–COUNT:统计行数量
–SUM:获取单个列的合计值
–AVG:计算某个列的平均值
–MAX:计算列的最大值
–MIN:计算列的最小值
首先,创建数据表如下:

执行列、行计数(count):
标准格式
SELECT COUNT(<计数规范>) FROM <表名>
其中,计数规范包括:
- * :计数所有选择的行,包括NULL值;
- ALL 列名:计数指定列的所有非空值行,如果不写,默认为ALL;
- DISTINCT 列名:计数指定列的唯一非空值行。
例,计算班里共有多少学生:
SELECT COUNT(*) FROM t_student;

也可加入筛选条件,如求女学生数目:
SELECT COUNT(*) FROM t_student WHERE student_sex='女';
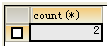
如果要计算班级数目,就需要用到DISTINCT:
SELECT COUNT(DISTINCT student_class) FROM t_student;

DISTINCT即去重,如果不加DISTINCT则结果为表行数——5。
返回列合计值(SUM):
注:sum只要ALL与DISTINCT两种计数规范,无*。
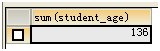
计算学生年龄之和:
SELECT SUM(student_age) FROM t_student;
返回列平均值(AVG):
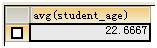
计算 学生平均年龄:
SELECT AVG(student_age)FROM t_student;
返回最大值/最小值(MAX/MIN):
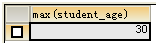
求 年龄最大的学生信息(最小值同理):
SELECT MAX(student_age) FROM t_student;
注:这里只能求出最大年龄,要想显示年龄最大的学生全部信息,需要用到之后的子查询。
数据分组(GROUP BY):
SQL中数据可以按列名分组,搭配聚合函数十分实用。
例,统计每个班的人数:
SELECT student_class,COUNT(ALL student_name) AS 总人数 FROM t_student GROUP BY (student_class);
AS为定义别名,别名的使用在组合及联接查询时会有很好的效果,之后再说。
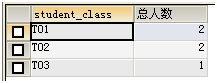
分组中也可以加入筛选条件WHERE,不过这里一定要注意的是,执行顺序为:WHERE过滤→分组→聚合函数。牢记!
统计每个班上20岁以上的学生人数:
SELECT student_class,COUNT(student_name) AS 总人数 FROM t_student WHERE student_age >20 GROUP BY (student_class);
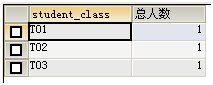
HAVING过滤条件:
之前说了分组操作、聚合函数、WHERE过滤的执行顺序,那如果我们希望在聚合之后执行过滤条件怎么办?
例,我们想查询平均年龄在20岁以上的班级
能用下面的语句吗?
SELECT student_class, AVG(student_age) FROM t_student WHERE AVG(student_age)>20 GROUP BY student_class;
结果会出错。正因为聚合函数在WHERE之后执行,所以这里在WHERE判断条件里加入聚合函数是做不到的。
这里使用HAIVING即可完成:
SELECT student_class,AVG(student_age) AS 平均年龄 FROM t_student GROUP BY (student_class) HAVING AVG(student_age)>20;

这里再啰嗦一句
SQL的执行顺序:
–第一步:执行FROM
–第二步:WHERE条件过滤
–第三步:GROUP BY分组
–第四步:执行SELECT投影列
–第五步:HAVING条件过滤
–第六步:执行ORDER BY 排序
子查询:
为什么要子查询?
现有一数据表如下:

根据之前的知识我们可以查出每门科目的最高分,但是要想查出取得最高分的学生信息就做不到了。这时就需要用到子查询来取得完整的信息。
什么是子查询?子查询就是嵌套在主查询中的查询。
子查询可以嵌套在主查询中所有位置,包括SELECT、FROM、WHERE、GROUP BY、HAVING、ORDER BY。
但并不是每个位置嵌套子查询都是有意义并实用的,这里对几种有实际意义的子查询进行说明。
现有表两张:一张学生表、一张班表。id相关联

