在这里给大家来一些关于lucene in action的一些东东
你可以到:http://lucene.apache.org/ 了解更新,更全的关于lucene的信息。
下面我做的demo,分享给大家:
项目结构:
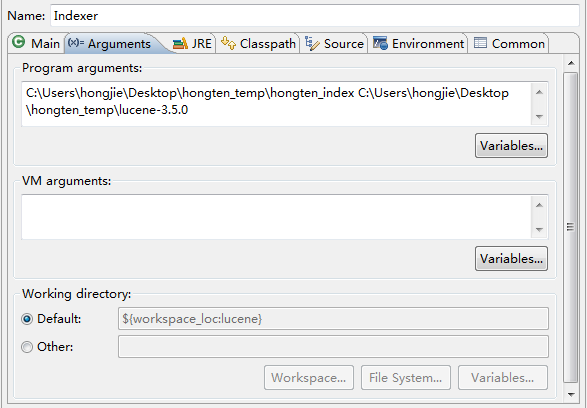
运行Index时,Run Configurations:
[两个参数之间有空格]
args[0] = "C:\Users\hongjie\Desktop\hongten_temp\hongten_index";
args[1] = "C:\Users\hongjie\Desktop\hongten_temp\lucene-3.5.0";
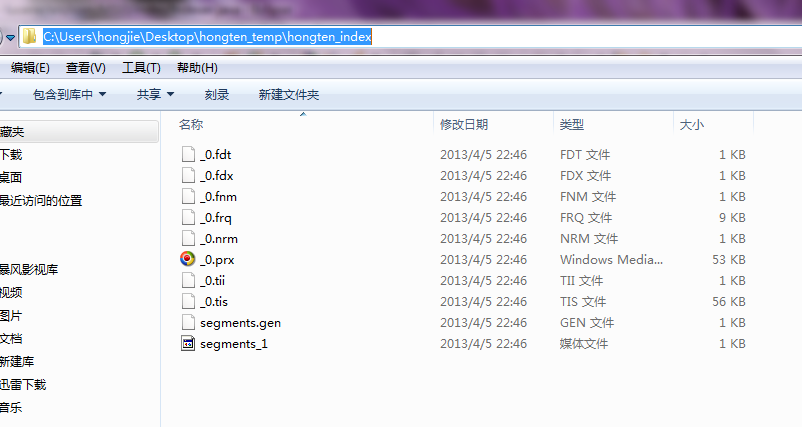
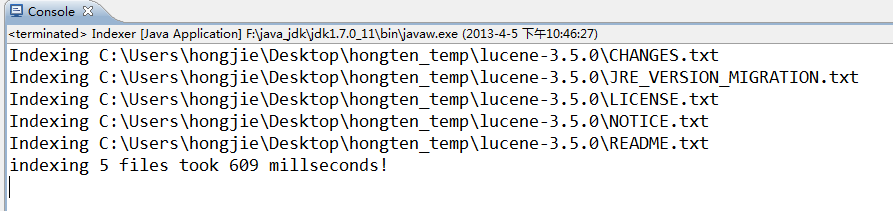
运行效果:
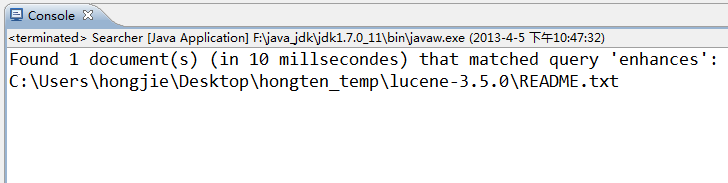
运行Searcher时,Run Configurations:
[两个参数之间有空格]
args[0] = "C:\Users\hongjie\Desktop\hongten_temp\hongten_index";
args[1] = "cnhances";

运行效果:
============================================================
代码部分:
============================================================
/lucene/src/com/b510/index/Indexer.java
1 /** 2 * 3 */ 4 package com.b510.index; 5 6 import java.io.File; 7 import java.io.FileFilter; 8 import java.io.FileReader; 9 10 import org.apache.lucene.analysis.standard.StandardAnalyzer; 11 import org.apache.lucene.document.Document; 12 import org.apache.lucene.document.Field; 13 import org.apache.lucene.index.IndexWriter; 14 import org.apache.lucene.store.Directory; 15 import org.apache.lucene.store.FSDirectory; 16 import org.apache.lucene.util.Version; 17 18 /** 19 * 建立索引 20 * 21 * @author hongten(hongtenzone@foxmail.com)<br> 22 * @date 2013-4-5 23 */ 24 public class Indexer { 25 26 public static void main(String[] args) throws Exception { 27 if (args.length != 2) { 28 throw new IllegalArgumentException("Usage: java " + Indexer.class.getName() + " <index dir><data dir>"); 29 } 30 // 在指定目录创建索引 31 String indexDir = args[0]; 32 String dataDir = args[1]; 33 34 long start = System.currentTimeMillis(); 35 Indexer index = new Indexer(indexDir); 36 int numIndexed; 37 try { 38 numIndexed = index.index(dataDir, new TextFilesFilter()); 39 } finally { 40 index.close(); 41 } 42 long end = System.currentTimeMillis(); 43 44 System.out.println("indexing " + numIndexed + " files took " + (end - start) + " millseconds!"); 45 } 46 47 private IndexWriter writer; 48 49 @SuppressWarnings("deprecation") 50 public Indexer(String indexDir) throws Exception { 51 Directory dir = FSDirectory.open(new File(indexDir)); 52 // create lucene index writer 53 writer = new IndexWriter(dir, new StandardAnalyzer(Version.LUCENE_35), true, IndexWriter.MaxFieldLength.UNLIMITED); 54 } 55 56 /** 57 * close the IndexWriter 58 * 59 * @throws Exception 60 */ 61 public void close() throws Exception { 62 writer.close(); 63 } 64 65 /** 66 * 返回被索引文件数 67 * 68 * @param dataDir 69 * 文件目录 70 * @param filter 71 * @return 72 * @throws Exception 73 */ 74 public int index(String dataDir, FileFilter filter) throws Exception { 75 File[] files = new File(dataDir).listFiles(); 76 77 for (File f : files) { 78 if (!f.isDirectory() && !f.isHidden() && f.exists() && f.canRead() && (filter == null || filter.accept(f))) { 79 indexFile(f); 80 } 81 } 82 // 返回被索引的文档数目 83 return writer.numDocs(); 84 } 85 86 /** 87 * 向lucene中添加文档 88 * 89 * @param f 90 * 文档 91 * @throws Exception 92 */ 93 private void