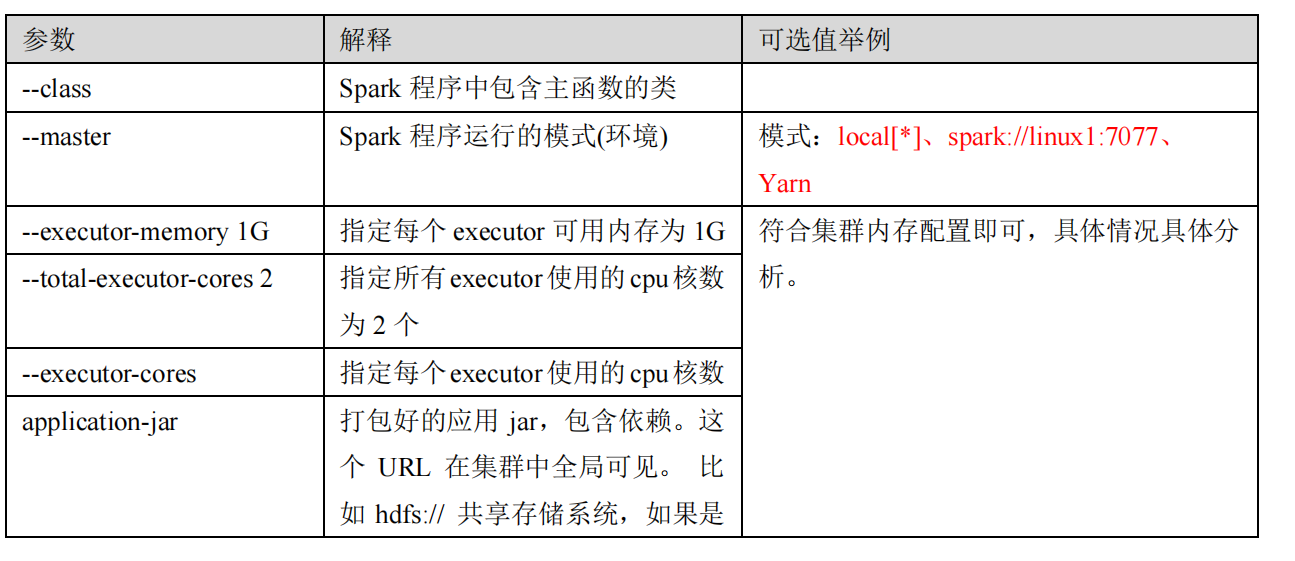
bin/spark-submit \
--class <main-class>
--master <master-url> \
... # other options
<application-jar> \
[application-arguments]
由于 spark-shell 停止掉后,集群监控 linux1:4040 页面就看不到历史任务的运行情况,所以
开发时都配置历史服务器记录任务运行情况。
1) 修改 spark-defaults.conf.template 文件名为 spark-defaults.conf
mv spark-defaults.conf.template spark-defaults.conf
2) 修改 spark-default.conf 文件,配置日志存储路径
spark.eventLog.enabled true
spark.eventLog.dir hdfs://linux1:8020/directory
注意:需要启动 hadoop 集群,HDFS 上的 directory 目录需要提前存在。
sbin/start-dfs.sh
hadoop fs -mkdir /directory
3) 修改 spark-env.sh 文件, 添加日志配置
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://linux1:8020/directory
-Dspark.history.retainedApplications=30"
⚫ 参数 1 含义:WEB UI 访问的端口号为 18080
⚫ 参数 2 含义:指定历史服务器日志存储路径
⚫ 参数 3 含义:指定保存 Application 历史记录的个数,如果超过这个值,旧的应用程序
信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数。
4) 分发配置文件
xsync conf
5) 重新启动集群和历史服务
sbin/start-all.sh
sbin/start-history-server.sh
6) 重新执行任务
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://linux1:7077 \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10