网上拉取Docker模板,使用singlarities/hadoop镜像
[root@localhost /]# docker pull singularities/hadoop
查看:
[root@localhost /]# docker image ls REPOSITORY TAG IMAGE ID CREATED SIZE docker.io/singularities/hadoop latest e213c9ae1b36 3 months ago 1.19 GB
创建docker-compose.yml文件,内容:
version: "2" services: namenode: image: singularities/hadoop command: start-hadoop namenode hostname: namenode environment: HDFS_USER: hdfsuser ports: - "8020:8020" - "14000:14000" - "50070:50070" - "50075:50075" - "10020:10020" - "13562:13562" - "19888:19888" datanode: image: singularities/hadoop command: start-hadoop datanode namenode environment: HDFS_USER: hdfsuser links: - namenode
执行:
[root@localhost hadoop]# docker-compose up -d Creating network "hadoop_default" with the default driver Creating hadoop_namenode_1 ... done Creating hadoop_datanode_1 ... done
4个datanode:
[root@localhost hadoop]# docker-compose scale datanode=3 WARNING: The scale command is deprecated. Use the up command with the --scale flag instead. Starting hadoop_datanode_1 ... done Creating hadoop_datanode_2 ... done Creating hadoop_datanode_3 ... done [root@localhost hadoop]# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 19f9685e286f singularities/hadoop "start-hadoop data..." 48 seconds ago Up 46 seconds 8020/tcp, 9000/tcp, 10020/tcp, 13562/tcp, 14000/tcp, 19888/tcp, 50010/tcp, 50020/tcp, 50070/tcp, 50075/tcp, 50090/tcp, 50470/tcp, 50475/tcp hadoop_datanode_3 e96b395f56e3 singularities/hadoop "start-hadoop data..." 48 seconds ago Up 46 seconds 8020/tcp, 9000/tcp, 10020/tcp, 13562/tcp, 14000/tcp, 19888/tcp, 50010/tcp, 50020/tcp, 50070/tcp, 50075/tcp, 50090/tcp, 50470/tcp, 50475/tcp hadoop_datanode_2 5a26b1069dbb singularities/hadoop "start-hadoop data..." 8 minutes ago Up 8 minutes 8020/tcp, 9000/tcp, 10020/tcp, 13562/tcp, 14000/tcp, 19888/tcp, 50010/tcp, 50020/tcp, 50070/tcp, 50075/tcp, 50090/tcp, 50470/tcp, 50475/tcp hadoop_datanode_1 a8656de09ecc singularities/hadoop "start-hadoop name..." 8 minutes ago Up 8 minutes 0.0.0.0:8020->8020/tcp, 0.0.0.0:10020->10020/tcp, 0.0.0.0:13562->13562/tcp, 0.0.0.0:14000->14000/tcp, 9000/tcp, 50010/tcp, 0.0.0.0:19888->19888/tcp, 0.0.0.0:50070->50070/tcp, 50020/tcp, 50090/tcp, 50470/tcp, 0.0.0.0:50075->50075/tcp, 50475/tcp hadoop_namenode_1 [root@localhost hadoop]#
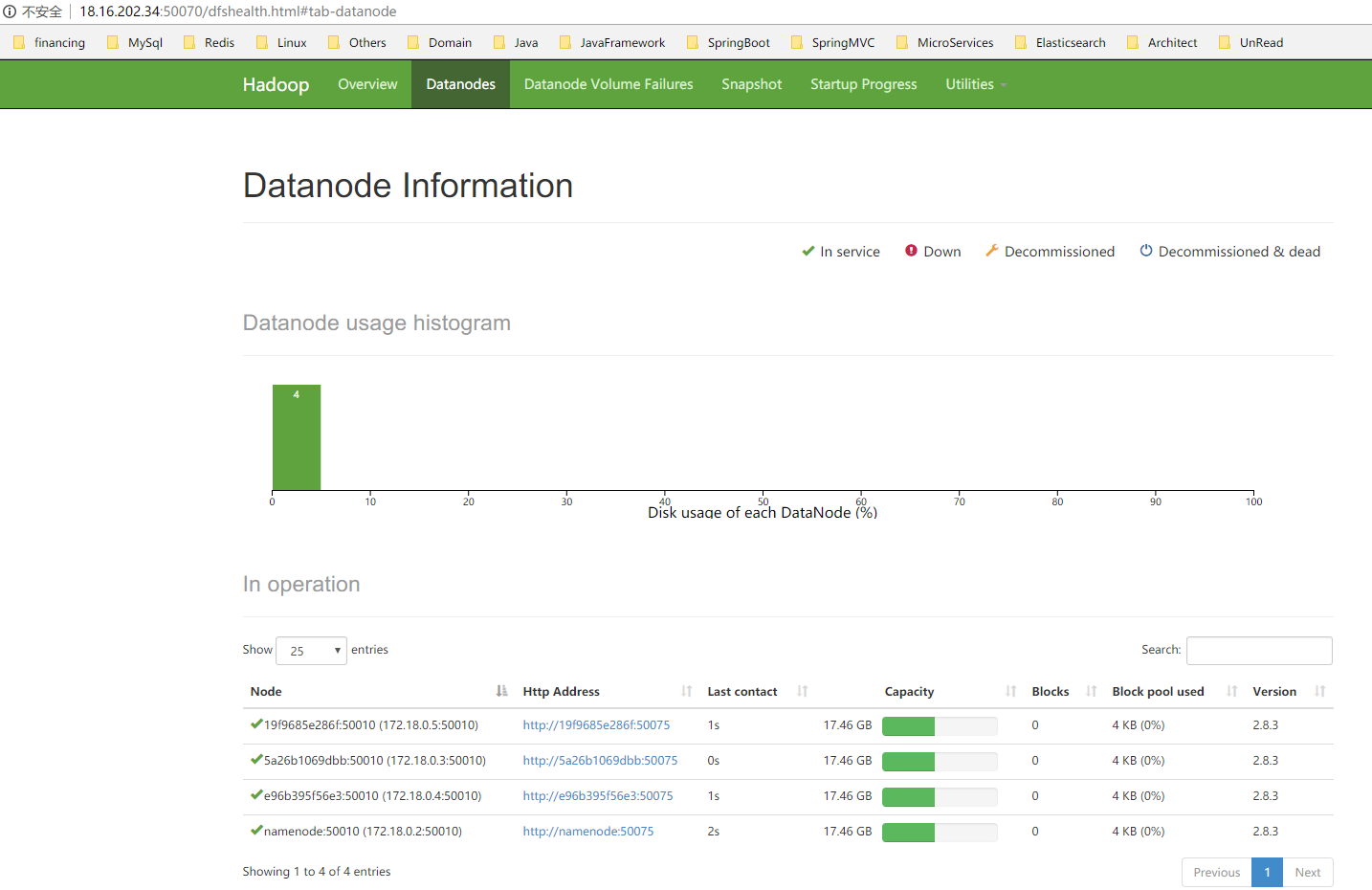
效果图;
hdfs基础命令:
1、创建目录
hadoop fs -mkdir /hdfs #在根目录下创建hdfs文件夹
2、查看目录
>hadoop fs -ls / #列出跟目录下的文件列表 drwxr-xr-x - root supergroup 0 2016-03-05 00:06 /hdfs
3、级联创建目录
>hadoop fs -mkdir -p /hdfs/d1/d2
4、级联列出目录
>hadoop fs -ls -R / drwxr-xr-x - root supergroup 0 2016-03-05 00:10 /hdfs drwxr-xr-x - root supergroup 0 2016-03-05 00:10 /hdfs/d1 drwxr-xr-x - root supergroup 0 2016-03-05 00:10 /hdfs/d1/d2
5、上传本地文件到HDFS
>echo "hello hdfs" >>local.txt >hadoop fs -put local.txt /hdfs/d1/d2
6、查看HDFS中文件的内容
>hadoop fs -cat /hdfs/d1/d2/local.txt
hello hdfs
7、下载hdfs上文件的内容
>hadoop fs -get /hdfs/d1/d2/local.txt
8、删除hdfs文件
>hadoop fs -rm /hdfs/d1/d2/local.txt
Deleted /hdfs/d1/d2/local.txt
9、删除hdfs中目录
>hadoop fs -rmdir /hdfs/d1/d2
10、修改文件的权限
>hadoop fs -ls /hdfs drwxr-xr-x - root supergroup 0 2016-03-05 00:21 /hdfs/d1 #注意文件的权限 >hadoop fs -chmod 777 /hdfs/d1 drwxrwxrwx - root supergroup 0 2016-03-05 00:21 /hdfs/d1 #修改后
11、修改文件所属的用户
>hadoop fs -chown admin /hdfs/d1 #修改文件所属用户为admin >hadoop fs -ls /hdfs drwxrwxrwx - admin supergroup 0 2016-03-05 00:21 /hdfs/d1
12、修改文件的用户组
>hadoop fs -chgrp admin /hdfs/d1 >hadoop fs -ls /hdfs drwxrwxrwx - admin admin 0 2016-03-05 00:21 /hdfs/d1
查看所有命令方式:
root@master:/# hadoop fs Usage: hadoop fs [generic options] [-appendToFile <localsrc> ... <dst>] [-cat [-ignoreCrc] <src> ...] [-checksum <src> ...] [-chgrp [-R] GROUP PATH...] [-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...] [-chown [-R] [OWNER][:[GROUP]] PATH...] [-copyFromLocal [-f] [-p] [-l] [-d] <localsrc> ... <dst>] [-copyToLocal [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>] [-count [-q] [-h] [-v] [-t [<storage