运算符
1、算数运算

2、比较运算

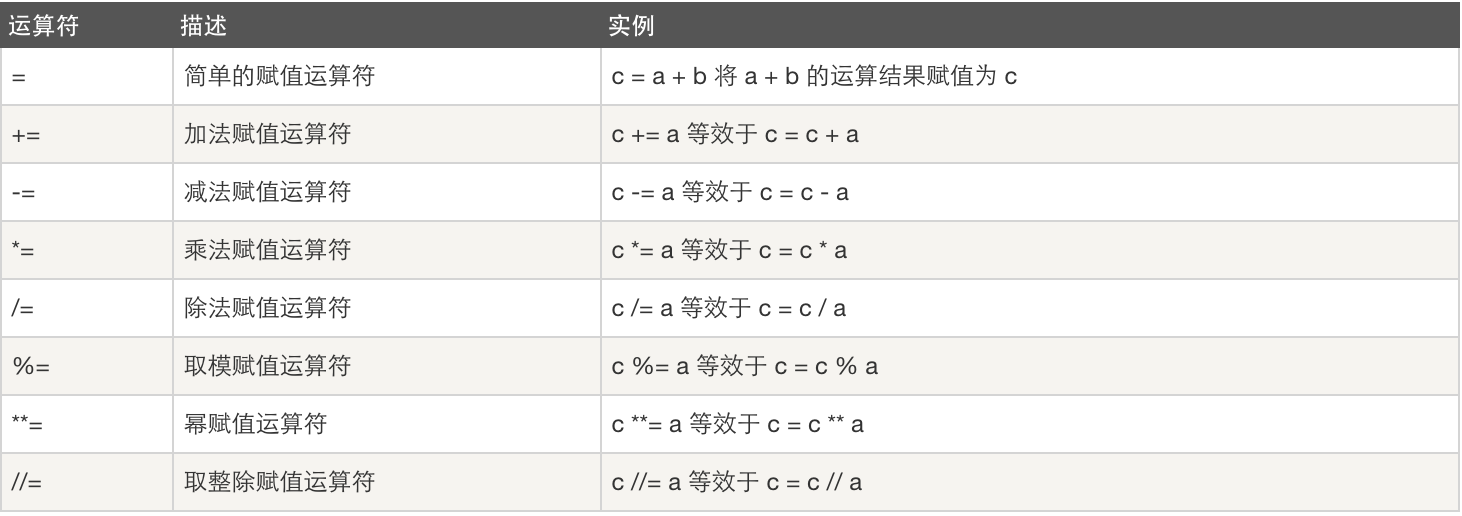
3、赋值运算
4、逻辑运算

5、成员运算

基本数据类型
1、数字
int(整型)
在32位机器上,整数的位数为32位,取值范围为-2**31~2**31-1,即-2147483648~2147483647
在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1,即-9223372036854775808~9223372036854775807
在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1,即-9223372036854775808~9223372036854775807
int的常用功能
#加法实际上是调用__add__,先了解 n1 = 123 n2 = 456 print(n1 + n2) print(n1.__add__(n2)) #ret——获取可表示的二进制最短位数 n1 = 4 #0000 0100 ret = n1.bit_length() print(ret)
2、布尔值
真或假
1 或 0
3、字符串
"hello world"
字符串常用功能:
- 索引
- 切片
#——索引——
s = "alex"
print(s[0])
print(s[1])
print(s[2])
print(s[3])
# print(s[4])
# 超出范围会报错:IndexError: string index out of range
#显示范围
ret = len(s)
print(ret)
#——切片——
s = "alex"
# 0=< 0,1 < 2
print(s[0:2])
#——for循环——
s = "alex"
for item in s:
print(item)
- 其它——移除空白,分割,长度
a1 = "sullivan"
#capitalize——首字母大写
ret = a1.capitalize()
print(ret)
#输出结果:Sullivan
a1 = "sullivan"
#center(self, width, fillchar=None):
#内容居中,width:总长度;fillchar:空白处填充内容,默认无
ret = a1.center(20,'*')
print(ret)
#输出结果:******sullivan******
a1 = "sullivan is sulli"
#count——子序列的个数
ret = a1.count("a")
print(ret)
#输出结果:1
ret = a1.count("su")
print(ret)
#输出结果:2
ret = a1.count("su",0,4)
print(ret)
#输出结果:1
a1 = "sullivan"
#endwith——是否已 xxx 结束
#startwith——是否已 xxx 起始
print(a1.endswith('n'))
#输出结果:True
print(a1.endswith('u'))
#输出结果:False
#获取字符串大于等于0,小于2的位置,
print(a1.endswith('u',0,2))
#输出结果:True
#content——将Tab键转换为空格
content = "hello 999"
print(content)
print(content.expandtabs())
print(content.expandtabs(20))
#find——寻找子序列位置,如果没找到,返回 -1
#rfind——从右向左找
s = "sullivan is sulli"
print(s.find("ll"))
#format——字符串格式化,动态参数,将函数式编程时细说
s = "hello {0},age {1}"
print(s)
#{0} 占位符
new1 = s.format('sullivan',19)
print(new1)
#输出结果:hello sullivan,age 19
#index——寻找子序列位置,如果没找到,报错
#和find功能一样,且find不报错,忽略掉就行
"""
都不用传参数
isalnum——判断是否是数字和字母
isalpha——判断是否是字母
isdigit——判断是否是数字
isspace——判断是否全是空格
istitle——判断是否是标题,首字母是否大写
isupper——判断是否全是大写
islower——判断是否全是小写
title——变标题
upper——变大写
lower——变小写
"""
a = "sullivan1"
print(a.isalnum())
print(a.isalpha())
print(a.isdigit())
print(a.isspace())
print(a.istitle())
print(a.isupper())
print(a.islower())
#join——连接
#li = ["prime","sullivan"] #列表类型中括号
li = ("prime","sullivan") #元组类型小括号
print("".join(li))
print("_".join(li))
