redis集群:
redis集群是高可用的一种体现,让整个redis圈更加稳定,不易出现宕机的情况,
redis原理:
redis3.0之前是不支持集群的,实现集群要自己去配置实现,很麻烦,在3.0之后就支持了
原理图:借助网上很火的一张图
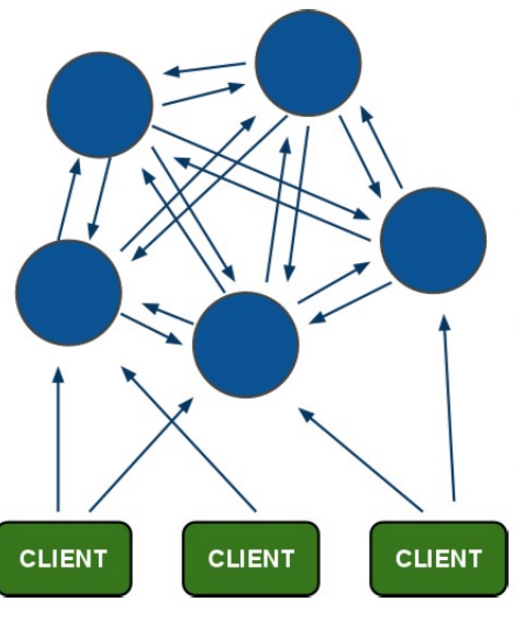
这个图中,每一个蓝色的圈都代表着一个redis的服务器节点。它们任何两个节点之间都是相互连通的。客户端可以与任何一个节点相连接,然后就可以访问集群中的任何一个节点。对其进行存取和其他操作。
那么redis是怎么做到的呢?首先,在redis的每一个节点上,都有这么两个东西,一个是插槽(slot)可以理解为是一个可以存储两个数值的一个变量这个变量的取值范围是:0-16383。还有一个就是cluster我个人把这个cluster理解为是一个集群管理的插件。当我们的存取的key到达的时候,redis会根据crc16的算法得出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,通过这个值,去找到对应的插槽所对应的节点,然后直接自动跳转到这个对应的节点上进行存取操作

上面这个图就解释了,最后在7003中查不到这个key,而能获取这个key的值,类似于路由的概念
redis集群配置步骤:
下面我简单实现一下在linux上搭建redis集群的步骤,redis的非集群安装
redis集群我采用六个点,三主三从形式,这是为了选举机制而这样设计,这个选举规则和hive,zookeeper类似,都是 少数服从多数的选举机制.
由于资源有限,我用一台主机模拟六台实例机器,实现集群的搭建,暂定我的实例端口7001~7006.
1>在搭建集群之前我简单介绍一下安装编译redis的四步:
第一步:下载redis.tar包,
第二步:上传,并解压
第三步:进人解压后的文件夹输入make进行编译
第四步: 编译后需要走执行安装,并指定安装路径 make install PREFIX=/usr/local/redis 这样就可以生成bin目录了,不用拷贝src,通过执行这个命令就跑到我们指定的文件夹下,并生成bin文件夹:
2>redis的安装编译按照上面步骤走就应该可以了,记得启动测试一下,我这就不测试先。
3>在步骤1中的第四步的bin文件内容如下:此时在任何目录都可以执行bin文件夹下的命令了

4>退出到上级目录,并创建一个redis-cluster文件夹,放集群的文件,将bin复制6份分别拷贝到

5>把刚安装编译目录下的redis.conf文件复制到redis-cluster/redis1|2|3|4|5|6文件夹下,并对redis.conf修改端口号:
分别进入各个文件夹下,修改redis.conf vi redis.conf
修改port 6379 改为7001 其他同理,改7002,7003.。。。
6> 分别启动6个redis节点的服务 ,验证端口修改是否成功 (这步可以不做)
7>准备集群:
redis集群的管理工具使用的是ruby脚本语言,安装集群需要ruby环境。

安装Ruby的打包系统,主要用gem命令:
还需要连接gem服务器,需要手工安装:
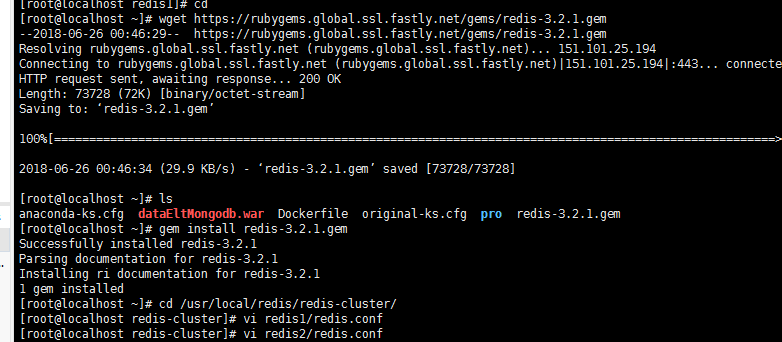
执行这个命令,加载gem命令:gem install redis-3.0.0.gem

8>集群的环境准备已经完成,下面在redis.conf配置允许集群:
把#注释放开:就行了,其他几个也是这样操作
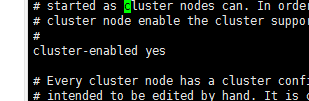
然后再次重启实例,第六步在这做也行,为了步骤完整,就都写出来了
9>集群管理工具在redis解压文件夹的src的文件夹中,使用redis-cluster的集群管理工具启动集群

10>启动集群
./redis-trib.rb create --replicas 1 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 127.0.0.1:7006 这个命令可以:
./redis-trib.rb create --replicas 1 192.168.146.132:7001 192.168.146.132:7002 192.168.146.132:7003 192.168.146.132:7004 192.168.146.132:7005 192.168.146.132:7006 (需要在etc把ip放出来才可以,我这里搭建的是测试环境,就不操作了)这步我执行这条命令报错是:

所以执行上面那条命令:集群启动效果如下:


看到ok代表集群启动成功了。
11>测试:加-c参数,节点之间就可以互相跳转
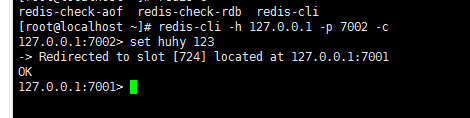

虽然查不到key,但是可以获取到值,说明集群是成功的。
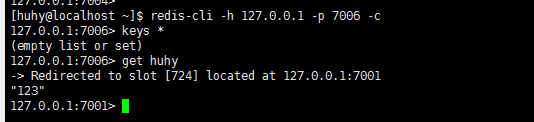
存到了7002上,转到7001,这是主节点,他们对应的slave点也会有这条数据,但是7003和7006上没有,测试成功: