这篇博客详细写了熵,信息增益和信息增益率的区别,可参考阅读:http://blog.csdn.net/cyningsun/article/details/8735169
这篇博客主要是听了唐宇迪课程泰坦尼克号预测的一些笔记
决策树算法本身不难理解,关键是如何决定哪个特征做根节点,也就是这些特征在决策树这颗树中的层次问题
引入熵的概念解决这个问题



举个例子:通过outalook,temperature,humidity,windy这四个特征决定今天是否能够出去玩
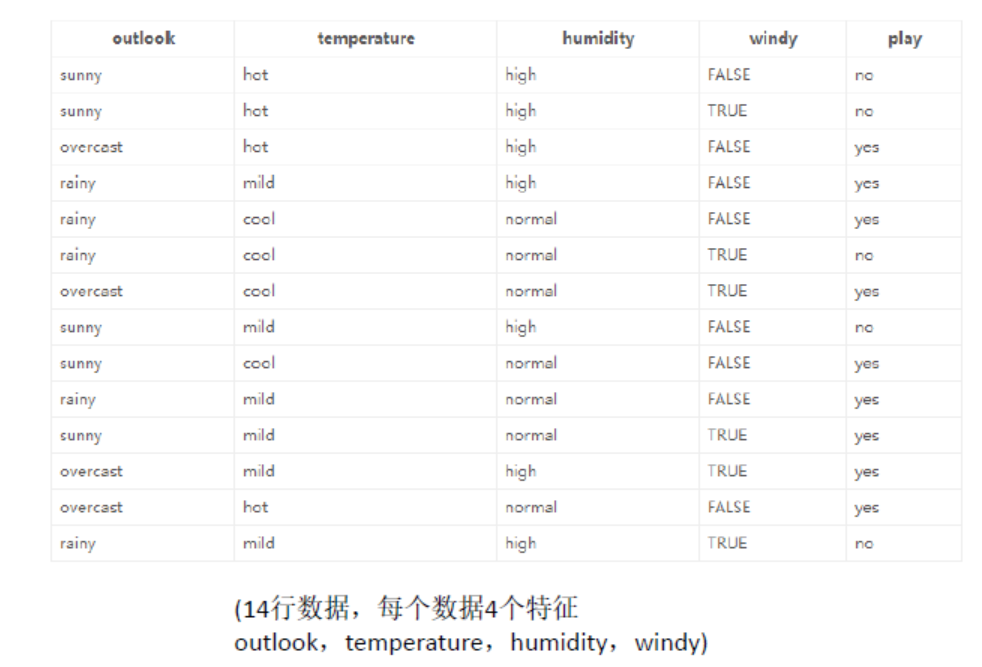

一共14个样本,基于每个特征下面的值划分样本可得到如下结果


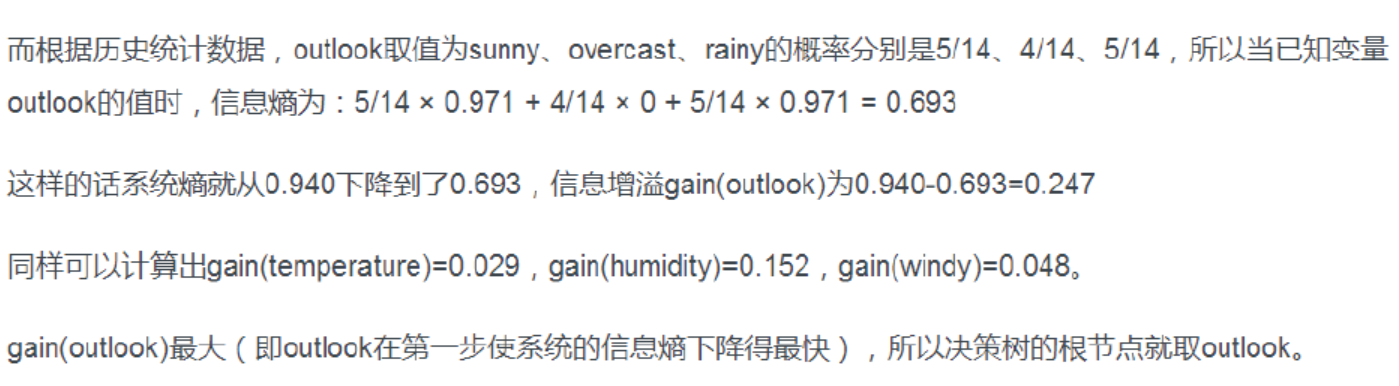

上面的结果是根据信息增益计算得来的,但是根据信息增益计算的到决策树就真的一点问题都没有吗?显然不是的,如果我们给上面的例子加一个特征,ID,14个样本的ID分别为1234567891011121314,此时对ID这个特征来说,ID=1,那么得到的play只有一种可能,就是no,那么此时信息熵=(-1*log21)*1/14,外面这个1/14是特征ID为1的概率,此时信息熵为0,那么原始信息熵为0.94,显然选择ID特征作根节点是合适的,如果用信息增益作为指标的话,但是仔细思考,ID真的能够作为根节点吗?最能决定play值的是它的序号吗?显然不是的,因此提出了信息增益率的概念
信息增益率则计算如下:
gainratio(Attribute)=gain(Attribute)IntrinsicInfo(Attribute)