print("***".join(li))
#ljust——内容左对齐,右侧填充
#rjust——内容右对齐,左侧填充
s = "Sullivan"
set = s.ljust(20,'_')
print(set)
#输出结果:Sullivan____________
set = s.rjust(20,'_')
print(set)
#输出结果:____________Sullivan
#lstrip——去除左边的空格
#rstrip——去除右边的空格
#strip——去除左右两边的空格
s = " sulli "
news = s.lstrip()
print(news)
news = s.rstrip()
print(news)
news = s.strip()
print(news)
#partition——按指定字符分割为前,中,后三部
#rpartition——从右向左找
s = "i love you"
ret = s.partition('love')
print(ret)
#输出结果:('i ', 'love', ' you') 元组类型
#replace——替换
s = "i love you"
ret = s.replace("i","I")
print(ret)
#输出结果:I love you
#split——按指定字符分割
#rsplit——从右向左
s = "sullisulli"
ret = s.split("l")
print(ret)
#输出结果:['su', '', 'isu', '', 'i']
ret = s.split("l",1)
print(ret)
#输出结果:['su', 'lisulli']
ret = s.rsplit("l",1)
print(ret)
#输出结果:['sullisul', 'i']
#swapcase——大写变小写,小写变大写
s = "Sullivan"
print(s.swapcase())
#输出结果:sULLIVAN
4、列表
创建列表
name_list = ['alex', 'seven', 'eric'] 或 name_list = list(['alex', 'seven', 'eric'])
基本操作
- 索引
- 切片
- 循环
name_list = ["prime","cirila","sullivan"]
#——索引——
print(name_list[0])
#输出结果:prime
#——切片——
print(name_list[0:2])
#输出结果:['prime', 'cirila']
print(name_list[2:len(name_list)])
#输出结果:['sullivan']
#——循环——
for i in name_list:
print(i)
"""
输出结果:
prime
cirila
sullivan
"""
- 追加
- 删除
- 长度
- 包含
name_list = ["prime","cirila","sullivan"]
#append——向后追加
name_list.append('seven')
name_list.append('seven')
name_list.append('seven')
print(name_list)
#count——元素出现的次数
print(name_list.count('seven'))
#extend——扩展,批量添加数据
temp = [111,222,33,44]
name_list.extend(temp)
print(name_list)
#index——获取指定元素的索引位置
print(name_list.index('cirila'))
#insert——向指定索引位置插入数据
name_list.insert(1,'SB')
print(name_list)
#pop——在原列表中移除掉最后一个元素,并将移除的元素赋值给a1
a1 = name_list.pop()
print(name_list)
print(a1)
#remove——移除从左边数第一个元素
name_list.remove('seven')
print(name_list)
#reverse——翻转
name_list.reverse()
print(name_list)
#sort——排序
# name_list.sort()
# print(name_list)
#因为数字和字符都存在所以出错,了解即可
#del——删除指定索引位置
print(name_list)
del name_list[1]
print(name_list)
del name_list[2:3]
print(name_list)
上面程序的输出结果 ['prime', 'cirila', 'sullivan', 'seven', 'seven', 'seven'] 3 ['prime', 'cirila', 'sullivan', 'seven', 'seven', 'seven', 111, 222, 33, 44] 1 ['prime', 'SB', 'cirila', 'sullivan', 'seven', 'seven', 'seven', 111, 222, 33, 44] ['prime', 'SB', 'cirila', 'sullivan', 'seven', 'seven', 'seven', 111, 222, 33] 44 ['prime', 'SB', 'cirila', 'sullivan', 'seven', 'seven', 111, 222, 33] [33, 222, 111, 'seven', 'seven', 'sullivan', 'cirila', 'SB', 'prime'] [33, 222, 111, 'seven', 'seven', 'sullivan', 'cirila', 'SB', 'prime'] [33, 111, 'seven', 'seven', 'sullivan', 'cirila', 'SB', 'prime'] [33, 111, 'seven', 'sullivan', 'cirila', 'SB', 'prime']
5、元组
创建元组
ages = (11, 22, 33, 44, 55) 或 ages = tuple((11, 22, 33, 44, 55))
特点
1、元组和列表几乎是一样的
2、列表是可以进行修改的,元组是不能修改的
基本操作:
- 索引
- 切片
- 循环
- 长度
- 包含
name_tuple = ('prime','cirila')
#——索引——
print(name_tuple[0])
#len,因为长度是2,但是字符的排序是从0开始的
print(name_tuple[len(name_tuple)-1])
#——切片——
print(name_tuple[0:1])
#——循环——
for i in name_tuple:
print(i)
#count——计算元素出现的个数
print(name_tuple.count('prime'))
#index——获取指定元素的索引位置
print(name_tuple.index('prime'))
#删除
#del name_tuple[0],不支持删除
#TypeError: 'tuple' object doesn't support item deletion
上面程序的输出结果
prime cirila ('prime',) prime cirila 1 0
6、字典(无序)
创建字典
person = {"name": "mr.hou", 'age': 18}
或
person = dict({"name": "mr.hou", 'age': 18})
常用操作:
- 索引
- 新增
- 删除
- 键、值、键值对
- 循环
- 长度
user_info = {
"name":"ciri",
"age":16,
"gender":'W'
}
#——索引——
print(user_info['name'])
#——切片——,不能用。因为切片是连续的,自己定义的key没有连续性
#——循环——,默认输出所有的key
for i in user_info:
print(i)
for i in user_info.keys():
print(i)
"""
输出结果都是
name
age
gender
"""
#输出所有的值
for i in user_info.values():
print(i)
"""
输出结果
ciri
16
W
"""
#输出所有的键值对
for k,v in user_info.items():
print(k,v)
"""
输出结果
name ciri
age 16
gender W
"""
#获取所有的键key,值value,键值对
print (user_info.keys())
print (user_info.values())
print (user_info.items())
"""
输出结果
dict_keys(['name', 'age', 'gender'])
dict_values(['ciri', 16, 'W'])
dict_items([('name', 'ciri'), ('age', 16), ('gender', 'W')])
"""
#clear——清楚所有的内容
user_info.clear()
print(user_info)
#get——根据key获取值,如果key不存在,可指定一个默认值,不指定会返回None
val = user_info.get('age')
print(val)
val = user_info.get('age111')
print(val)
val = user_info.get('age111','123')
print(val)
"""
输出结果
16
None
123
"""
#索引取值时key不存在,会报错;get则会返回none,所以推荐用get
#has_key 检查字典中指定key是否存在,python3里没有了,但是可以用in代替
ret = 'age' in user_info.keys()
print(ret)
#update——更新
print(user_info)
test = {
"a1": 123,
"a2": 456
}
user_info.update(test)
print(user_info)
"""
输出结果
{'name': 'ciri', 'age': 16, 'gender': 'W'}
{'name': 'ciri', 'age': 16, 'gender': 'W', 'a1': 123, 'a2': 456}
"""
#del——删除指定索引的键值对
del test['a1']
print(test)
#pop——获取并在字典中移除,可以传参数,移除指定的值
#popitem——不能传参数,从尾部移除
set = user_info.popitem()
print(set)
print(user_info)
set = user_info.pop('name')
print(set)
print(user_info)
"""
输出结果
('gender', 'W')
{'name': 'ciri', 'age': 16}
ciri
{'age': 16}
"""
其它
1、for循环
用户按照顺序循环可迭代对象中的内容,
PS:break、continue
li = [11,22,33,44]
for item in li:
print item
2、enumrate
为可迭代对象添加序号enumerrate在循环的时候会加上一列,相当于变成了键值对
li = ["电脑","鼠标垫","U盘","游艇"]
for key,item in enumerate(li,start=1):
print(key,item)
inp = input("请输入商品:")
#字符串(str)转换成数字(int)
inp_num = int(inp)
print(li[inp_num-1])
3、range和xrange
指定范围生成指定的数字
python2.7
range在2.7里,创建指定范围里的所有数
xrang只在2.7里面有,不会一次性创建所有的数
python3
在python3中只有range,且效果等同于27里的xrange
print range(1, 10) # 结果:[1, 2, 3, 4, 5, 6, 7, 8, 9] print range(1, 10, 2) # 结果:[1, 3, 5, 7, 9] print range(30, 0, -2) # 结果:[30, 28, 26, 24, 22, 20, 18, 16, 14, 12, 10, 8, 6, 4, 2]
练习题
一、元素分类
有如下值集合 [11,22,33,44,55,66,77,88,99,90...],将所有大于 66 的值保存至字典的第一个key中,将小于 66 的值保存至第二个key的值中。
即: {'k1': 大于66的所有值, 'k2': 小于66的所有值}
#写法一
li = [11,22,33,44,55,66,77,88,99,90]
l1 = []
l2 = []
for i in li:
if i <= 66:
l1.append(i)
else:
l2.append(i)
temp = {"k1": l1,"k2": l2}
print(temp)
#写法二
li = [11,22,33,44,55,66,77,88,99,90]
dic = {
"k1": [],
"k2": [],
}
for i in li:
if i <=66:
dic['k1'].append(i)
else:
dic['k2'].append(i)
print(dic)
二、查找
查找列表中元素,移除每个元素的空格,并查找以 a或A开头 并且以 c 结尾的所有元素。
li = ["alec", " aric", "Alex", "Tony", "rain"]
tu = ("alec", " aric", "Alex", "Tony", "rain")
dic = {'k1': "alex", 'k2': ' aric', "k3": "Alex", "k4": "Tony"}
li = ["alec", " aric", "Alex", "Tony", "rain"]
tu = ("alec", " aric", "Alex", "Tony", "rain")
dic = {'k1': "alex", 'k2': ' aric', "k3": "Alex", "k4": "Tony"}
for i in li:
b = i.strip()
b = b.title()
if b.endswith("c") and b.startswith("A"):
print(b)
for i in tu:
b = i.strip()
b = b.title()
if b.endswith("c") and b.startswith("A"):
print(b)
for i in dic.values():
b = i.strip()
b = b.title()
if b.endswith("c") and b.startswith("A"):
print(b)
三、输出商品列表,用户输入序号,显示用户选中的商品
商品 li = ["手机", "电脑", '鼠标垫', '游艇']
li = ["电脑","鼠标垫","U盘","游艇"]
for i,j in enumerate(li,start=1):
print(i,j)
inp = input("请输入商品:")
num = int(inp)
len_li = len(li)
if num > 0 and num <= len_li:
print(li[num-1])
else:
print("商品不存在!")
