
the conception of Machine Learning 1
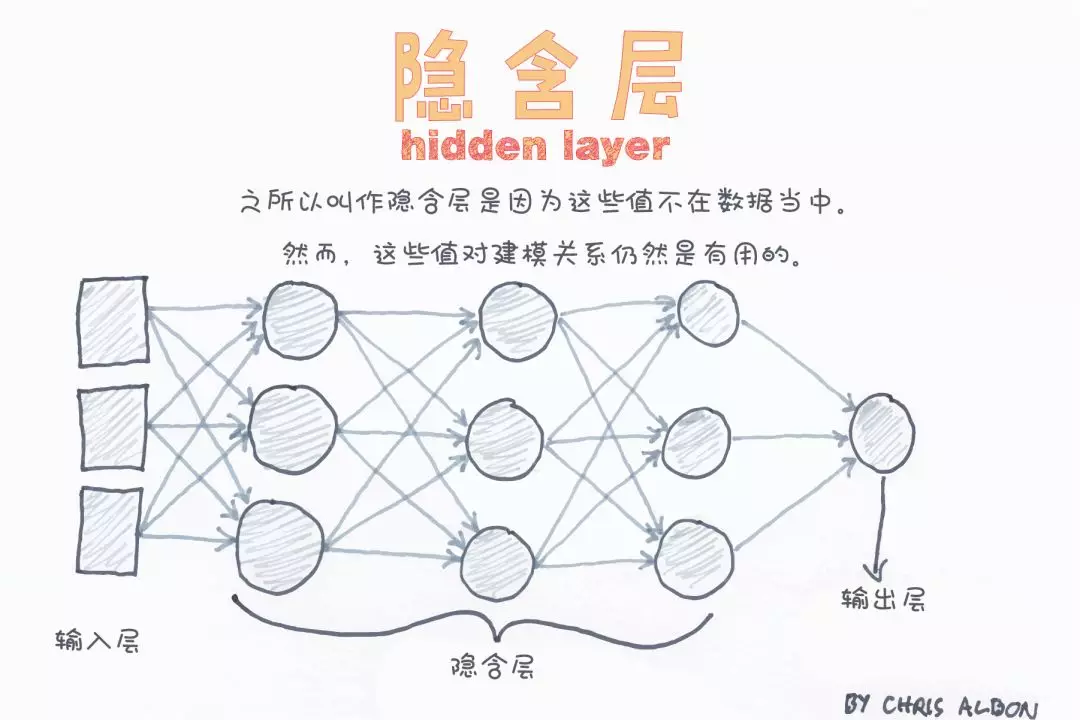
Hidden layer

[Heteroskedasticity](https://blog.csdn.net/dingming001/article/details/73826630)

Hessian Matrix

Hyperparameter tuning

How To Choose Hidden Unit Activiation Functions

Bias-Variance Tradeoff
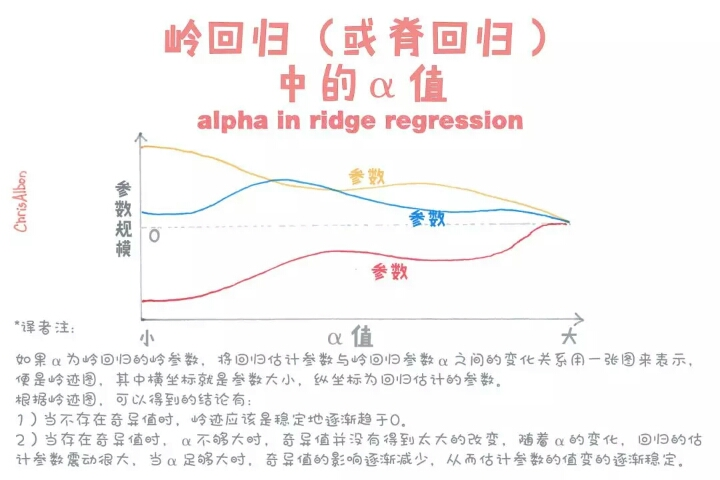
alpha in ridge regression
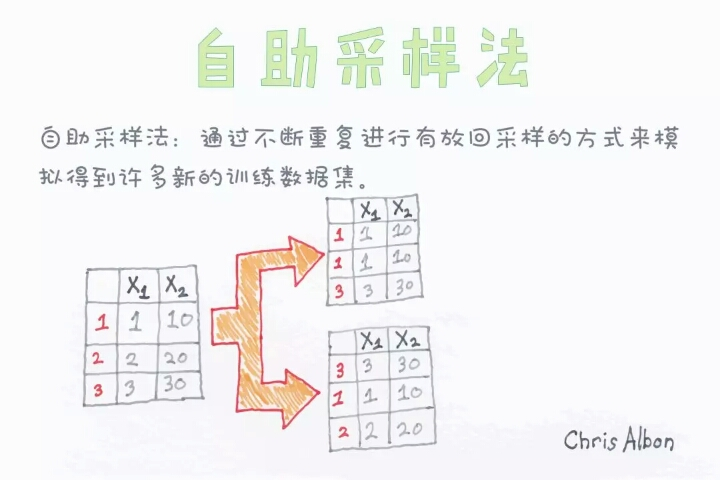
Bootstrapping,[Transmission Gate](https://blog.csdn.net/batuwuhanpei/article/details/51884351)

capacity

Common Optimizers of Neural Nets
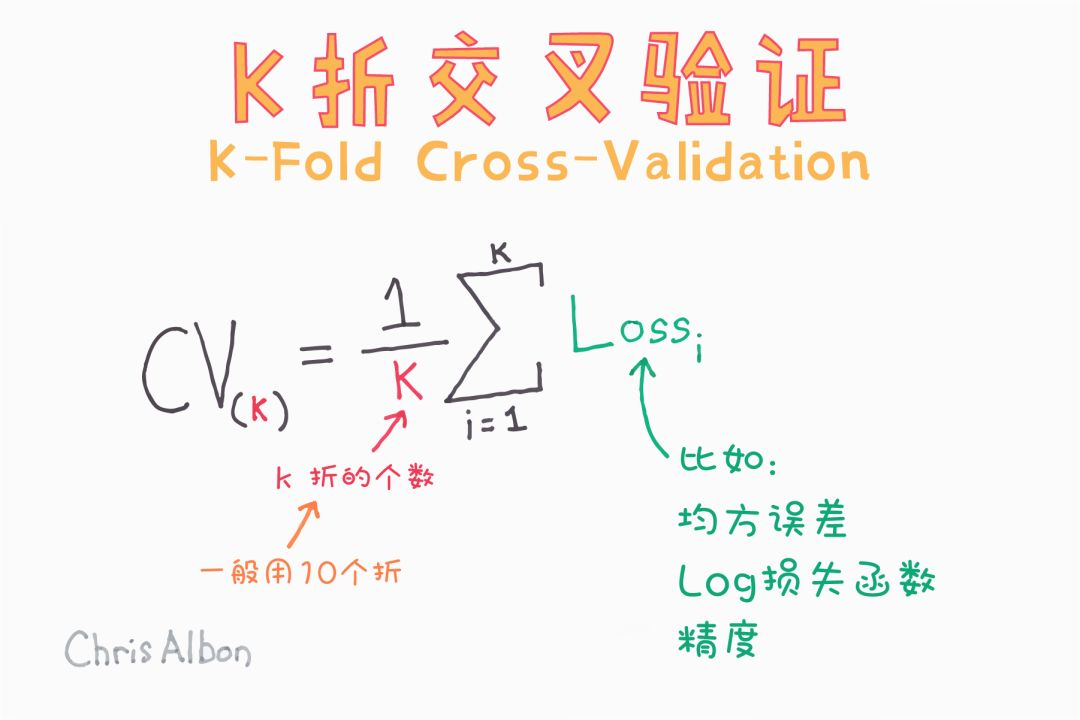
K-Fold Cross-Validation

Common Output Layer Activation Functions
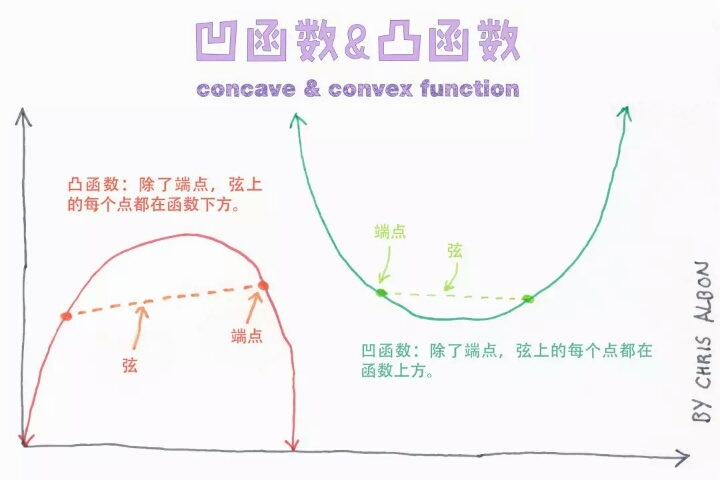
Concave & convex function
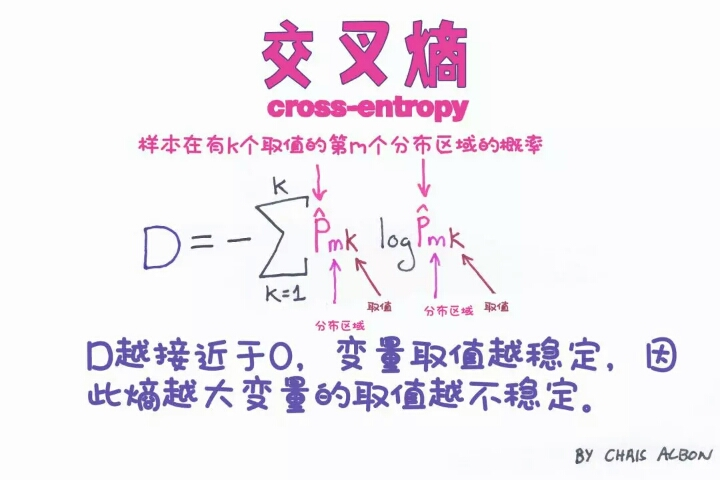
cross-entropy

conditional probability

Cost and Lost Functions

Confidence Intervals

F1


Exploding Gradient Problem

error type

Finding Linear Regression Parameters

Gradient Descent

Gradient Descent rule of thume
The Unknow Word
| The First Column |
The Second Column |
| thume |
|