Redis数据类型
typedef struct redisObject { unsigned [type] 4; unsigned [encoding] 4; unsigned [lru] REDIS_LRU_BITS; int refcount; void *ptr; } robj;
- type:数据类型,就是我们熟悉的string、hash、list等。
- encoding:内部编码,其实就是本文要介绍的数据结构。指的是当前这个value底层是用的什么数据结构。因为同一个数据类型底层也有多种数据结构的实现,所以这里需要指定数据结构。
- REDIS_LRU_BITS:当前对象可以保留的时长。这个我们在后面讲键的过期策略的时候讲。
- refcount:对象引用计数,用于GC。
- ptr:指针,指向以encoding的方式实现这个对象的实际地址。
Redis支持5种数据类型,它们描述如下:


Strings - 字符串

- 在Redis内部,字符串对象的编码可以是int、(动态字符串)raw或者embstr。

- Redis会根据存储的数据及用户的操作指令自动选择合适的结构:
- int:存放整数类型;
- SDS:存放浮点、字符串、字节类型;
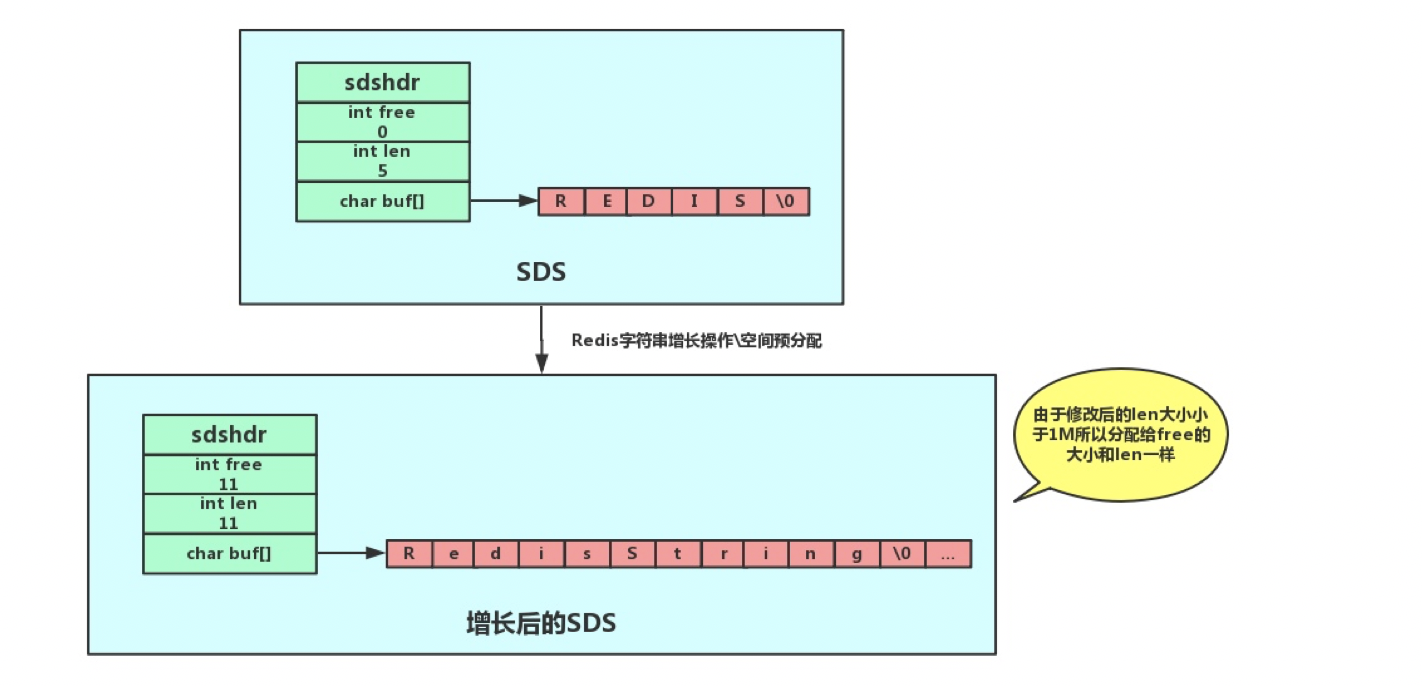
- 如果修改后len长度将小于1M,这时分配给free的大小和len一样,例如修改过后为10字节, 那么给free也是10字节,buf实际长度变成了10 + 10 + 1 = 21byte
- 如果修改后len长度将大于等于1M,这时分配给free的长度为1M,例如修改过后为30M,那么给free是1M.buf实际长度变成了30M + 1M + 1byte
struct SDS<T> { T capacity; // 数组容量 T len; // 数组长度 byte flags; // 特殊标识位,不理睬它 byte[] content; // 数组内容 }
- 快速获取字符串的长度
- C语言获取字符串的长度是通过遍历字符数组然后计数实现的,时间复杂度为O(n),对于SDS,由于len的存在,我们只需要读取len的值即可,时间复杂度为O(1)。
- 解决了c语言字符串拼接缓冲区溢出的问题
- 在c语言中。俩个字符串的拼接通过使用stract函数来完成,在拼接之前需要定义一个足够大的数组用来存在拼接好的字符串,如果没有分配足够长度的内存空间,那么拼接好的字符串放不进去。就会造成缓存区溢出,对于SDS,在进行拼接的时候,会首先查看free和len的情况,在拼接的时候通过len获取到字符串的长度,free获取到字符数组的剩余空间,可以做到精确的拼接操作
- 修改字符串减少内存分配次数
- 在c语言中。因为字符串的长度没有记录,所以每次在修改字符串的时候都需要重新开辟合适的内存,为什么要开辟呢??
- 因为如果不开辟新的内存大小,字符串增大会造成内存溢出,缩短会造成内存泄漏,
- 空间预分配:对字符串进行空间扩展的时候,扩展的内存比实际需要的多,这样可以减少连续执行字符串增长操作所需的内存重分配次数。
- 惰性空间释放:对字符串进行缩短操作时,程序不立即使用内存重新分配来回收缩短后多余的字节,而是使用 free 属性将这些字节的数量记录下来,等待后续使用。(当然SDS也提供了相应的API,当我们有需要时,也可以手动释放这些未使用的空间。)
- 二进制安全。
- c语言是二进制不安全的,因为c语言是以空字符来作为字符串结束的标记,像图片,音乐这些文件,内容中间可能包含空字符串,所以c语言只能存取一些文本文件,但是对于SDS而言,它是通过len的长度来记录字符串的长度的,所以SDS可以存取图片或者音乐等二进制文件。
1 redis 127.0.0.1:6379> SET name "hello" 2 OK 3 redis 127.0.0.1:6379> GET name 4 "hello"
