在前段时间将JSON Extractor元件做了个简单的介绍:Jmeter元件——JSON Extractor后置处理器介绍1,今天以一个具体的json,以不同的方式提取数据做个详细的介绍。
一、模拟请求
使用java请求来模拟请求,入参json格式数据,以实例来讲解,具体如下
1.在线程组下添加一个java请求
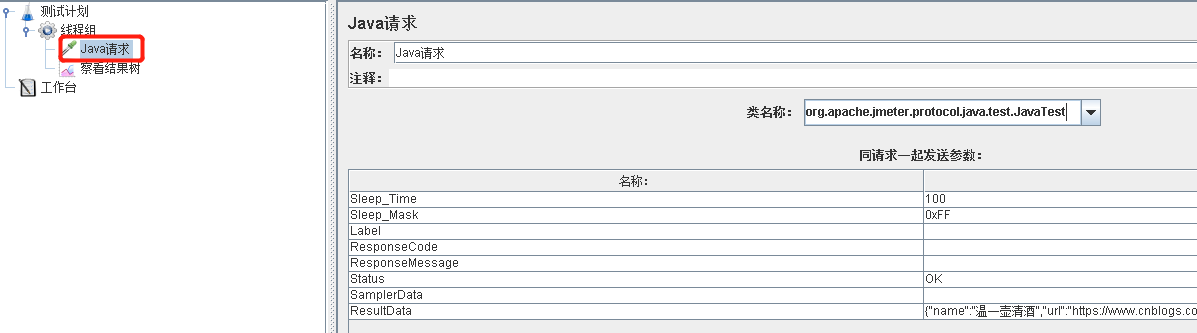
2.类名称选择org.apache.jmeter.protocol.java.test.JavaTest
3.json数据填入ResultData中

4.运行该脚本,在结果树中查看结果
二、数据提取
json示例数据如下:
{"name":"温一壶清酒","url":"https://www.cnblogs.com/hong-fithing/","page":5,"isNonProfit":true,"address":{"street":"科技园路","city":"上海","country":"中国"},"data":{"Jenkins系列博客":[{"name":"Jenkins环境搭建(1)-下载与安装","url":"https://www.cnblogs.com/hong-fithing/p/10290315.html","pageview":[189,133],"keywords":["jenkins"]},{"name