| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/fzu/SE2020 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/fzu/SE2020/homework/11167 |
| 这个作业的目标 | 制作一个程序统计和分析 GitHub 的用户行为数据。 |
| 学号 | 031802112 |
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| Estimate | 估计这个任务需要多少时间 | 30 | 20 |
| Development | 开发 | ||
| Analysis | 需求分析 (包括学习新技术) | 120 | 240 |
| Design Spec | 生成设计文档 | 20 | 20 |
| Design Review | 设计复审 | 30 | 30 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 20 | 30 |
| Design | 具体设计 | 40 | 30 |
| Coding | 具体编码 | 180 | 300 |
| Code Review | 代码复审 | 30 | 60 |
| Test | 测试(自我测试,修改代码,提交修改) | 180 | 300 |
| Reporting | 报告 | ||
| Test Report | 测试报告 | 20 | 20 |
| Size Measurement | 计算工作量 | 30 | 30 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 180 | 180 |
| 合计 | 1060 | 1260 |
二、解题思路
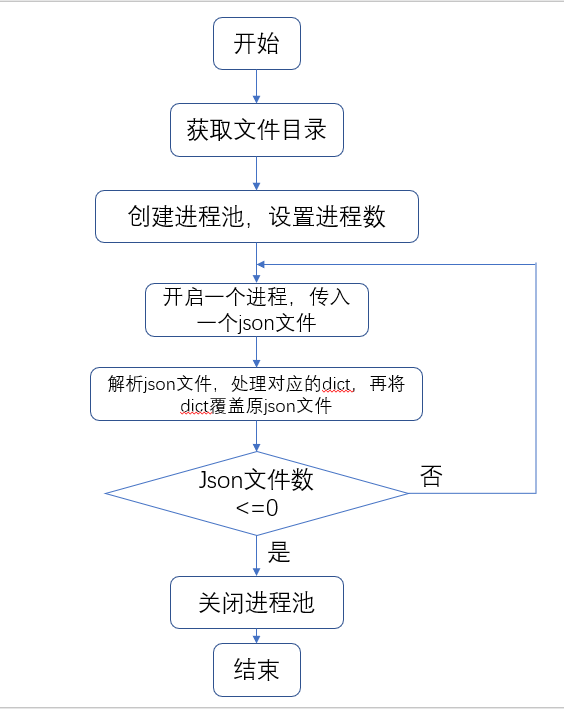
初看本题,大概的思路就是解析 json 文件,之后对数据进行处理(无用数据的删除、数据的划分等等)。由于 Python 自带 json 模块,所以先确定使用 Python 作为本题编程语言。通过对题目的慢慢理解,发现数据规模在 10GB 左右,所以常规的解析算法不仅会爆内存,速度还巨慢。之后在面向百度编程后,发现可以使用多线程解决。尝试写了一个小程序来跑多线程,发现时间并没有快,后面才发现 Python 的多线程主要用于同时执行多个不同的程序,然而对于本题来说并没有什么卵用。最后找到了他的 ” 兄弟 “ 多进程,通过使用 Python 的进程池来实现多进程读取文件,这样可以牺牲少量的内存,从而使时间得到大量的优化。至于时间问题,就简单使用一边读一边处理,在处理完一个文件后将处理后的内容覆盖写入原文件,这样既可以解决时间问题,还可以解决子进程和父进程数据共享的功能。最后为了优化查询操作的时间复杂度,在初始化就把所有数据统计写到一个新的文件中,有利于查询时直接打开该文件快速查询。
1.具体步骤

2.思考过程
大部分是通过 CSDN、博客园、baidu、以及《Python 编程》来实现功能模块的使用。
-
通过对样例文件的观察,以及结合本题任务,json 文件中只有3个键有用,分别是 type、actor_login、repo_name,故需要对有效数据进行提取。
-
对于指令的解析,通过 Python 的 argparse 模块去创建解析器(argparse.ArgumentParser())
-
关于 json 文件的解析,使用 Python 自带的 json 模块 (json.load()、json.dump())
-
由于使用多线程后失败了,并未有任何优化,故使用多进程,其中主要是依靠开启固定大小的进程池(processes = 5)来实现对多个 json 文件的并行读取,从而压缩时间
-
对于数据的统计则是简单的字典键值对处理,其中由于 json 文件中存在多个字典的嵌套,故使用递归的方式抓取有用的键值对。
三、实现过程
在具体编码过程中,经过了一次大的改动,即从单进程到多进程的程序更新。
1.单进程版本
思路:
采用了工作量和思考量最少的办法,循环进行 json 文件的顺序解析,并且将解析返回的 dict 及时的进行统计操作,避免 dict 的堆积导致内存高达 10GB 。
遇到的问题以及解决方案:
- 对于指令解析函数传参的不熟悉导致程序无法正确的解析指令,结果老是 init failed 。后来查询发现解析之后调用 args.name ,这里的name需要属性名的全称,而且还不会报错。就挺坑泷的!!
- 一开始使用 dict 合并在一起再统计,导致内存高到 10GB ,后面改为读一个文件统计一个文件。
- 但是仍然存在初始化时间要 10+ 分钟,就很慢。
2.多进程版本
思路:
为了解决单进程版本的初始化时间问题,增加使用进程池,使得多个文件并行处理。并且为了更好的优化内存和时间,在解析 json 文件时使用递归函数删除了没用多余的数据,提取了有效数据。
遇到的问题以及解决方案:
- 一开始单纯的认为多线程的并发可以解决时间问题,但是 Python 中的多线程并理想中的这么好用。紧接着就改用多进程。
- 在把 json 文件读取代码封装成一个函数后,发现多进程里的父进程不能接收子进程函数的返回值,这样导致 json 文件读取后的 dict 无法保存给父进程使用。翻书发现可以用 multiprocessing 模块中的 Queue 队列来实现进程间的通信,实际上就是把子进程返回的值保存在 Queue 队列中,但由于考虑到多个 dict 的累积可能会导致队列内存爆炸。所以想了半天,最后整了个骚操作,利用覆盖原读取的 json 文件来暂时保存结果。当回到父进程后,再打开文件读取。
关键函数 __init()的流程图:
四、关键代码
__init()
#利用多进程对文件读取,统计并生成结果文件,完成初始化。
def __init(self, dict_address: str):
self.__4Events4PerP = {}
self.__4Events4PerR = {}
self.__4Events4PerPPerR = {}
# 将文件读出到list和字符串处理合并在一起 即读出一行处理一行 这样list就不会太大以至于内存爆炸。
pool = Pool(processes=5)
for root, dic, files in os.walk(dict_address):
for f in files:
# 开启多进程读入 然后再把处理好的list覆盖读入的文件 优化时间
pool.apply_async(func=self.merge, args=(f, dict_address))
pool.close()
pool.join()
records=[]
#打开覆盖文件,统计数据
for f in files:
with open( dict_address +'\'+f,'r') as x:
records=json.load(x)
for i in records:
if not self.__4Events4PerP.get(i['login'], 0):
self.__4Events4PerP.update({i['login']: {}})
self.__4Events4PerPPerR.update({i['login']: {}})
self.__4Events4PerP[i['login']][i['type']
]=self.__4Events4PerP[i['login']].get(i['type'], 0)+1
if not self.__4Events4PerR.get(i['name'], 0):
self.__4Events4PerR.update({i['name']: {}})
self.__4Events4PerR[i['name']][i['type']
]=self.__4Events4PerR[i['name']].get(i['type'], 0)+1
if not self.__4Events4PerPPerR[i['login']].get(i['name'], 0):
self.__4Events4PerPPerR[i['login']].update({i['name']: {}})
self.__4Events4PerPPerR[i['login']][i['name']][i['type']
]=self.__4Events4PerPPerR[i['login']][i['name']].get(i['type'], 0)+1
with open('1.json', 'w', encoding='utf-8') as f:
json.dump(self.__4Events4PerP, f)
with open('2.json', 'w', encoding='utf-8') as f:
json.dump(self.__4Events4PerR, f)
with open('3.json', 'w', encoding='utf-8') as f:
json.dump(self.__4Events4PerPPerR, f)
多进程函数merge()
#多进程调用merge()处理文件 把数据处理后的list覆盖原json的内容 解决子进程向父进程传递数据问题
def merge(self, f, dict_address):
json_list = []
if f[-5:] == '.json':
json_path = f
x = open(dict_address+'\'+json_path,
'r', encoding='utf-8').read()
str_list = [_x for _x in x.split('
') if len(_x) > 0]
for i, _str in enumerate(str_list):
try:
json_list.append(json.loads(_str))
except:
pass
records = []
records = self.__listOfNestedDict2ListOfDict(json_list)
#覆盖原文件 保存records[]
with open(dict_address+'\'+f,'w') as r:
json.dump(records,r)
五、单元测试及性能测试
-
单元测试方面使用 unittest 模块,分别编写了 test_init() 、test_getEeventUsers() 、test_getEventsRepos() 、test_getEventsUsersAndRepos() 四个单元测试函数。
单元测试函数:
import unittest from GHAnalysis import Data from GHAnalysis import Run class Test( unittest.TestCase): #D:学习软工实践2020-personal-python def test_init(self): data = Data('D:学习软工实践2020-personal-python',1) #若初始化成功 则为Ture self.assertTrue(data) def test_getEventsUsers(self): data = Data() result = data.getEventsUsers('hl1123','PushEvent') #若成功 则返回0 self.assertEqual(result,0) def test_getEventsRepos(self): data = Data() result = data.getEventsRepos('hl1123/6','PushEvent') #若成功 则返回0 self.assertEqual(result,0) def test_getEventsUsersAndRepos(self): data = Data() result = data.getEventsUsersAndRepos('hl1123','hl1123/6','PushEvent') #若成功 则返回0 self.assertEqual(result,0)单元测试结果:
-
性能测试方面,主要以程序执行时间为考量标准。测试数据大小为 551MB 。
测试结果:
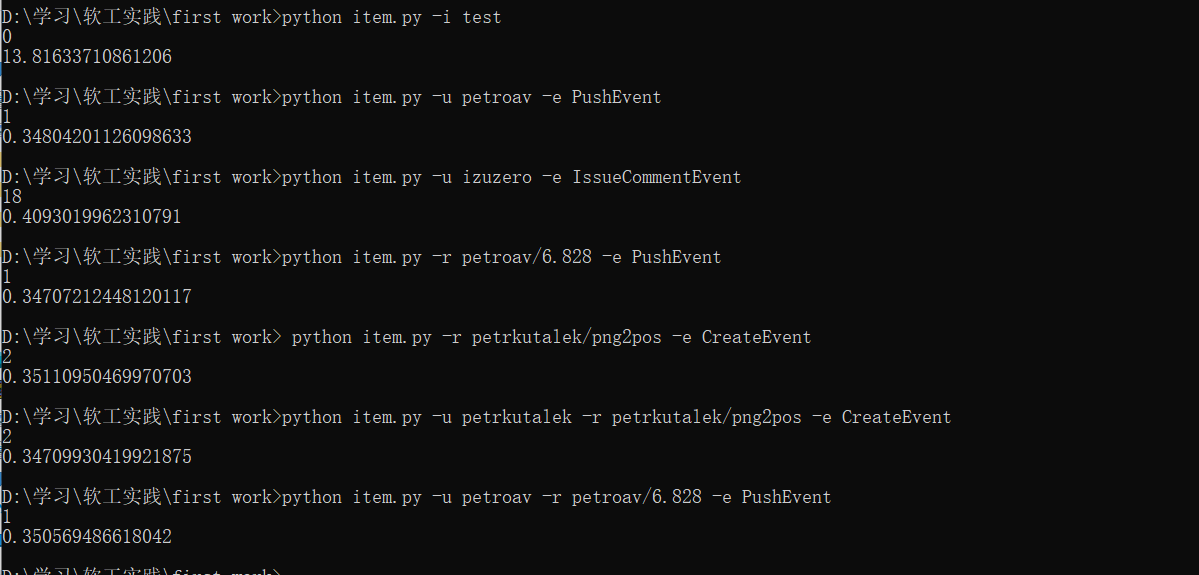
从结果显示来看,初始化所需的时间在14s 左右,平均查询时间在 350ms 到 400ms 左右。个人分析初始化时间主要影响因素为了多进程中 json 文件的读写操作以及在统计结果时对于文件的读操作。
六、单元测试覆盖率及性能优化
-
单元测试覆盖率
在本次的单元测试覆盖率的计算中,我使用了 coverage 工具来实现,由于第一次接触这个东西,在使用的时候不是很ok。
发生的问题:一直无法将多个 coverage 测试合并在一起,导致最后的测试报告中只有一次操作的覆盖率,仅仅只有 38%。
解决方法:通过使用 coverage help 查看其解释文档,发现可以使用 -a 将多个coverage测试合并
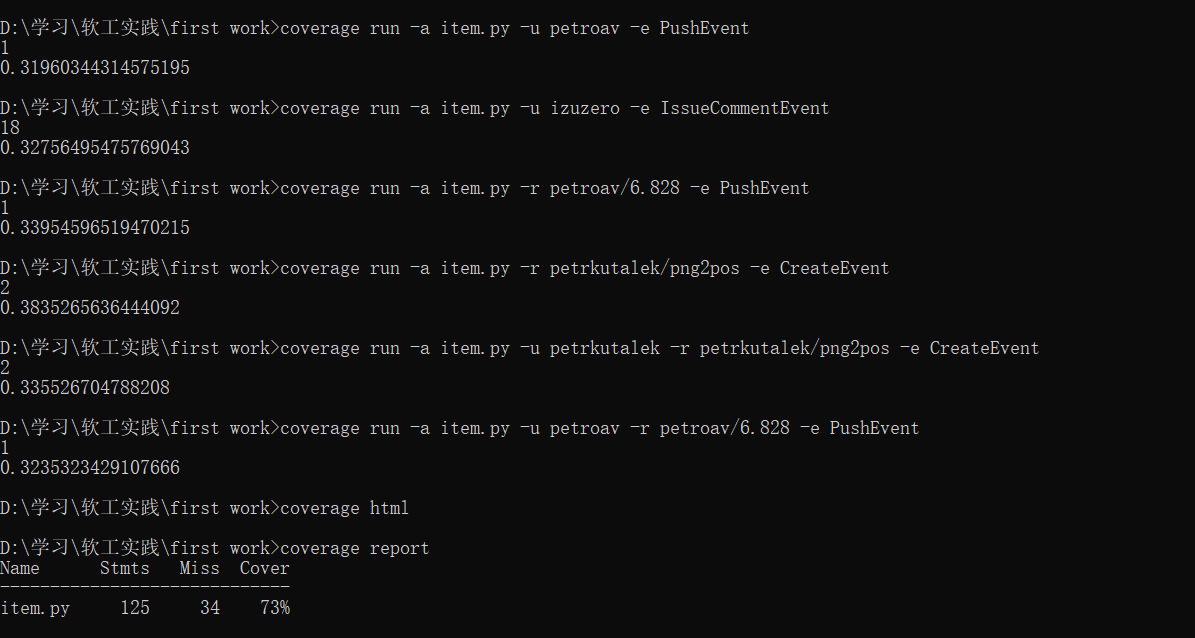
测试覆盖率结果:
初始化:
查询:
html_report:

总体上看覆盖率达到了 73% ,查看其 html 文件发现多进程函数并没有覆盖到,但实际是会覆盖到的,经过 baidu 并没有找到合理的解释,后面把多进程关了把函数当成正常的函数,发现该函数有覆盖到了,所以可能由于 coverage 工具的缺陷导致这样的结果。所以总的覆盖率应该高于 73%。
-
性能优化
由上部分性能测试的分析来看,接下来可能的优化方法大概需要引用 Python 的 sqllite3 模块的数据库,对于数据库而已,其内部数据结构对于存储和查询操作的时间复杂度极低,但由于时间问题,未能实现。在未来可能会去实现用数据库 + 多进程的算法解决本次任务。
七、代码规范
八、总结
- 在本次个人编程实践中,我学习了挺多实践的方法,例如命令行指令的解析、json文件的解析、多进程开发等等。还有学习了许多程序测试方法:利用 coverage 进行覆盖率的计算、利用简单的 time 模块进行时间性能测试等等。最主要我觉得我学习了如何在项目开发中规划时间、安排任务、合理的有预期的进行程序开发。
- 本次任务也很大程度的锻炼了我 debug 的能力,特别是对于迭代版本之间的 bug 处理。
- 本次任务中问题的解决主要是依靠搜索引擎,我深刻的认识到百度的厉害之处,百度,程序员滴神!在查资料的过程中总有意味的收获,例如发现好像有一种工具 intel vtune 可以进行性能测试,下次试一下。
九、参考资料
其实本次在搜索引擎上找的参考资料应该有几十篇吧,可能还不止。所以只写了几个比较重要并有用的参考资料。
主要来源:博客园、CSDN、廖雪峰的官方网站、菜鸟教程、知乎、《Python 编程:从入门到实践》等等