列表 (Lists)
Redis 列表仅仅是按照插入顺序排序的字符串列表。可以添加一个元素到 Redis 列表的头部 (左边) 或者尾部 (右边)。
LPUSH 命令用于插入一个元素到列表的头部,RPUSH 命令用于插入一个元素到列表的尾部。当这两个命令操作在一个不存在的键时,将会创建一个新的列表。同样,如果一个操作会清空列表,那么该键将会从键空间 (key space) 移除。这些是非常方便的语义,因为列表命令如果使用不存在的键作为参数,就会表现得像命令运行在一个空列表上一样。
1 redis 127.0.0.1:6379> lpush listtest test1 2 (integer) 1 3 redis 127.0.0.1:6379> lpush listtest test2 4 (integer) 2 5 redis 127.0.0.1:6379> lpush listtest test3 6 (integer) 3 7 redis 127.0.0.1:6379> lrange listtest 0 -1 8 9 1 "test1" 10 2 "test2" 11 3 "test3"
集合 (Sets)
Redis 集合是没有顺序的字符串集合 (collection)。可以在 O(1) 的时间复杂度添加、删除和测试元素存在与否 (不管集合中有多少元素都是常量时间)。
Redis 集合具有你需要的不允许重复成员的性质。多次加入同一个元素到集合也只会有一个拷贝在其中。实际上,这意味着加入一个元素到集合中并不需要检查元素是否已存在。
Redis 集合非常有意思的是,支持很多服务器端的命令,可以在很短的时间内和已经存在的集合一起计算并集,交集和差集。
redis 127.0.0.1:6379> sadd setdemo set1 (integer) 1 redis 127.0.0.1:6379> sadd setdemo set2 (integer) 1 redis 127.0.0.1:6379> smembers setdemo 1) "set1" 2) "set2"
Hashes - 哈希值
Redis的哈希键值对的集合。 Redis的哈希值是字符串字段和字符串值之间的映射,所以它们被用来表示对象。
redis 127.0.0.1:6379> HMSET user:1 username testname password 123456 OK redis 127.0.0.1:6379> HGETALL user:1 1) "testname" 2) "123456"
有序集合 (Sorted sets)
Redis 有序集合和 Redis 集合类似,是非重复字符串集合 (collection)。不同的是,每一个有序集合的成员都有一个关联的分数 (score),用于按照分数高低排序。尽管成员是唯一的,但是分数是可以重复的。
对有序集合我们可以通过很快速的方式添加,删除和更新元素 (在和元素数量的对数成正比的时间内)。由于元素是有序的而无需事后排序,你可以通过分数或者排名 (位置) 很快地来获取一个范围内的元素。访问有序集合的中间元素也是很快的,所以你可以使用有序集合作为一个无重复元素,快速访问你想要的一切的聪明列表:有序的元素,快速的存在性测试,快速的访问中间元素!
总之,有序集合可以在很好的性能下,做很多别的数据库无法模拟的事情。
redis 127.0.0.1:6379> zadd list 0 name1 (integer) 1 redis 127.0.0.1:6379> zadd list 0 name2 (integer) 1 redis 127.0.0.1:6379> ZRANGEBYSCORE list 0 1000 1) "name1" 2) "name2"