在后续prometheus的使用中遇到的一些问题我会在此记录
搭建初期几个问题
rule.yml中对每条告警加上主机名?
要在告警通知中加上故障机器主机名不能从prometheus的采集监控项数据中的主机名入手,需要prometheus添加主机名target,即instance="hostname:port",而不是instance="ip:port"。主机名的解析可在/etc/hosts添加或自行搭建dns服务器。在告警中引用instance变量,即实现此需求。
如何实现告警通知人分组,再在配置文件中引用组名?
只能在alertmanager配置中加。除非自己写webhook。
对prometheus的数值保留两位小数?
可以通过函数保留整数,ceil()将样本值向上保留一位整数。
报警模板
在alermanager.yml 中可以带入告警信息的模板文件
默认模板
https://github.com/prometheus/alertmanager/blob/master/template/default.tmpl
自定义模板
模板1:
{{ define "wechat.default.message" }}{{ if gt (len .Alerts.Firing) 0 -}}{{ range .Alerts }}Alerts Firing:{{ .Labels.severity }} / {{ .Labels.instance }} / {{ .Annotations.summary }} / {{ .StartsAt.Format "2006-01-02 15:04:05" }}{{- end }}{{- end }}{{ if gt (len .Alerts.Resolved) 0 -}}{{ range .Alerts }}Alerts Resolved:{{ .Labels.severity }} / {{ .Labels.instance }} / [ {{ .Annotations.summary }} ]Restored / {{ .StartsAt.Format "2006-01-02 15:04:05" }}{{- end }}{{- end }}{{- end }}
模板2:
以下是我企业微信告警的模板配置(极度简化):
{{ define "wechat.default.message" }}{{ if gt (len .Alerts.Firing) 0 -}}{{ range .Alerts }}
warning: {{ .Labels.hostname }} {{ .Labels.instance }} {{ .Annotations.summary }} {{- end }}{{- end }}{{ if gt (len
.Alerts.Resolved) 0 -}}{{ range .Alerts }}
Resolved: {{ .Labels.hostname }} {{ .Labels.instance }} {{ .Annotations.summary }} {{- end }}{{- end }}{{- end }}
告警实例:
warning: centos_CcbDbS_d3378 10.0.0.80 /data 91%
模板3:
{{ define "wechat.default.message" }}
{{ range .Alerts }}
start==
告警程序:prometheus_alert
告警级别:{{ .Labels.severity }}
告警类型:{{ .Labels.alertname }}
故障主机: {{ .Labels.instance }}
告警主题: {{ .Annotations.summary }}
告警详情: {{ .Annotations.description }}
触发时间: {{ .StartsAt.Format "2006-01-02 15:04:05" }}
end==
{{ end }}
{{ end }}
promql 函数
-
使用increase 计算累计监控项1h内的增量,监控取值都为整数,为什么increase处理后有小数?
increase() 函数获取区间向量中的第一个和最后一个样本并返回其增长量, 它会在单调性发生变化时(如由于采样目标重启引起的计数器复位)自动中断。由于这个值被外推到指定的整个时间范围,所以即使样本值都是整数,你仍然可能会得到一个非整数值。也就是它会根据第一个与最后一个样本的增长量与两个取样点时间长度而估算出函数中所设定的时间长度对应的增长量。
-
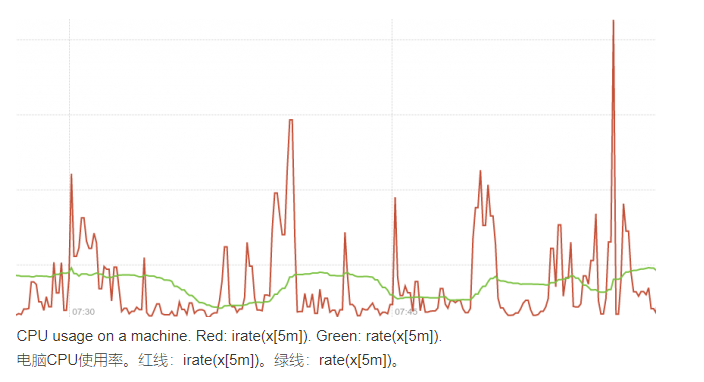
rate与irate区别
取自:https://www.zhukun.net/archives/8301
rate() 函数计算某个时间序列范围内的每秒平均增长率,基于设定范围内的第一个和最后一个数据点来计算每秒比率(允许计数器重置),(last值-first值)/时间差。自适应单调性中断(比如target重启导致的计数器重置),计算结果是推算到每个时间范围的最后而得出, 允许漏抓和抓取周期与时间范围的不完美结合,rate应该只和计数器一起使用。最适合告警和缓慢计数器的绘图,数据曲线较缓和。irate() 函数计算一段时间范围内某个时刻的每秒增长率,它只观测设定的范围内的最后两个点,并计算每秒的速率,(last值-last前一个值)/时间戳差值. 自适应单调性中断(比如target重启导致的计数器重置).irate应该只和快速的, 不稳定的计数器一起使用。irate绘图更精准。如果irate只需要最近两个点的数据,那为什么我们要传比这两个点长得多的时间范围呢?答案是,你想要限制这两点的取值范围,因为你不希望使用几个小时前的数据。还有另外一个好处,在面板(dashboards)选择比率范围(rate range)时,不需要考虑所有可能的拉取间隔(scrape intervals)。因为那样做通常会导致计算的时间比需要的长得多。如果拉取动作(scrape)变得更频繁,图像会自动提高分辨率。
alertmanager.yml中route分组告警走向
这个地方比较坑,你以为同一个告警信息匹配到的每个receiver都会发消息,其实,并不是!!!告警会自动从上级路由走到下级路由,下级路由会覆盖上级路由的设置,同级路由加上continue: true 才会继续往之后的同级路由匹配,并给所有匹配到的同级路由的receiver发信息。
举个栗子哟:

以上有三个receiver,以下有三台主机,他们的告警信息该发给谁?:
主机1(广告项目的mysql机子)标签 type: mysql job: adv;
主机2(广告项目代理机子)标签 type: ngx job: adv;
主机3 (其他项目的代理机子) 标签 type: ngx job: other
分析:
主机1:发给dba,下级路由匹配到标签type: mysql,虽然还有一个job: adv同级路由能匹配,但是同级路由匹配到一个之后不会自动匹配下一个;
主机2:发给adv;
主机3:发给yunwei,下级路由不能匹配到,故不会覆盖主路由的receiver。
以下配置发送主机1告警给三个receiver :
route:
group_interval: 15s
repeat_interval: 1h
group_by: ['alertname']
receiver: 'yunwei'
routes:
- match: #这三行表示:match下不写标签,就是match所有标签,即所有报警信息都发给yunwei组
continue: true #continue 匹配到此规则的告警能继续同级routes匹配,并对同级中匹配到的所有receiver发送告警
receiver: 'yunwei'
- match:
type: mysql
continue: true ####
receiver: 'dba'
- match:
job: adv
continue: true
receiver: 'adv'
template的引用
参考:https://prometheus.io/docs/alerting/configuration/
在alertmanager中可以做到不同receiver使用不同的模板
模板1
{{ define "wechat_simple.html" }}{{ if gt (len .Alerts.Firing) 0 -}}{{ range .Alerts }}Alerts Firing:{{ .Labels.severity }} / {{ .Labels.hostname }} / {{ .Annotations.summary }} / {{ .StartsAt.Format "2006-01-02 15:04:05" }}{{- end }}{{- end }}{{ if gt (len .Alerts.Resolved) 0 -}}{{ range .Alerts }}Alerts Resolved:{{ .Labels.severity }} / {{ .Labels.hostname }} / [ {{ .Annotations.summary }} ]Restored / {{ .StartsAt.Format "2006-01-02 15:04:05" }}{{- end }}{{- end }}{{- end }}
模板2
{{ define "wechat_detail.html" }}
{{ if gt (len .Alerts.Firing) 0 -}}
Alerts Firing:
{{ range .Alerts }}
告警级别:{{ .Labels.severity }}
告警类型:{{ .Labels.alertname }}
Alert: {{ .Labels.test }}
故障主机: {{ .Labels.instance }}
告警主题: {{ .Annotations.summary }}
告警详情: {{ .Annotations.description }}
触发时间: {{ .StartsAt.Format "2006-01-02 15:04:05" }}
{{- end }}
{{- end }}
{{ if gt (len .Alerts.Resolved) 0 -}}
Alerts Resolved:
{{ range .Alerts }}
告警级别:{{ .Labels.severity }}
告警类型:{{ .Labels.alertname }}
故障主机: {{ .Labels.instance }}
告警主题: {{ .Annotations.summary }}
触发时间: {{ .StartsAt.Format "2006-01-02 15:04:05" }}
恢复时间: {{ .EndsAt.Format "2006-01-02 15:04:05" }}
{{- end }}
{{- end }}
告警链接:
{{ template "__alertmanagerURL" . }}
{{- end }}
alertmanager.yml 配置
global:
resolve_timeout: 1m
templates:
- '/usr/local/alertmanager/template/*.tmpl' #此处需要将以上两个模板文件引用进来
route:
group_interval: 15s
repeat_interval: 1m
group_by: ['alertname']
receiver: 'wechat1'
routes:
- receiver: 'wechat2'
match:
for: 'test'
receivers:
- name: 'wechat1'
wechat_configs:
- corp_id: 'wx8659xxxxxx'
send_resolved: true
message: '{{ template "wechat_simple.html" . }}' #此参数可引用模板文件
to_user: 'jor|Ya'
agent_id: '10000xx'
api_secret: '3igxxxxxxxxOg'
- name: 'wechat2'
wechat_configs:
- corp_id: 'wxxxxxxx06e'
send_resolved: true
message: '{{ template "wechat_detail.html" . }}'
# to_party: 'jorney'
to_user: 'joy|Yn'
agent_id: '1000xxx'
api_secret: '3igMMxxxxxxxx'
windows安装exporter
https://github.com/martinlindhe/wmi_exporter/releases/download/v0.3.3/wmi_exporter-0.3.3-amd64.msi
双击安装,应该是会自动开机启动(不确定),端口 9182
获取数据:ip:9182/metrics
内存使用率
今天我看到一个计算prometheus内存使用率的表达式是这样:
(1-((node_memory_Buffers_bytes+node_memory_Cached_bytes+node_memory_MemFree_bytes)/node_memory_MemTotal_bytes))*100
用命令行查看某机器的内存使用情况
[root@one nginx]# free -m
total used free shared buff/cache available
Mem: 3530 1801 58 354 1670 1179
神奇的事情发生了:buff/cache 大于available,一般来说 available=free + buff/cache
一查资料发现有这么一句:如果free内存不够用,,系统会回收buff和cache内存。但是因为内核的buff和cache不能回收,所以available <= free + buff/cache,用avaiblable算出的使用率会大于几项相加之和的使用率。
所以内存使用率用available来计算是不是更准确呢?
(1-((node_memory_MemAvailable_bytes)/node_memory_MemTotal_bytes))*100
新发现的问题:
node_memory_MemAvailable_bytes指标centos7有,centos6没有,所以第一种表达式对两个系统都适用,但是两种算法的值会有出入。
blackbox_exporter 监控url 状态返回码为0
使用blackbox_exporter 监控url,curl -i $url 返回码为302,但是收集的监控项值为0.
因为没有加重定向相关配置“no_follow_redirects: true”,默认是false。