四、购物车
功能要求:
- 要求用户输入总资产,例如:2000
- 显示商品列表,让用户根据序号选择商品,加入购物车
- 购买,如果商品总额大于总资产,提示账户余额不足,否则,购买成功。
- 附加:可充值、某商品移除购物车
goods = [ {"name": "电脑", "price": 1999}, {"name": "鼠标", "price": 10}, {"name": "游艇", "price": 20}, {"name": "美女", "price": 998}, ]
car_list = {} #{"商品名":{"价格" : 699,"个数" : 1}}
i1 = input("请输入您的总资产:")
asset_all = int(i1)
goods = [
{"name": "电脑", "price": 1999},
{"name": "鼠标", "price": 10},
{"name": "游艇", "price": 20},
{"name": "美女", "price": 998},
]
for i in goods:
print(i["name"],i["price"])
#输出商品列表
#循环购物
while True:
i2 = input("请选择商品,按y退出")
if i2 == "y":
break
for item in goods:
if item["name"] == i2:
name = item["name"]
#判断购物车是否有此类商品
if name in car_list.keys():
car_list[name]["num"] = car_list[name]["num"] + 1
else:
car_list[name] = {"num":1,"single_price":item["price"]}
print("购物车:",car_list)
#结算
all_price = 0
for k,v in car_list.items():
n = v["single_price"]
m = v["num"]
all_sum = m * n
all_price = all_price + all_sum
if all_price > asset_all:
print("购买失败——穷逼")
else:
print("购买成功")
五、用户交互,显示省市县三级联动的选择
dic = {
"河北": {
"石家庄": ["鹿泉", "藁城", "元氏"],
"邯郸": ["永年", "涉县", "磁县"],
},
"河南": {
"郑州": ["中原", "惠济", "金水"],
"开封": ["龙庭", "金明", "顺河"],
},
"山西": {
"太原": ["小店", "迎泽", "杏花岭"],
"大同": ["南郊", "新荣", "阳高"],
}
}
dic = {
"河北": {
"石家庄": ["鹿泉", "藁城", "元氏"],
"邯郸": ["永年", "涉县", "磁县"],
},
"河南": {
"郑州": ["中原", "惠济", "金水"],
"开封": ["龙庭", "金明", "顺河"],
},
"山西": {
"太原": ["小店", "迎泽", "杏花岭"],
"大同": ["南郊", "新荣", "阳高"],
}
}
#循环输出所有的省
for x in dic:
print(x)
i1 = input("请输入省份:")
#循环输出选择省的市
a = dic[i1]
for y in a:
print(y)
i2 = input("请输入市:")
#循环输出选择市的区
a = dic[i1][i2]
for z in a:
print(z)
i3 = input("请输如区:")
print("地址为:",i1,i2,i3)