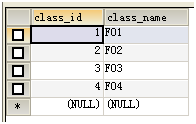
在SELECT中嵌套:
学生信息和班级名称位于不同的表中,要在同一张表中查出学生的学号、姓名、班级名称:
SELECT s.student_id,s.student_name,(SELECT class_name FROM t_class c WHERE c.class_id=s.class_id) FROM t_student s GROUP BY s.student_id;
* 首先这条SQL语句用到了别名,写法为在FORM的表名后加上某个字符比如FROM t_student s,这样在之后调用t_student的某一列时就可以用s.student_id来强调此列来源于对应别名的那张表。
别名在子查询及联接查询中的应用有着很好效果,当两张表有相同列名或者为了加强可读性,给表加上不同的别名,就能很好的区分哪些列属于哪张表。
还有种情况就是在子查询或联接查询时,主查询及子查询均为对同一张表进行操作,为主、子查询中的表加上不同的别名能够很好的区分哪些列的操作是在主查询中进行的,哪些列的操作是在子查询中进行的,下文会有实例说明。
接下来回到上面的SQL语句中,可以看出本条子查询的嵌套是在SELECT位置(括号括起来的部分),它与学号、学生姓名以逗号分隔开并列在SELECT位置,也就是说它是我们想要查出的一列,
子查询中查出的是,班级表中的班级id与学生表中的班级id相同的行 ,注意 WHERE c.class_id=s.class_id 这里就是别名用法的一个很好的体现,区分开了两张表中同样列名的列。
结果:

最后的GROUP BY可以理解为对重复行的去重,如果不加:
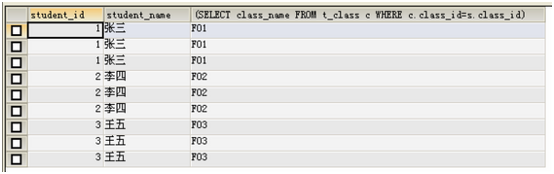
在WHERE中嵌套:
现要查出C语言成绩最高的学生的信息:
SELECT * FROM t_student WHERE student_subject='C语言' AND student_score>=ALL (SELECT student_score FROM t_student WHERE student_subject='C语言') ;
结果:

这里出现了一个ALL,其为子查询运算符
分类:
–ALL运算符
和子查询的结果逐一比较,必须全部满足时表达式的值才为真。
–ANY运算符
和子查询的结果逐一比较,其中一条记录满足条件则表达式的值就为真。
–EXISTS/NOT EXISTS运算符
EXISTS判断子查询是否存在数据,如果存在则表达式为真,反之为假。NOT EXISTS相反。
在子查询或相关查询中,要求出某个列的最大值,通常都是用ALL来比较,大意为比其他行都要大的值即为最大值。
要查出C语言成绩比李四高的学生的信息:
SELECT * FROM t_student WHERE student_subject='C语言' AND student_score >(SELECT student_score FROM t_student WHERE student_name='李四' AND student_subject='C语言');

通过上面两例,应该可以明白子查询在WHERE中嵌套的作用。通过子查询中返回的列值来作为比较对象,在WHERE中运用不同的比较运算符来对其进行比较,从而得到结果。
现在我们回到最开始的问题,怎么查出每门课最高成绩的学生的信息:
SELECT * FROM t_student s1 WHERE s1.student_score >= ALL(SELECT s2.student_score FROM t_student s2 WHERE s1.`student_subject`=s2.student_subject);
这里就是上文提到的别名的第二种用法,主、子查询对同一张表操作,区分开位于内外表中相同的列名。
结果:

子查询的分类:
–相关子查询
执行依赖于外部查询的数据。
外部查询返回一行,子查询就执行一次。
–非相关子查询
独立于外部查询的子查询。
子查询总共执行一次,执行完毕后后将值传递给外部查询。
上文提到的例子中,第一个例子求学生对应班级名的即为相关子查询,其中WHERE c.class_id=s.class_id 即为相关条件。其他的例子均只对一张表进行操作,为非相关子查询。
需要注意的是相关子查询主查询执行一回,子查询就执行一回,十分耗费时间,尤其是当数据多的时候。
组合查询:
通过UNION运算符来将两张表纵向联接,基本方式为:
SELECT 列1 , 列2 FROM 表1
UNION
SELECT 列3 , 列4 FROM 表2;
UNION ALL为保留重复行:
SELECT 列1 , 列2 FROM 表1
UNION ALL
SELECT 列3 , 列4 FROM 表2;
组合查询并不是太实用,所以这里只是简单提一下,不举出例子了。
上文说过相关子查询不推荐使用,组合查询又用的少之又少,那需要关联的多张表我们怎么做?
这就是下一篇博文要详细说明的SQL的重点表联接、联接查询。而此篇博文目的是为了对嵌套查询、别名的用法等等打下基础,毕竟只是写法变了,思路还是相似的。