indexFile(File f) throws Exception { 94 System.out.println("Indexing " + f.getCanonicalPath()); 95 Document doc = getDocument(f); 96 writer.addDocument(doc); 97 } 98 99 /** 100 * 添加索引 101 * 102 * @param f 103 * 被索引的文件 104 * @return 105 * @throws Exception 106 */ 107 protected Document getDocument(File f) throws Exception { 108 Document doc = new Document(); 109 doc.add(new Field("contents", new FileReader(f))); 110 doc.add(new Field("filename", f.getName(), Field.Store.YES, Field.Index.NOT_ANALYZED)); 111 doc.add(new Field("fullpath", f.getCanonicalPath(), Field.Store.YES, Field.Index.NOT_ANALYZED)); 112 return doc; 113 } 114 115 /** 116 * 只索引.txt文件,采用FileFilter 117 * 118 * @author hongten(hongtenzone@foxmail.com)<br> 119 * @date 2013-4-5 120 */ 121 private static class TextFilesFilter implements FileFilter { 122 @Override 123 public boolean accept(File pathname) { 124 return pathname.getName().toLowerCase().endsWith(".txt"); 125 } 126 } 127 128 }
/lucene/src/com/b510/search/Searcher.java
1 /** 2 * 3 */ 4 package com.b510.search; 5 6 import java.io.File; 7 import java.io.IOException; 8 9 import org.apache.lucene.analysis.standard.StandardAnalyzer; 10 import org.apache.lucene.document.Document; 11 import org.apache.lucene.queryParser.ParseException; 12 import org.apache.lucene.queryParser.QueryParser; 13 import org.apache.lucene.search.IndexSearcher; 14 import org.apache.lucene.search.Query; 15 import org.apache.lucene.search.ScoreDoc; 16 import org.apache.lucene.search.TopDocs; 17 import org.apache.lucene.store.Directory; 18 import org.apache.lucene.store.FSDirectory; 19 import org.apache.lucene.util.Version; 20 21 import com.b510.index.Indexer; 22 23 /** 24 * 搜索功能 25 * @author hongten(hongtenzone@foxmail.com)<br> 26 * @date 2013-4-5 27 */ 28 public class Searcher { 29 30 public static void main(String[] args) throws IllegalArgumentException, IOException, ParseException { 31 if (args.length != 2) { 32 throw new IllegalArgumentException("Usage: java " + Indexer.class.getName() + " <index dir><data dir>"); 33 } 34 // 在指定目录创建索引 35 String indexDir = args[0]; 36 String q = args[1]; 37 38 search(indexDir, q); 39 } 40 41 /** 42 * 搜索 43 * @param indexDir 搜索目录 44 * @param q 关键字 45 * @throws IOException 46 * @throws ParseException 47 */ 48 public static void search(String indexDir, String q) throws IOException, ParseException { 49 Directory dir = FSDirectory.open(new File(indexDir)); 50 IndexSearcher is = new IndexSearcher(dir); 51 52 QueryParser parser = new QueryParser(Version.LUCENE_35,"contents",new StandardAnalyzer(Version.LUCENE_35)); 53 Query query = parser.parse(q); 54 long start = System.currentTimeMillis(); 55 TopDocs hits = is.search(query, 10); 56 long end = System.currentTimeMillis(); 57 58 System.out.println("Found "+hits.totalHits + " document(s) (in " + (end - start) +" millsecondes) that matched query '"+ q+"':"); 59 60 for(ScoreDoc scoreDoc : hits.scoreDocs){ 61 Document doc = is.doc(scoreDoc.doc); 62 System.out.println(doc.get("fullpath")); 63 } 64 65 is.close(); 66 } 67 }