Observer:在不伤害写性能的情况下扩展ZooKeeper。
虽然通过Client直接连接到ZooKeeper集群的性能已经很好了,可是这样的架构假设要承受超大规模的Client,就必须添加ZooKeeper集群的Server数量,随着Server的添加,ZooKeeper集群的写性能必定下降。我们知道ZooKeeper的ZNode变更是要过半数投票通过,随着机器的添加,因为网络消耗等原因必定导致投票成本添加,从而导致写性能的下降。
Observer是一种新型的ZooKeeper节点。能够帮助解决上述问题,提供ZooKeeper的可扩展性。Observer不參与投票,仅仅是简单的接收投票结果。因此我们添加再多的Observer,也不会影响集群的写性能。除了这个区别,其它的和Follower基本上全然一样。比如:Client都能够连接到他们,而且都能够发送读写请求给他们,收到写请求都会上报到Leader。
Observer有另外一个优势,由于它不參与投票,所以他们不属于ZooKeeper集群的关键部位,即使他们Failed,或者从集群中断开,也不会影响集群的可用性。
Observer和Follower在一些方面是一样的。详细点来讲,他们都向Leader提交proposal(投票)。但与Follower不同,Observer不参与投票的过程。它简单的通过接收Leader发过来的INFORM(通知)消息来learn已经Commit的proposal。因为Leader都会给Follower和Observer发送INFORM消息,所以它们都被称为Learner。
INFORM消息背后的原理
因为Observer不会接收proposal并参与投票,Leader不会发送proposal给Observer。Leader发送给Follower的Commit消息只包含zxid,并没有proposal本身。所以,只发送Commit消息给Observer则不会让Observer得知已提交的proposal。这就是使用INFORM消息的原因,此消息本质上是一个包含了已被Commit的proposal的Commit消息。
简而言之,Follower会得到两个消息,而Observer只会得到一个。Follower通过广播得到proposal的内容,接下来获得一个简单Commit消息,此消息只包含了zxid。相反,Observer得到一个包含了已被Commit的proposal的INFORM消息。
参与了决定是否Commit一个proposal的投票的server就称为PARTICIPANT Server,Leader和Follower都属于这种Server。Observer则称为OBSERVER Server。
使用Observer模式的一个主要的理由就是对读请求进行扩展。通过增加更多的Observer,可以接收更多的请求的流量,却不会牺牲写操作的吞吐量。注意到写操作的吞吐量取决于quorum的Size。如果增加更多的Server进行投票,quorum会变大,这会降低写操作的吞吐量。然而增加Observer并不会完全没有损耗,每一个新的Observer在每提交一个事务后收到一条额外的消息,这就是前面提到的INFORM消息。这个损耗比起加入Follower来投票来说损耗更少。
使用Observer的另一个原因是跨数据中心部署。把participant分散到多个数据中心可能会极大拖慢系统,因为数据中心之间的网络的延迟。使用Observer的话,更新操作都在一个单独的数据中心来处理,并发送到其他数据中心,让其他数据中心的client消费数据。阿里开源的跨机房同步系统Otter就使用了Observer模式,可以参考。
注意Observer的使用并无法完全消除数据中心之间的网络延迟,因为Observer不得不把更新请求转发到另一个数据中心的Leader,并处理INFORM消息,网络速度极慢的话也会有影响,它的优势是为本地读请求提供快速响应。
场景应用:
依据Observer的特点。我们能够使用Observer做跨数据中心部署。假设把Leader和Follower分散到多个数据中心的话,由于数据中心之间的网络的延迟。势必会导致集群性能的大幅度下降。使用Observer的话,将Observer跨机房部署。而Leader和Follower部署在单独的数据中心,这样更新操作会在同一个数据中心来处理,并将数据发送的其它数据中心(包括Observer的),然后Client就能够在其它数据中心查询数据了。可是使用了Observer并不是就能全然消除数据中心之间的延迟,由于Observer还得接收Leader的同步结果合Observer有更新请求也必须转发到Leader,所以在网络延迟非常大的情况下还是会有影响的,它的优势就为了本地读请求的高速响应。
大致的架构例如以下图:
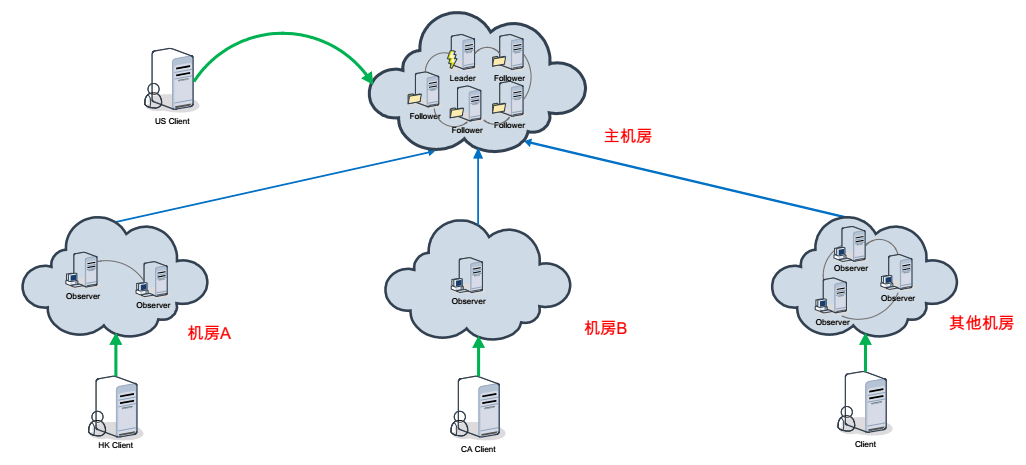
配置
为了使用Observer模式,在任何想变成Observer模式的配置文件($ZOOKEEPER_HOME/conf/zoo.cfg)中加入如下配置:
peerType=observer
并在所有Server的配置文件($ZOOKEEPER_HOME/conf/zoo.cfg)中,配置成Observer模式的server的那行配置追加:observer,例如:
server.1:localhost:2181:3181:observer
然后客户端的操作和Leader和Follow模式完全不变。
zookeeper写请求流程图:
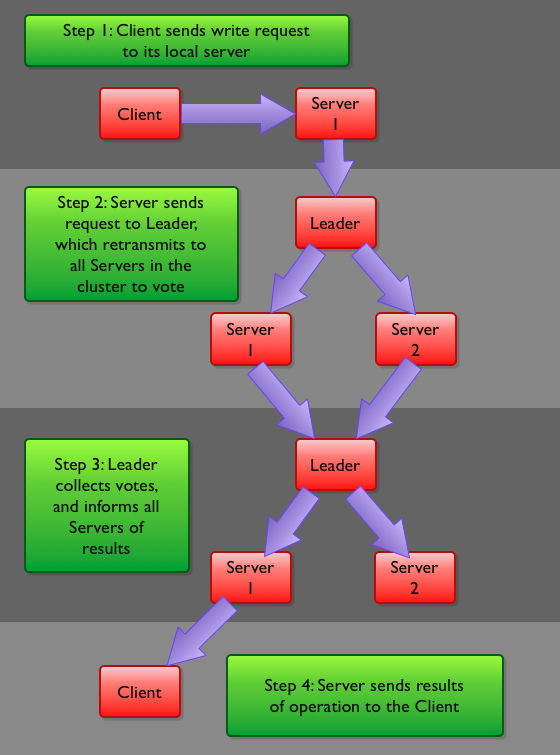
observer服务器在这个流程中只参与了1,4两个步骤,不参与投票。