type>]] [-u] [-x] <path> ...] [-cp [-f] [-p | -p[topax]] [-d] <src> ... <dst>] [-createSnapshot <snapshotDir> [<snapshotName>]] [-deleteSnapshot <snapshotDir> <snapshotName>] [-df [-h] [<path> ...]] [-du [-s] [-h] [-x] <path> ...] [-expunge] [-find <path> ... <expression> ...] [-get [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>] [-getfacl [-R] <path>] [-getfattr [-R] {-n name | -d} [-e en] <path>] [-getmerge [-nl] [-skip-empty-file] <src> <localdst>] [-help [cmd ...]] [-ls [-C] [-d] [-h] [-q] [-R] [-t] [-S] [-r] [-u] [<path> ...]] [-mkdir [-p] <path> ...] [-moveFromLocal <localsrc> ... <dst>] [-moveToLocal <src> <localdst>] [-mv <src> ... <dst>] [-put [-f] [-p] [-l] [-d] <localsrc> ... <dst>] [-renameSnapshot <snapshotDir> <oldName> <newName>] [-rm [-f] [-r|-R] [-skipTrash] [-safely] <src> ...] [-rmdir [--ignore-fail-on-non-empty] <dir> ...] [-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]] [-setfattr {-n name [-v value] | -x name} <path>] [-setrep [-R] [-w] <rep> <path> ...] [-stat [format] <path> ...] [-tail [-f] <file>] [-test -[defsz] <path>] [-text [-ignoreCrc] <src> ...] [-touchz <path> ...] [-truncate [-w] <length> <path> ...] [-usage [cmd ...]] Generic options supported are -conf <configuration file> specify an application configuration file -D <property=value> use value for given property -fs <file:///|hdfs://namenode:port> specify default filesystem URL to use, overrides 'fs.defaultFS' property from configurations. -jt <local|resourcemanager:port> specify a ResourceManager -files <comma separated list of files> specify comma separated files to be copied to the map reduce cluster -libjars <comma separated list of jars> specify comma separated jar files to include in the classpath. -archives <comma separated list of archives> specify comma separated archives to be unarchived on the compute machines. The general command line syntax is command [genericOptions] [commandOptions]
进入一个容器内部进行上述操作,再进入其他的容器,可以发现数据同步了,另外一个节点的操作其他节点也可以看见。
参考: