前言
众所周知,HDFS的扩展性问题一直是一个被谈论已久的问题。HDFS NN内部的全局单一锁的设计在数以亿计规模的block内存对象的情况下,存在着不小的性能瓶颈问题。当NN在处理A用户的写请求操作时,意味着其它用户的写请求将会被block住。当然这个时候,我们可能会采用一些横向扩展方案,诸如HDFS Federation或者Router Based Federation这类的方案来解决这里的扩展性问题。不过今天笔者要谈论的是社区最近提出的一种新的方案(HDFS-14703: NameNode Fine-Grained Locking via Metadata Partitioning):基于NN Namespace的内部partition来将全局锁进行细粒度化地拆分,从而解决NN的扩展性问题。
HDFS NN的现有请求处理模式
我们先来回顾回顾HDFS NN的现有请求处理模式。简单地理解,一个整体大的命名空间数据(元数据),一个全局锁,然后对于客户端写请求,可以支持读操作共享,但是写操作则是互斥的。
简单的过程图如下所示:
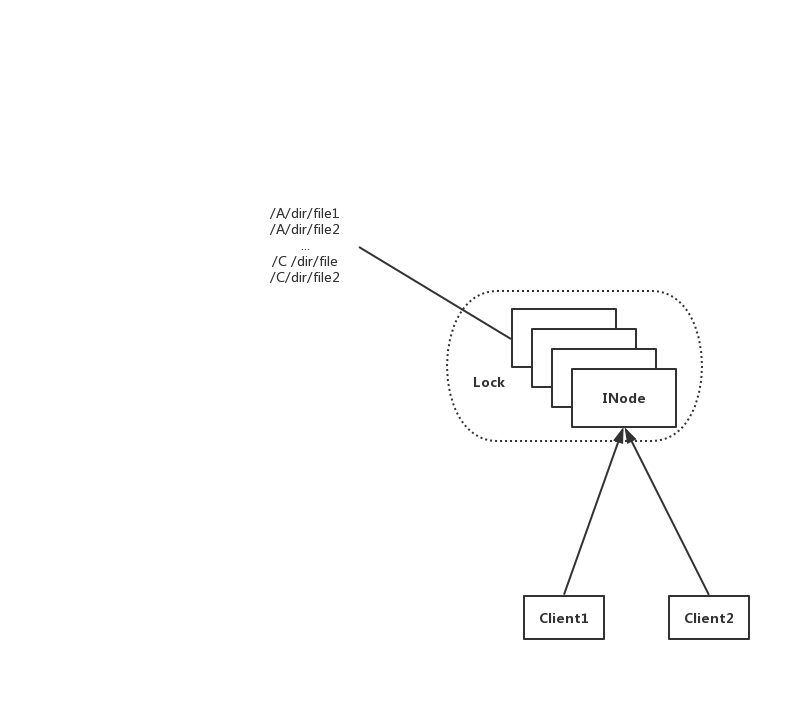
在上图中,为了保证元数据更新的原子性,NN并没有做到完全并行地处理来自Client1和Client2所发来的写请求。但是仔细细看这个过程,有些情况其实我们并不需要对这个过程进行全局加锁的操作。比如当Client1和Client2所操作的数据文件完全没有关联的时候,我们其实是不需要做全局锁控制的。在这种情况下,我们完全可以允许Client1和Client2的请求并发被处理。
上面谈到的问题本质上来说是锁粒度的问题了,全局单一锁是在设计上是一种较为粗粒度,它虽然控制起来比较简单、直接,但是有时候效率不太高。而细粒度的锁则是它功能弊端的一个弥补,本文讨论的基于NN Namespace的内部partition也是基于这个出发点而设计的。
基于Namespace的内部partition来细粒度化锁
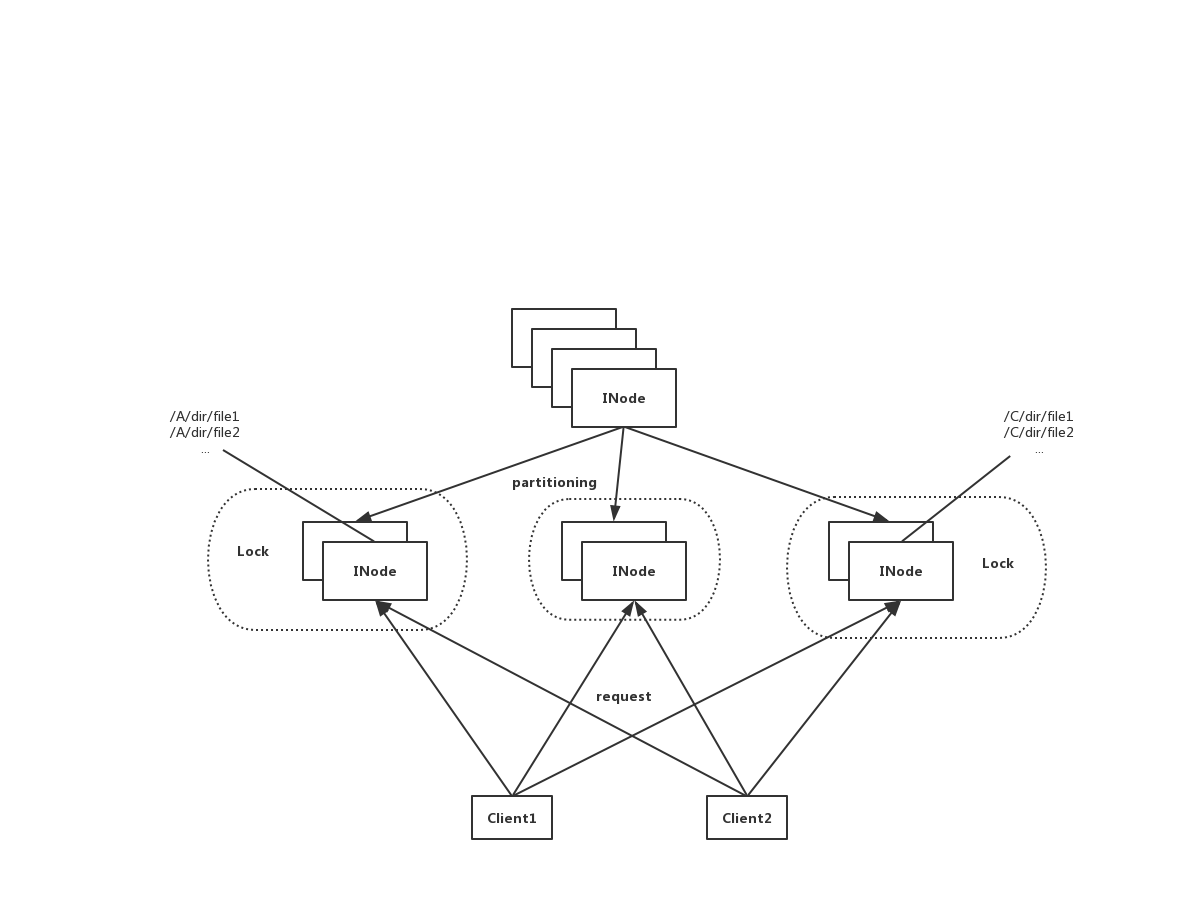
相比于原有的现状模式1个大的命名空间+1个大的全局锁,我们的目标是多个分区的命名空间+多个对应的细粒度锁。因为不同命名空间下它们的元数据是互相独立的,所以不同partition下的元数据操作可以被并发地执行,而对于同个partition内的元数据操作,则用细粒度锁来进行控制。细粒度锁对于partition namespace的控制类似于原先全局锁对于大命名空间的处理模式。
OK,在这里一个大的优化目标已经清晰了,问题来了:我们要用什么办法来做Namespace的partition操作?以哪个标准作为partition的划分依据呢?Full Path Name?INode Id?
我们在考虑以什么标准来作为划分的依据时,我们的目标是尽可能地让不同partition 内的namespace能够独立地被操作执行。近一步地来说,我们希望把具有相关性的文件目录数据分到一个partition内。这样的话,当我对A partition目录做操作时不会影响到B partition下的目录。那么我们如何去表现这种相关性呢?
当然我们要利用HDFS内部INode对象内部的已有属性做标识,有以下两种partition key的定义:
第一种,用INode的full path name来做,具有相似前缀的path会被分入一个partition。这个方案实现起来也必将简单。但是这个方案有个弊端,path name是可变的,它是可以被rename的,如果rename成其它名字了,这会导致大量的re-partition动作的。
第二种,鉴于第一种方案的弊端,我们可以考虑用一种恒定的标识来代表其所在的实际目录,这里我们可以用INodeID。INodeID如何表现出相关性呢?在path name中,前缀字符匹配代表着目录的相关性,转化成INodeID的话,就是INodeID的组合键模式了,如下:
key(f) = <ppId, pId, selfId>
ppId: 父亲的父亲节点INodeId
pId: 父节点INodeId
selfId: 自身INodeId
在key的定义中,ppId和pId的存在能够使得按照此key划分出的partition将会具有相关性。
不过这里还有一些个别处理情况需要横跨多个partition进行协作的,比如rename的操作,从source partition rename到target partition,这种情况要获取多个partition的锁了。但是在锁粒度层面而言,还是要比之前全局锁模式要好很多的。
Partition后的锁控制模式如下所示:
NN新锁结构的调整
在现有NN的内部元数据存储结构下,我们是用其内部自定义的LightWeightGSet结构来做元数据存储的,然后额外用ReadWriteLock做线程安全的控制的。
在细粒度化锁的处理之后,我们会有以下几点的改动:
- 在Gset结构之上,引入一个新的存储结构RangeMap,来存储各个partition下的GSet。
RangMap<PartitionId, GSet>
- 每个GSet会有其对应的锁实例。
- 在这里我们同时要保证RangMap的线程安全性,所以在这里我们要定义额外的锁来控制RangMap。系统首先要获取RangeMap的锁来获取我们想要操作的GSet集合,然后再获取每个GSet的分区独立锁做下一步地更新操作。
这套设计方案目前还没有在社区完全实现,不过总体看来是一个很棒的idea,而且也没有对现有NN元数据结构做大的改动。
引用
[1].https://issues.apache.org/jira/browse/HDFS-14703 . NameNode Fine-Grained Locking via Metadata Partitioning