一、faster rcnn的结构
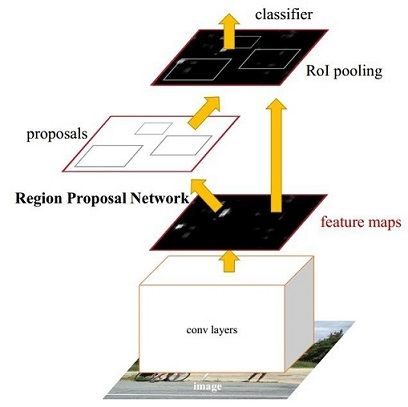
通过上面的结构,我们知道该faster rcnn前面以VGG16为框架,加入RPN层,最后做分类层。
采用VGG16相对ZF来说慢一点,但是精度也高一点。
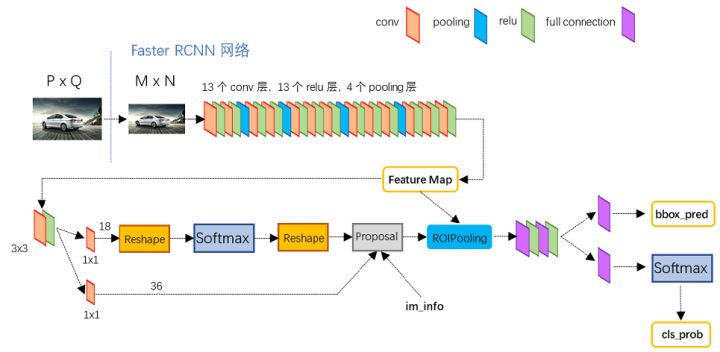
二、RPN结构
RPN层的引入,极大提升检测框的生成速度。RPN是指以下结构:
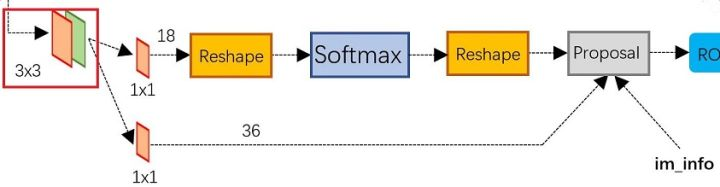
前面的卷积结果过来后,分两路来前进,上面是分类路径(2×9),下面是坐标回归路径(4×9)。RPN属于FCN网络。
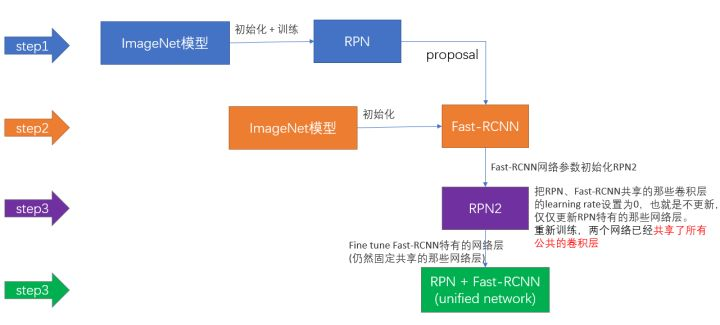
PRN的引入属于创新性变化,我们在训练的时候对RPN进行了两次训练,一次是使用gt+data 对其训练,保存产生的proposal,没有共用卷积层的训练;
一次是共享卷积层的训练,具体设置共享卷据层的lr=0,这样就对RPN单独训练了。
还有就是我们训练RPN时,随机采样256的anchors来,以正负1:1来训练,初始化权重使用高斯随机初始化新层权重,旧层使用预训练的imageNet来初始化。
具体的训练步骤:
三、anchors

这里每个像素点为中心产生9个anchor,每个anchor对应一个分类分数和回归分数。256是图片经过前面的卷积后得到的特征的维度,这里是ZF得到的256维度特征,VGG是512。对该特征
进行reshape成2×9和4×9。

图片的左上角产生9个anchors后,以滑窗的形式遍历整个图,对于1000×600的图片来说就产生20000个anchors,忽略跨界anchor大概剩下6000个anchors。注意这里训练时忽略跨界anchors,但测试时不忽略,而采取剪切到边界的方法。
生成anchors -> softmax分类器提取fg anchors -> bbox reg回归fg anchors -> Proposal Layer生成proposals
这里Proposal Layer生成proposals的过程为:
Proposal Layer forward(caffe layer的前传函数)按照以下顺序依次处理:
- 生成anchors,利用
对所有的anchors做bbox regression回归(这里的anchors生成和训练时完全一致)
- 按照输入的foreground softmax scores由大到小排序anchors,提取前pre_nms_topN(e.g. 6000)个anchors,即提取修正位置后的foreground anchors。
- 限定超出图像边界的foreground anchors为图像边界(防止后续roi pooling时proposal超出图像边界)
- 剔除非常小(width<threshold or height<threshold)的foreground anchors
- 进行nonmaximum suppression
- 再次按照nms后的foreground softmax scores由大到小排序fg anchors,提取前post_nms_topN(e.g. 300)结果作为proposal输出。
四、bounding box regression原理