":"Jenkins环境搭建(2)-搭建jmeter+ant+jenkins自动化测试环境","url":"https://www.cnblogs.com/hong-fithing/p/10462493.html","pageview":[398,1500],"keywords":["jenkins","ant","jmeter"]},{"name":"Jenkins环境搭建(3)-配置自动发送邮件","url":"https://www.cnblogs.com/hong-fithing/p/10473996.html", "pageview":[18900,28800],"page":18900, "keywords":[ "jenkins", "邮件"]}],"UI自动化系列博客":[{"name":"UI自动化测试(一)简介及Selenium工具的介绍和环境搭建","url":"https://www.cnblogs.com/hong-fithing/p/7622215.html","pageview":1988,"keywords":[ "selenium","自动化"]},{"name":"UI自动化测试(二)浏览器操作及对元素的定位方法(xpath定位和css定位详解)","url":"https://www.cnblogs.com/hong-fithing/p/7623838.html","pageview":3980,"keywords":["xpath","css","自动化"]},{"name":"UI自动化测试(三)对页面中定位到的元素对象做相应操作","url":"https://www.cnblogs.com/hong-fithing/p/7625800.html","pageview":2489,"keywords":["自动化"]}]},"pageview":18900 }
1.基本提取
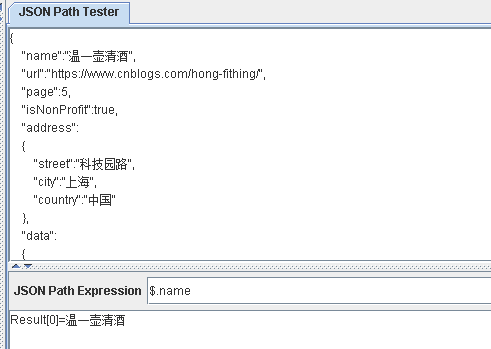
$['name'] $.name
区别:
使用符号.只能获取一个子节点
使用中括号[]可以获取多个子节点的值
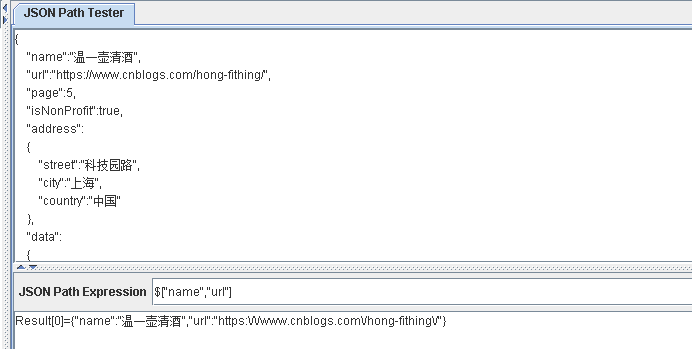
$["name","url"] 获取的是根节点下name节点和url节点,并不是值
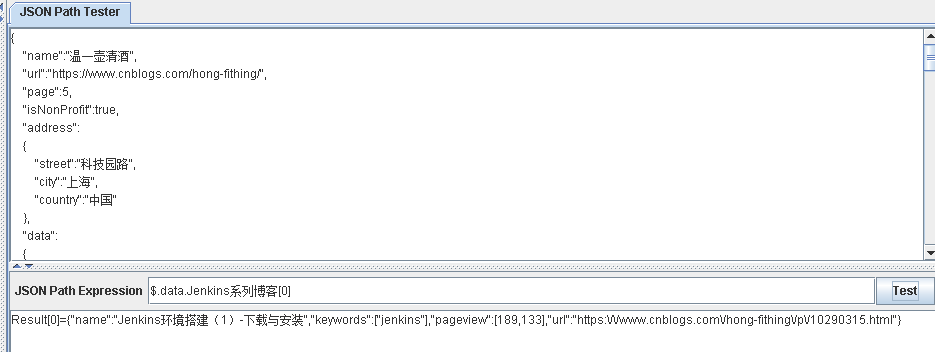
$.data.Jenkins系列博客[*]
$.data.Jenkins系列博客
区别:
使用[*],表示获取data节点下 Jenkins系列博客 数组中元素的值
不使用[*] 表示获取data节点下 Jenkins系列博客 的值


$.data.Jenkins系列博客[0] 表示获取 Jenkins系列博客 数组中第一个元素 $.data.Jenkins系列博客[0,2] 表示获取 Jenkins系列博客 数组中第一个/第三个元素
2.切片处理
切片处理,就类似于取数据的一个范围值,格式为:$.data.Jenkins系列博客[n:m]
说明:
n:表示数组元素的起始下标,如果不填写,则默认为0,表示从第一个开始
m:表示数组原因的结束下标,如果不填写,则默认为数组的最后一个
ps:是一个半闭半开区间,即包含起始下标,不包含结束下标
$.data.Jenkins系列博客[0:] 提取数组中的所有元素 $.data.Jenkins系列博客[1:] 提取第一个开始到最后的元素
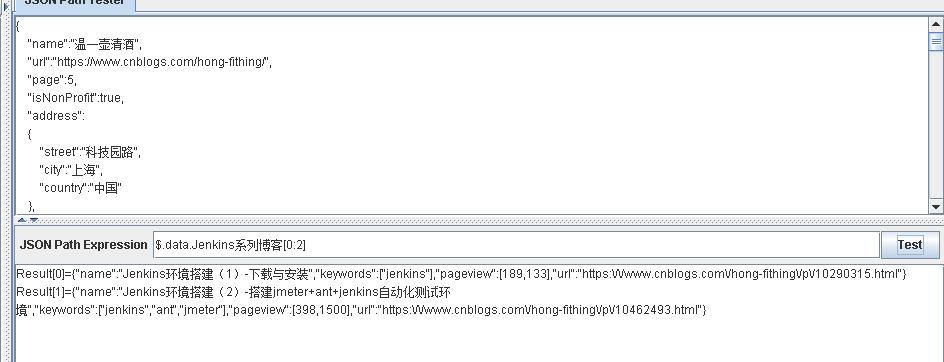
$.data.Jenkins系列博客[-n:] 提取倒数n个元素
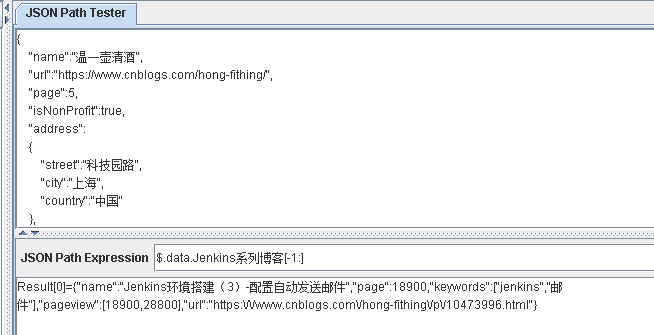
$.data.Jenkins系列博客[:-m] 提取不包含最后m个元素的其他元素
输入负值说明,如下:
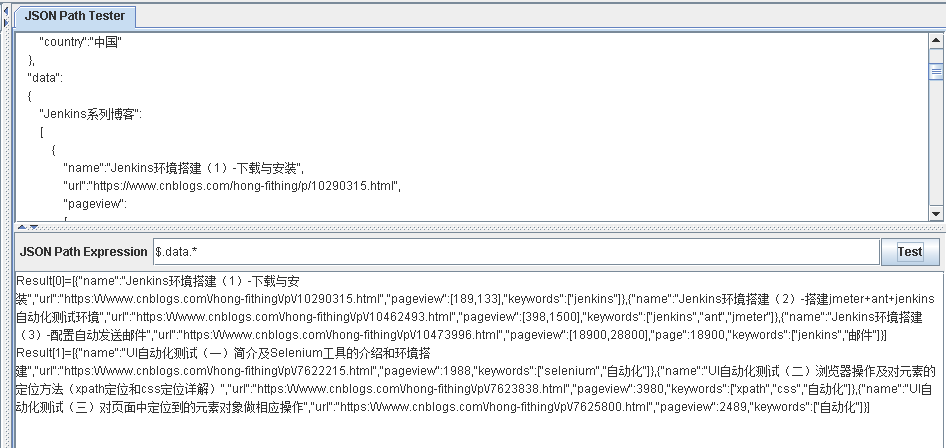
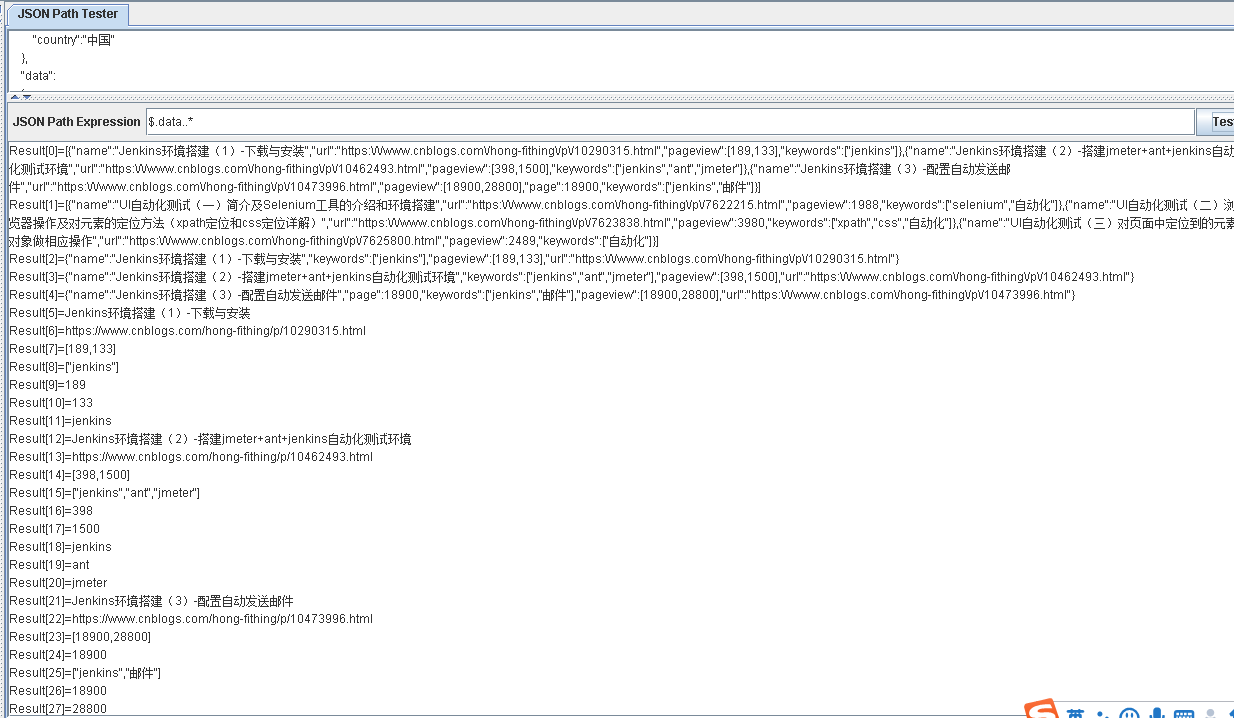
$.data.*
$.data..*
.* 表示获取data节点下的所有子节点
..* 表示获取data节点下所有符合条件的所有节点
如下图所示:
3.过滤表达式
表达式是用于数组节点的过滤处理,用来找到符合要求的节点,因为json是无序的,格式为:[?(表达式)]
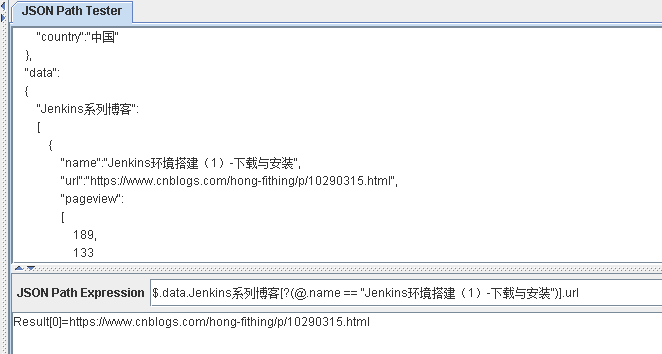
$.data.Jenkins系列博客[?(@.name == "Jenkins环境搭建(1)-下载与安装")].url
这个表达式可用sql来表达为:
select url from Jenkins系列博客 where name='Jenkins环境搭建(1)-下载与安装'
同样的取值,只是写法不一样而已
4.表达式操作
==、!= < <= > >= =~ 正则匹配 in 存在于 nin 不存在于 subsetof 子集 || 或者 && 并且
示例如下:
$.data.Jenkins系列博客[?(@.pageview > 398)] $.data.Jenkins系列博客[?(@.name != "Jenkins环境搭建(1)-下载与安装")].pageview $.data.Jenkins系列博客[?(@.pageview in [398])]
如上简单表达式,就无须过多解释了,一看就明白。
来个正则匹配示例:
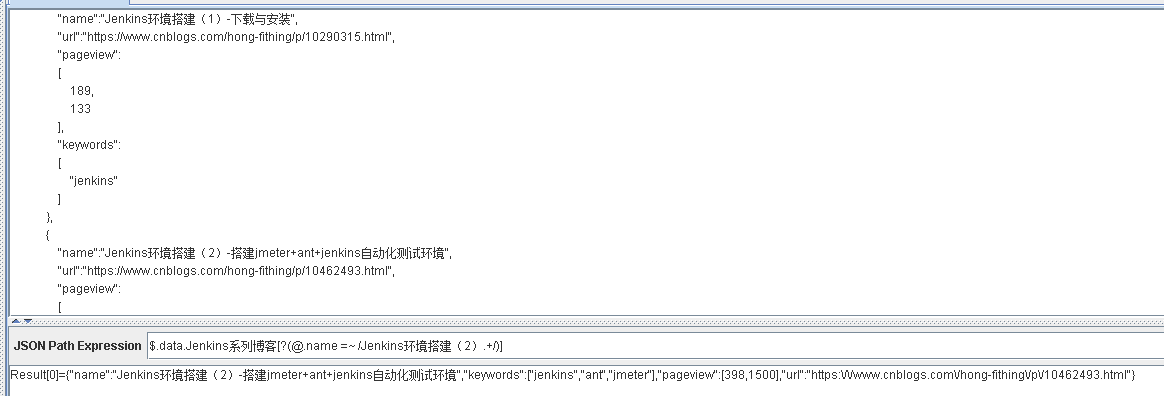
$.data.Jenkins系列博客[?(@.name =~ /Jenkins环境搭建(2).+/)]
表示从 Jenkins系列博客 获取 name 为Jenkins环境搭建(2)开头的元素
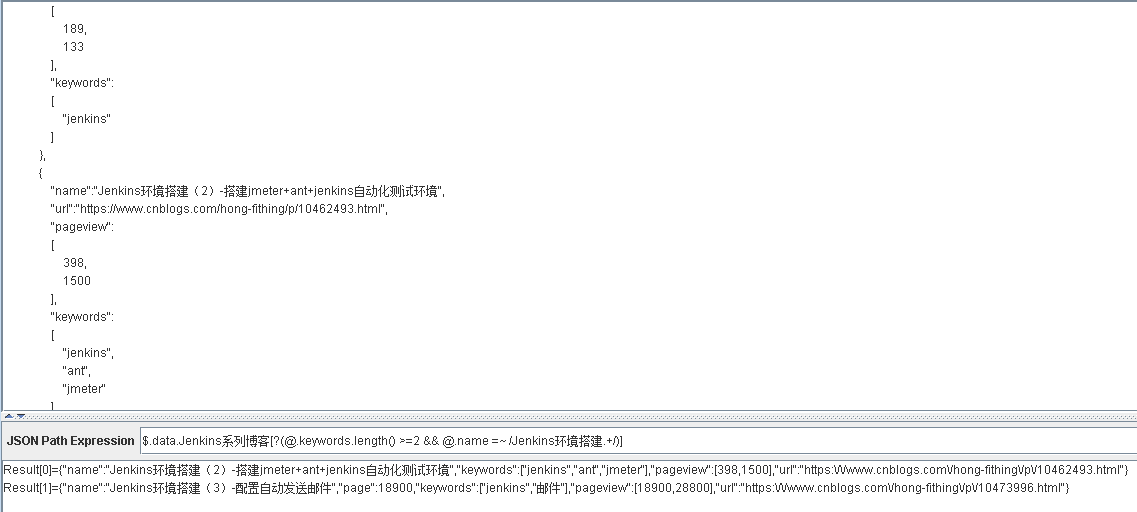
$.data.Jenkins系列博客[?(@.keywords.length() >=2 && @.name =~ /Jenkins环境搭建.+/)]
表示从 Jenkins系列博客 获取 keywords大于等于2 并且 name 为Jenkins环境搭建开头的元素
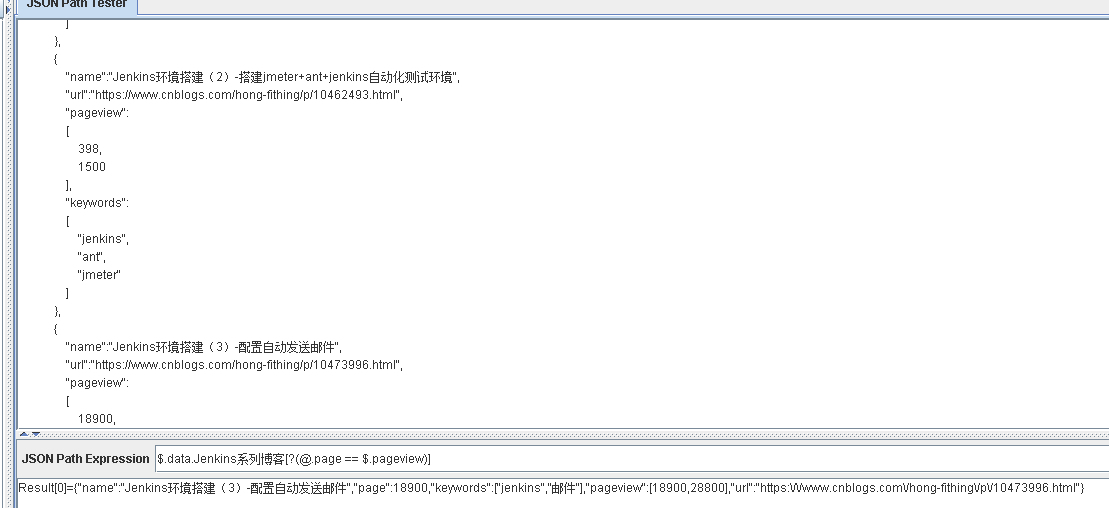
$.data.Jenkins系列博客[?(@.page == $.pageview)]
表示从 Jenkins系列博客 获取 page == 根节点下的pageview 的元素
再来讲个获取子集的表达式
$.data.Jenkins系列博客[?(@.keywords subsetof ["jmeter","jenkins","ant","邮件"])]
表示从 Jenkins系列博客 数组中,获取keywords为 jmeter jenkins ant 邮件 四者的子集的元素
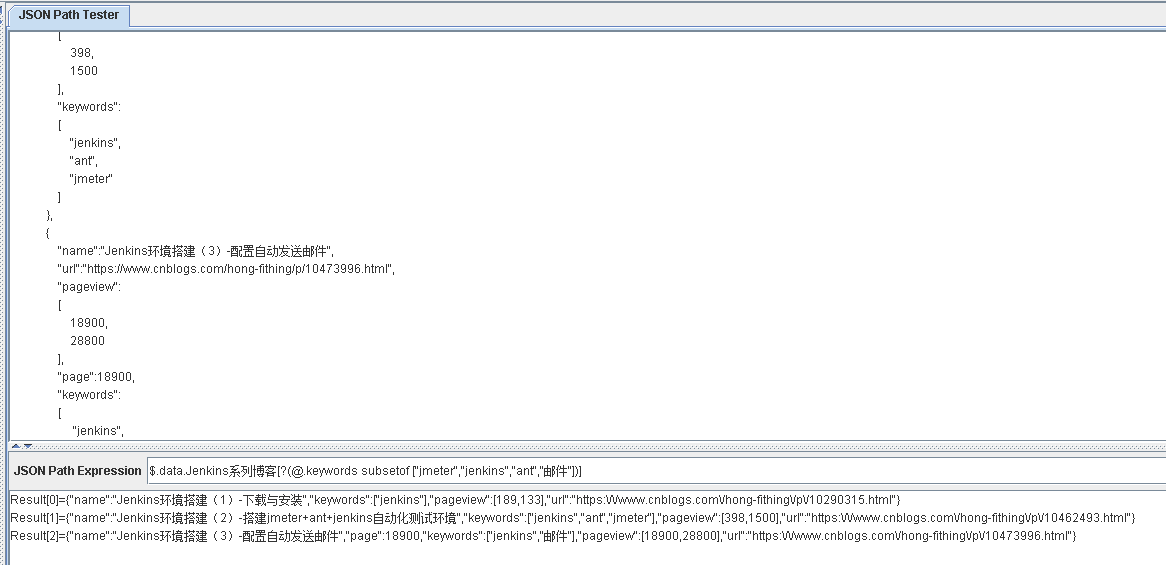
修改表达式如下:
$.data.Jenkins系列博客[?(@.keywords subsetof ["jenkins","邮件","ant"])]
获取到的值如下:

jmeter中的JSON Extractor就介绍到这了,都是些很基础的使用方式,希望对需要的人有所帮助。