来源块设备同步(例如,使用mmap的文件映射)。
- 如果内存页很少使用,则写入交换区。
- 管理延时动作(deferred action)。
- 实现文件系统的事务日志。
基本上,内核线程有两种:
- 线程启动后一直等待,直至内核请求线程执行某一特定操作。
- 线程启动后按周期性间隔运行,检测特定资源的使用,在用量超出或低于预置的限制值时采取行动。内核使用这类线程用于连续监测任务。
因为内核线程是由内核自身生成的,它有两个特别之处:
- 它们在CPU的管态(supervisor mode)执行,而不是用户状态。
- 它们只可以访问虚拟地址空间的内核部分(高于TASK_SIZE的所有地址),但不能访问用户空间。
内核线程可以用两种方法实现:
古老的方法:
- (1)将一个函数传递给kernel_thread,内核调用daemonize以转换为守护进程,从内核释放父进程的所有资源。
- (2)daemonize阻塞信号的接收。
- (3)将init作为守护进程的父进程。
备选方案:使用宏kthread_run(参数与kthread_create相同),它会调用kthread_create创建新线程,立即唤醒它。还可以使用kthread_create_cpu代替kthread_create创建内核线程,使之绑定到特定的CPU。
3、启动新程序
(1)execve的实现
该系统调用的入口点是体系结构相关的sys_execve函数。该函数很快将其工作委托给系统无关的do_execve例程。do_execve的代码流程图如图9所示。
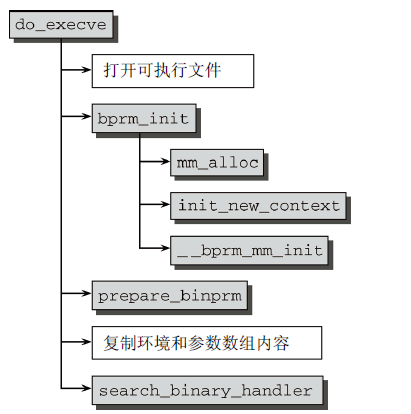
图9 do_execve代码流程图
do_execve的主要工作:
- 打开要执行的文件;
- bprm_init,申请进程空间并初始化,处理若干管理性任务;
- prepare_binprm,提供父进程相关的值(特别是有效UID和GID),也是用于初始化;
- search_binary_handler,查找一种适当的二进制格式,用于所要执行的特定文件。
通常,二进制格式处理程序执行下列操作:
- 释放原进程的所有资源;
- 将应用程序映射到虚拟地址空间,参数和环境也映射到虚拟地址空间;
- 设置进程的指令指针和其他特定于体系结构的寄存器。
(2)解释二进制格式
Linux内核中,每种二进制格式都表示为结构体linux_binfmt,都需要用register_binfmt向内核注册。linux_binfmt结构为:
1 struct linux_binfmt { 2 struct linux_binfmt * next; 3 struct module *module; 4 int (*load_binary)(struct linux_binprm *, struct pt_regs * regs); 5 int (*load_shlib)(struct file *); 6 int (*core_dump)(long signr, struct pt_regs * regs, struct file * file); 7 unsigned long min_coredump; /* minimal dump size */ 8 };
二进制格式主要接口函数
- load_binary用于加载普通程序。
- load_shlib用于加载共享库,即动态库。
- core_dump用于在程序错误的情况下输出内存转储,用于调试分析,以解决问题。
4、退出进程
进程必须用exit系统调用终止,使得内核有机会将该进程使用的资源释放回系统。该调用的入口点是sys_exit函数,该函数的实现就是将各个引用计数器减1,如果引用计数器归0而没有进程再使用对应的结构,那么将相应的内存区域返还给内存管理模块。