绿色是gt box,红色是anchor,由图可知anchor的预测不好,没有包含飞机翼。那么我们现在就对该红框使用回归技术使其尽量拟合绿框。注意这里只有当红色靠近绿框才使用回归,太远的误差大,属非线性回归。

给动(Px,Py,Pw,Ph)寻找一种映射使f(Px,Py,Pw,Ph)=(Gxˆ,Gyˆ,Ghˆ,Gwˆ)≈(Gx,Gy,Gh,Gw)
先做平移

再做尺度缩放
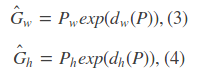
回归就是学习dx(p),dy(P),dw(P),dh(P)四个变换。
输入是P=(Px,Py,Pw,Ph)和gt的t=(tx,ty,tw,th)
而gt与proposal的真正平移量和尺度缩放量是

那么目标函数是d(P)=wΦ(P), Φ(P)是输入proposal的特征向量,w是要学习的参数,d(P)是预测值,我们要使预测值d(P)和真实偏差值t的差距最小,使用平方差函数有
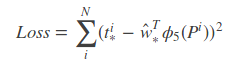
函数优化就是针对该目标函数进行最小化

使用梯度下降求解w。
那么补充下:
1、为什么宽高尺度会设计成这种形式:tx,ty除以宽高,th,tw含log?
因为CNN具有尺度不变性,

图片经上面变化后,t的值不变。如果直接学习坐标差,则就前后发生了改变,即x1-p1不等于x2-p2。
而尺度变化中尺度必须大于0,自然想到exp函数,反过来就是log函数的来源了。
2、为什么anchor靠近gt时,即IOU较大时,才认为是线性变换?
tx和ty显然是线性组合。而tw和th中含有log,我们回忆下
高数里面:

因此:

我们看这公式,当且仅当Gw-Pw=0时,才会是线性函数,即gt的宽高和anchor的宽高必须近似相等。
五、损失函数
正标签:IOU最大 + 与gt重叠>0.7 的框,一个gt框会为多个anchors添加正标签,负标签是<0.3的框。
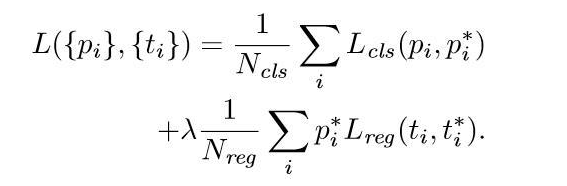
pi是类的概率(只取1/0,当为1时才对正标签激活后面的坐标回归函数),ti是坐标向量,用这两个量来定义函数(分类得分+回归得分)。
Ncls和Nreg是归一化因子,减少递归时间并规范化模型。
λ的选取经实验得10的时候对结果最好。
上面的分类使用对数log损失,下面的回归使用L1平滑函数损失。回归为什么不使用平方函数损失呢?
因为平方函数随着x的增加,平方函数的惩罚会越来越大,所以使用较为平缓的 |x| ; 但 |x| 在0点出不可导,所以要设计成平滑。
最终的L1平滑函数成这样子:
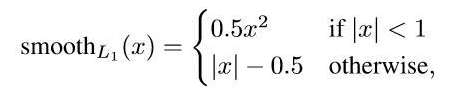
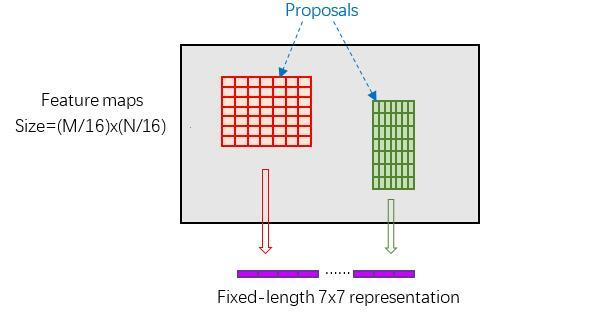
六、RoI Pooling
输入的图片大小不一样,为了统一图片的格式,使用ROI Pooling,保留了全图的特征,而不用crop或wrap掉部分特征。
RoI Pooling layer forward过程:在之前有明确提到: 是对应MxN尺度的,所以首先使用spatial_scale参数将其映射回(M/16)x(N/16)大小的feature maps尺度;之后将每个proposal水平和竖直分为pooled_w和pooled_h份,对每一份都进行max pooling处理。这样处理后,即使大小不同的proposal,输出结果都是 大小,实现了fixed-length output(固定长度输出)。
引用:https://zhuanlan.zhihu.com/p/31426458