欢迎转载,转载请注明出处,徽沪一郎。
概要
Hadoop2中的Yarn是一个分布式计算资源的管理平台,由于其有极好的模型抽象,非常有可能成为分布式计算资源管理的事实标准。其主要职责将是分布式计算集群的管理,集群中计算资源的管理与分配。
Yarn为应用程序开发提供了比较好的实现标准,Spark支持Yarn部署,本文将就Spark如何实现在Yarn平台上的部署作比较详尽的分析。
Spark Standalone部署模式回顾
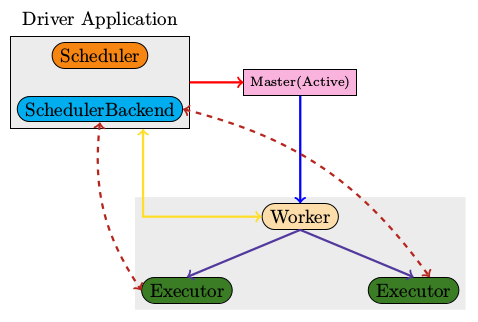
上图是Spark Standalone Cluster中计算模块的简要示意,从中可以看出整个Cluster主要由四种不同的JVM组成
- Master 负责管理整个Cluster,Driver Application和Worker都需要注册到Master
- Worker 负责某一个node上计算资源的管理,如启动相应的Executor
- Executor RDD中每一个Stage的具体执行是在Executor上完成
- Driver Application driver中的schedulerbackend会因为部署模式的不同而不同
换个角度来说,Master对资源的管理是在进程级别,而SchedulerBackend则是在线程的级别。
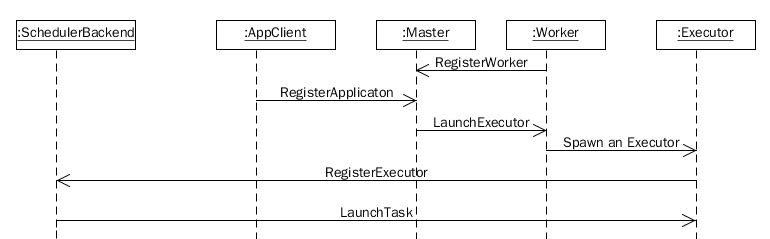
启动时序图
YARN的基本架构和工作流程
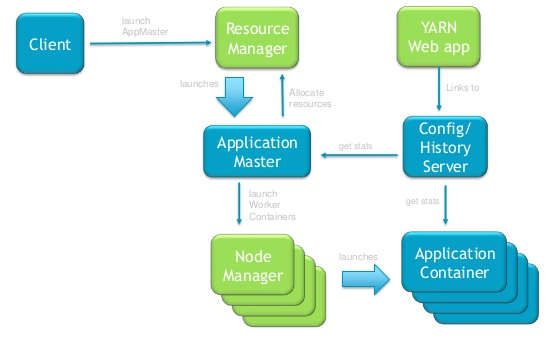
YARN的基本架构如上图所示,由三大功能模块组成,分别是1) RM (ResourceManager) 2) NM (Node Manager) 3) AM(Application Master)
作业提交
- 用户通过Client向ResourceManager提交Application, ResourceManager根据用户请求分配合适的Container,然后在指定的NodeManager上运行Container以启动ApplicationMaster
- ApplicationMaster启动完成后,向ResourceManager注册自己
- 对于用户的Task,ApplicationMaster需要首先跟ResourceManager进行协商以获取运行用户Task所需要的Container,在获取成功后,ApplicationMaster将任务发送给指定的NodeManager
- NodeManager启动相应的Container,并运行用户Task
实例
上述说了一大堆,说白了在编写YARN Application时,主要是实现Client和ApplicatonMaster。实例请参考github上的simple-yarn-app.
Spark on Yarn
结合Spark Standalone的部署模式和YARN编程模型的要求,做了一张表来显示Spark Standalone和Spark on Yarn的对比。
| Standalone | YARN | Notes |
|---|---|---|
| Client | Client | standalone请参考spark.deploy目录 |
| Master | ApplicationMaster | |
| Worker | ExecutorRunnable | |
| Scheduler | YarnClusterScheduler | |
| SchedulerBackend | YarnClusterSchedulerBackend |
作上述表格的目的就是要搞清楚为什么需要做这些更改,与之前Standalone模式间的对应关系是什么。代码走读时,分析的重点是ApplicationMaster, YarnClusterSchedulerBackend和YarnClusterScheduler
一般来说,在Client中会显示的指定启动ApplicationMaster的类名,如下面的代码所示
ContainerLaunchContext amContainer =
Records.newRecord(ContainerLaunchContext.class);
amContainer.setCommands(
Collections.singletonList(
"$JAVA_HOME/bin/java" +
" -Xmx256M" +
" com.hortonworks.simpleyarnapp.ApplicationMaster" +
" " + command +
" " + String.valueOf(n) +
" 1>" + ApplicationConstants.LOG_DIR_EXPANSION_VAR + "/stdout" +
" 2>" + ApplicationConstants.LOG_DIR_EXPANSION_VAR + "/stderr"
)
);
但在yarn.Client中并没有直接指定ApplicationMaster的类名,是通过ClientArguments进行了封装,真正指定启动类的名称的地方在ClientArguments中。构造函数中指定了amClass的默认值是org.apache.spark.deploy.yarn.ApplicationMaster
实例说明
将SparkPi部署到Yarn上,下述是具体指令。
$ SPARK_JAR=./assembly/target/scala-2.10/spark-assembly-0.9.1-hadoop2.0.5-alpha.jar
./bin/spark-class org.apache.spark.deploy.yarn.Client
--jar examples/target/scala-2.10/spark-examples-assembly-0.9.1.jar
--class org.apache.spark.examples.SparkPi
--args yarn-standalone
--num-workers 3
--master-memory 4g
--worker-memory 2g
--worker-cores 1
从输出的日志可以看出, Client在提交的时候,AM指定的是org.apache.spark.deploy.yarn.ApplicationMaster
13/12/29 23:33:25 INFO Client: Command for starting the Spark ApplicationMaster: $JAVA_HOME/bin/java -server -Xmx4096m -Djava.io.tmpdir=$PWD/tmp org.apache.spark.deploy.yarn.ApplicationMaster --class org.apache.spark.examples.SparkPi --jar examples/target/scala-2.9.3/spark-examples-assembly-0.8.1-incubating.jar --args 'yarn-standalone' --worker-memory 2048 --worker-cores 1 --num-workers 3 1> /stdout 2> /stderr
小结
spark在提交时,所做的资源申请是一次性完成的,也就是说对某一个具体的Application,它所需要的Executor个数是一开始就是计算好,整个Cluster如果此时能够满足需求则提交,否则进行等待。而且如果有新的结点加入整个cluster,已经运行着的程序并不能使用这些新的资源。缺少rebalance的机制,这点上storm倒是有。
参考资料
- Launch Spark On YARN http://spark.apache.org/docs/0.9.1/running-on-yarn.html
- Getting started Writing YARN Application http://hortonworks.com/blog/getting-started-writing-yarn-applications/
- 《Hadoop技术内幕 深入解析YARN架构设计与实现原理》 董西成著
- YARN应用开发流程 http://my.oschina.net/u/1434348/blog/193374 强烈推荐!!!