XML的学习目标:
能用XML描述现实中的有层次关系的数据
能使用程序读取到XML中表示的数据(解析Parser)
一、XML是什么?作用是什么?
1、XML是指可扩展标记语言(eXtensible Markup Language),用户自定义的标签.相对于HTML来讲的。
2、XML被设计的宗旨是表示数据。HTML是用来显示数据的。目前经常使用的XML版本是1.0
3、XML除了表示数据外。在实际的企业开发中,主要用XML作为程序的配置文件。

二、XML的基本语法

1、文档声明:
作用:用于标识该文档是一个XML文档。
注意事项:声明必须出现在文档的第一行(之前连空行都不能有,也不能有任何的注释)
最简单的XML声明:<?xml version="1.0"?>
声明中的encoding属性:说明解析当前XML文档时所使用的编码。默认是UTF-8。如果不声明的话,保存在磁盘上的文件编码要与声明的编码一致。
声明中的standalone属性:说明XML文档是否是独立的。(了解)
2、元素

结束标签不能省略
一个XML文档必须且只能有一个根标签
XML文档中不会忽略回车和换行及空格
标签的命名规范:元素(标签)的名称可以包含字母、数字、减号、下划线和英文句点。严格区分大小写。

3、元素的属性
元素的属性取值一定要用引号引起来(单引号或双引号)
属性的命名规则跟元素的一致
属性不允许重复
属性的值可以用子标签代替

4、注释
与HTML中的注释完全一致:<!--这是注释-->
注释不能嵌套
5、CDATA区
CDATA是Character Data的缩写。
作用:CDATA区中的内容都是文本。
语法:
<![CDATA[
文本内容
]]>
6、特殊字符

7、处理指令(PI:Processing Instruction)
处理指令,简称PI(Processing Instruction)。
作用:用来指挥软件如何解析XML文档。
语法:必须以“<?”作为开头,以“?>”作为结尾。

三、DTD约束(看懂DTD就ok)
1、DTD:Document Type Definition
2、作用:约束XML的书写规范。
3、DTD文件保存到磁盘时,必须使用UTF-8编码



4、DTD的语法细节
- 定义元素
语法:<!ELEMENT 元素名称 使用规则>
使用规则:
(#PCDATA):指示元素的主体内容只能是普通的文本.(Parsed Character Data)
EMPTY:指示元素的不能有主体内容。
ANY:用于指示元素的主体内容为任意类型
(子元素) :指示元素中包含的子元素 。如果子元素用逗号分开,说明必须按照声明顺序去编写XML文档 如果子元素用“|”分开,说明任选其一。 用+(一次或者多次)、*、?来表示元素出现的次数
定义元素的属性(attribute)
语法:<!ATTLIST 哪个元素的属性
属性名1 属性值类型 设置说明
属性名2 属性值类型 设置说明
>

属性值类型:
CDATA:说明该属性的取值为一个普通文本
ENUMERATED (DTD没有此关键字):语法:<!ATTLIST 元素名称 (值1|值2) "值1">
ID:属性的取值不能重复
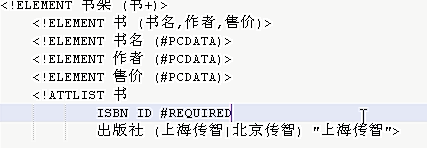
设置说明:
#REQUIRED:表示该属性必须出现
#IMPLIED:属性可有可无
#FIXED:表示属性的取值为一个固定值 语法:#FIXED "固定值"
直接值:表示属性的取值为该默认值
定义实体
关键字ENTITY
实体的定义分为引用实体和参数实体
引用实体:
作用:在DTD中定义,在XML中使用
语法:<!ENTITY 实体名称 "实体内容">
在XML中使用:&实体名称;
参数实体:
作用:在DTD中定义,在DTD中使用
语法:<!ENTITY % 实体名称 "实体内容">
在DTD中使用:%实体名称;
5、XML的解析方式:原理





package com.jaxp; import java.io.IOException; import javax.print.Doc; import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import javax.xml.parsers.ParserConfigurationException; import javax.xml.transform.Transformer; import javax.xml.transform.TransformerConfigurationException; import javax.xml.transform.TransformerException; import javax.xml.transform.TransformerFactory; import javax.xml.transform.dom.DOMSource; import javax.xml.transform.stream.StreamResult; import org.w3c.dom.Document; import org.w3c.dom.Element; import org.w3c.dom.Node; import org.w3c.dom.NodeList; import org.xml.sax.SAXException; public class JaxpDemo { public static void main(String[] args) throws Exception { // 获得解析工厂DocumentBuilderFactory DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); // 获得解析器 DocumentBuilder newDocumentBuilder = null; Document document = null; try { newDocumentBuilder = factory.newDocumentBuilder(); } catch (ParserConfigurationException e) { e.printStackTrace(); } // 解析指定的XML文档,得到代表内存DOM树的Document对象 try { document = newDocumentBuilder.parse("src/book.xml"); } catch (SAXException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } test1(document); test2(document); test3(document); test4(document); test5(document); test6(document); test7(document); } public static void test1(Document doc) { // 获得所有作者节点 NodeList noteList = doc.getElementsByTagName("作者"); // 打印第二个作者节点 Node item = noteList.item(1); // 打印第二个作者节点内容 System.out.println(item.getTextContent()); } public static void test2(Node node) { // 判断当前节点是不是一个元素节点 short nodeType = node.getNodeType(); if (nodeType == Node.ELEMENT_NODE) { // 如果是:打印他的名称 System.out.println(node.getNodeName()); } // 如果不是:找到他们的孩子 NodeList childNodes = node.getChildNodes(); // 遍历孩子:递归 for (int i = 0; i < childNodes.getLength(); i++) { test2(childNodes.item(i)); } } // 修改某个元素节点的主体,把第一本书的售价改成20元 public static void test3(Document doc) throws Exception { NodeList noteList = doc.getElementsByTagName("售价"); Node node = noteList.item(0); node.setTextContent("20元"); // 把内存中的Document树写回XML文件中 TransformerFactory factory = TransformerFactory.newInstance(); Transformer transformer = factory.newTransformer(); transformer.transform(new DOMSource(doc), new StreamResult( "src/book.xml")); } // 向指定元素节点添加子元素,<内部价> public static void test4(Document doc) { Element element = doc.createElement("内部价"); element.setTextContent("10元"); Node item = doc.getElementsByTagName("书").item(0); item.appendChild(element); // 把内存中的Document树写回XML文件中 TransformerFactory factory = TransformerFactory.newInstance(); Transformer transformer = null; try { transformer = factory.newTransformer(); } catch (TransformerConfigurationException e) { e.printStackTrace(); } try { transformer.transform(new DOMSource(doc), new StreamResult( "src/book.xml")); } catch (TransformerException e) { e.printStackTrace(); } } // 指定元素节点增加同级元素节点 public static void test5(Document doc) { Element element = doc.createElement("批发价"); element.setTextContent("7元"); Node item = doc.getElementsByTagName("售价").item(0); // 在之前增加同级元素,该方法应该是父元素调用 item.getParentNode().insertBefore(element, item); // 把内存中的Document树写回XML文件中 TransformerFactory factory = TransformerFactory.newInstance(); Transformer transformer = null; try { transformer = factory.newTransformer(); } catch (TransformerConfigurationException e) { e.printStackTrace(); } try { transformer.transform(new DOMSource(doc), new StreamResult( "src/book.xml")); } catch (TransformerException e) { e.printStackTrace(); } } // 删除指定元素:删除内部价 public static void test6(Document doc) { Node item = doc.getElementsByTagName("售价").item(0); item.getParentNode().removeChild(item); // 把内存中的Document树写回XML文件中 TransformerFactory factory = TransformerFactory.newInstance(); Transformer transformer = null; try { transformer = factory.newTransformer(); } catch (TransformerConfigurationException e) { e.printStackTrace(); } try { transformer.transform(new DOMSource(doc), new StreamResult( "src/book.xml")); } catch (TransformerException e) { e.printStackTrace(); } } // 操作XML文件的属性:打印第一本书的出版社 public static void test7(Document doc) { Node item = doc.getElementsByTagName("书").item(0); Element element = (Element) item; System.out.println(element.getAttribute("出版社")); element.setAttribute("类型", "惊悚"); // 把内存中的Document树写回XML文件中 TransformerFactory factory = TransformerFactory.newInstance(); Transformer transformer = null; try { transformer = factory.newTransformer(); } catch (TransformerConfigurationException e) { e.printStackTrace(); } try { transformer.transform(new DOMSource(doc), new StreamResult( "src/book.xml")); } catch (TransformerException e) { e.printStackTrace(); } } }
<?xml version="1.0" encoding="UTF-8" standalone="no"?> <书架> <书 ISBN="A" 出版社="河南出版社" 类型="惊悚"> <书名>Java开发</书名> <作者>王小狗</作者> </书> <书 ISBN="B" 出版社="河南大学出版社"> <书名>Java开发</书名> <作者>王大狗</作者> <售价>40.00元</售价> </书> </书架>


解析步骤示意图

package cn.sax.demo; import java.io.IOException; import javax.xml.parsers.ParserConfigurationException; import javax.xml.parsers.SAXParser; import javax.xml.parsers.SAXParserFactory; import org.xml.sax.Attributes; import org.xml.sax.ContentHandler; import org.xml.sax.Locator; import org.xml.sax.SAXException; import org.xml.sax.XMLReader; public class SaxDemo { public static void main(String[] args) throws IOException, ParserConfigurationException, SAXException { //得到解析工厂SAXParserFactory SAXParserFactory saxParserFactory = SAXParserFactory.newInstance(); //得到解析器SAXParser SAXParser saxParser = saxParserFactory.newSAXParser(); //得到XML读取器:XMLReader XMLReader xmlReader = saxParser.getXMLReader(); //注册内容处理器:ContentHandler xmlReader.setContentHandler(new MyContentHandler()); //读取XML文档 xmlReader.parse("src/book.xml"); } } class MyContentHandler implements ContentHandler{ /** * 解析到文档开始时被调用 */ public void startDocument() throws SAXException { System.out.println("解析到文档开始时...."); } /** * 解析到元素开始时被调用:qName元素名称 */ public void startElement(String uri, String localName, String qName, Attributes atts) throws SAXException { System.out.println("解析到元素开始时...."+qName); } /** * 解析到文本内容时被调用 */ public void characters(char[] ch, int start, int length) throws SAXException { System.out.println("文本内容"+new String(ch,start, length)); } /** * 解析到元素结束时被调用 */ public void endElement(String uri, String localName, String qName) throws SAXException { System.out.println("解析到元素结束时...."+qName); } /** * 解析到文档结束时被调用 */ public void endDocument() throws SAXException { System.out.println("解析到文档结束时...."); } public void startPrefixMapping(String prefix, String uri) throws SAXException { } public void endPrefixMapping(String prefix) throws SAXException { } public void ignorableWhitespace(char[] ch, int start, int length) throws SAXException { } public void processingInstruction(String target, String data) throws SAXException { } public void skippedEntity(String name) throws SAXException { } public void setDocumentLocator(Locator locator) { } }
package cn.sax.demo; import java.io.IOException; import javax.xml.parsers.ParserConfigurationException; import javax.xml.parsers.SAXParser; import javax.xml.parsers.SAXParserFactory; import org.xml.sax.Attributes; import org.xml.sax.ContentHandler; import org.xml.sax.Locator; import org.xml.sax.SAXException; import org.xml.sax.XMLReader; public class SaxDeno2 { //打印第二本书的作者 public static void main(String[] args) throws ParserConfigurationException, SAXException, IOException { SAXParserFactory newInstance = SAXParserFactory.newInstance(); SAXParser newSAXParser = newInstance.newSAXParser(); XMLReader xmlReader = newSAXParser.getXMLReader(); xmlReader.setContentHandler(new ContentHandler() { boolean isAuthor=false; int count=0; @Override public void startDocument() throws SAXException { } @Override public void startElement(String uri, String localName, String qName, Attributes atts) throws SAXException { if ("作者".equals(qName)) { isAuthor = true; count+=1; }else{ isAuthor = false; } } @Override public void characters(char[] ch, int start, int length) throws SAXException { if (isAuthor && count==2) { System.out.println(new String(ch,start,length)); } } @Override public void endElement(String uri, String localName, String qName) throws SAXException { } @Override public void endDocument() throws SAXException { } public void startPrefixMapping(String prefix, String uri) throws SAXException { } public void skippedEntity(String name) throws SAXException { } public void setDocumentLocator(Locator locator) { } public void processingInstruction(String target, String data) throws SAXException { } public void ignorableWhitespace(char[] ch, int start, int length) throws SAXException { } public void endPrefixMapping(String prefix) throws SAXException { } }); xmlReader.parse("src/book.xml"); } }
package cn.sax.demo; import java.io.IOException; import java.util.ArrayList; import javax.xml.parsers.ParserConfigurationException; import javax.xml.parsers.SAXParser; import javax.xml.parsers.SAXParserFactory; import org.xml.sax.Attributes; import org.xml.sax.SAXException; import org.xml.sax.XMLReader; import org.xml.sax.helpers.DefaultHandler; import cn.sax.bean.Book; public class SaxDemo3 { //封装对象 public static void main(String[] args) throws ParserConfigurationException, SAXException, IOException { SAXParserFactory newInstance = SAXParserFactory.newInstance(); SAXParser newSAXParser = newInstance.newSAXParser(); XMLReader xmlReader = newSAXParser.getXMLReader(); final ArrayList<Book> books= new ArrayList<Book>(); xmlReader.setContentHandler(new DefaultHandler(){ Book book=null; String currentTagName=null; @Override public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException { if("书".equals(qName)){ book =new Book(); } currentTagName=qName; } @Override public void characters(char[] ch, int start, int length) throws SAXException { if("书名".equals(currentTagName)){ book.setBookName(new String(ch, start,length)); }else if(("作者").equals(currentTagName)){ book.setAuthor(new String(ch,start,length)); }else if(("售价").equals(currentTagName)){ book.setPrice(Float.parseFloat(new String(ch,start,length-1))); } } @Override public void endElement(String uri, String localName, String qName) throws SAXException { currentTagName=null; if("书".equals(qName)){ books.add(book); } } }); xmlReader.parse("src/book.xml"); for (Book book : books) { System.out.println(book); } } }