1、设计短链服务
发号器 + 62进制
2、redis过期数据策略
惰性 + 定时
淘汰策略
3、缓存穿透、击穿、雪崩
穿透:返回NULL值, 设置NULL环境 布隆过滤器
击穿:热点KEY突然失效, 读取mysql加把锁
雪崩:多个KEY同时失效,KEY设置不同的过期时间
4、分布式锁
数据库 主键, 定时任务定期删除过期key
redis ,setnx expire delete
zk 零时节点 , watch
5、流控
计数器 : 分布式 redis incr,单机incrementAndGet
滑动窗口:1s=100ms+100ms+.. + 100ms, 分别计数
漏桶:请求放队列+定时线程获取请求
令牌桶:令牌放队列+定时线程放令牌; guava Ratelimiter
6、分布式id生成 要求唯一、有序、高可用
UUID
数据库自增Id 多台机器&不同步长、批量生成
redis incr
snowflake
7、悲观锁、乐观锁
悲观:
写多读少
synchronized、lock
乐观:
读多写少
CAS(ABA、自旋问题)、原子类
8、自己实现RPC怎么做
client stub、serverstub : 动态代理 java proxy 、字节码增强
传输协议: netty
序列化: protobuf
注册中心: zk etcd
服务器线程模型
其他:
应用层http http+json 共有协议 对外
传输层tcp netty+二进制 私有协议 对内
负载均衡
https://zhuanlan.zhihu.com/p/67043270
9、两个线程顺序打印奇偶数
a:
volatile boolean flag;
AtomicInteger num;
CountDownLatch latch;

b:
wait notify synchronize

https://www.jianshu.com/p/f4454164c017
http://javatiku.cn/2019/03/14/odd-thread.html
10、大数据量算法
分治、堆排序、归并排序、二分查找、bitmap、布隆过滤
11 、 C10K问题
单机1w网络连接问题
解决:IO多路复用 select poll epoll(O(1))
12、zero copy
https://www.jianshu.com/p/a4325188f974
13、手写连接池
14、netty高性能
https://www.cnblogs.com/94cool/p/5453033.html
15、响应式编程
https://segmentfault.com/a/1190000017548728
16、库存超发问题 解决方案
悲观锁 数据库事物select for update
乐观锁 版本号
redis + lua
17、mysql
索引:
隔离级别:
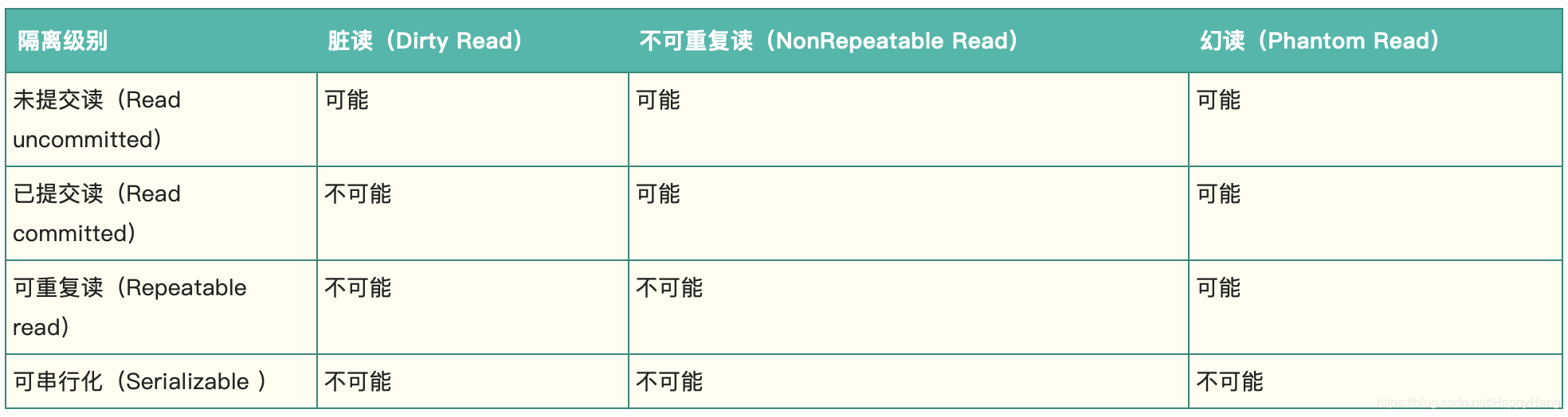
脏读即为session A读取到了session B中未提交的数据
不可重复读即为session A读取到了session B提交的数据,即前后session A读取的数据不一致
幻读即为session A读取到了session B insert的数据。
18、单例模式
https://www.cnblogs.com/wuzhenzhao/p/9923309.html
19、pritobuf特点
二进制协议
语言无关
高效(小、快)
扩展性、兼容性
约束性强 直接生成model
20、幂等的实现
业务唯一id 数据库/redis
21、CMS算法
- 初始标记(CMS initial mark) STW
- 并发标记(CMS concurrent mark)
- 重新标记(CMS remark) STW
- 并发清除(CMS concurrent sweep)
22、G1算法
G1重新定义了堆空间,打破了原有的分代模型,将堆划分为一个个区域。这么做的目的是在进行收集时不必在全堆范围内进行,这是它最显著的特点
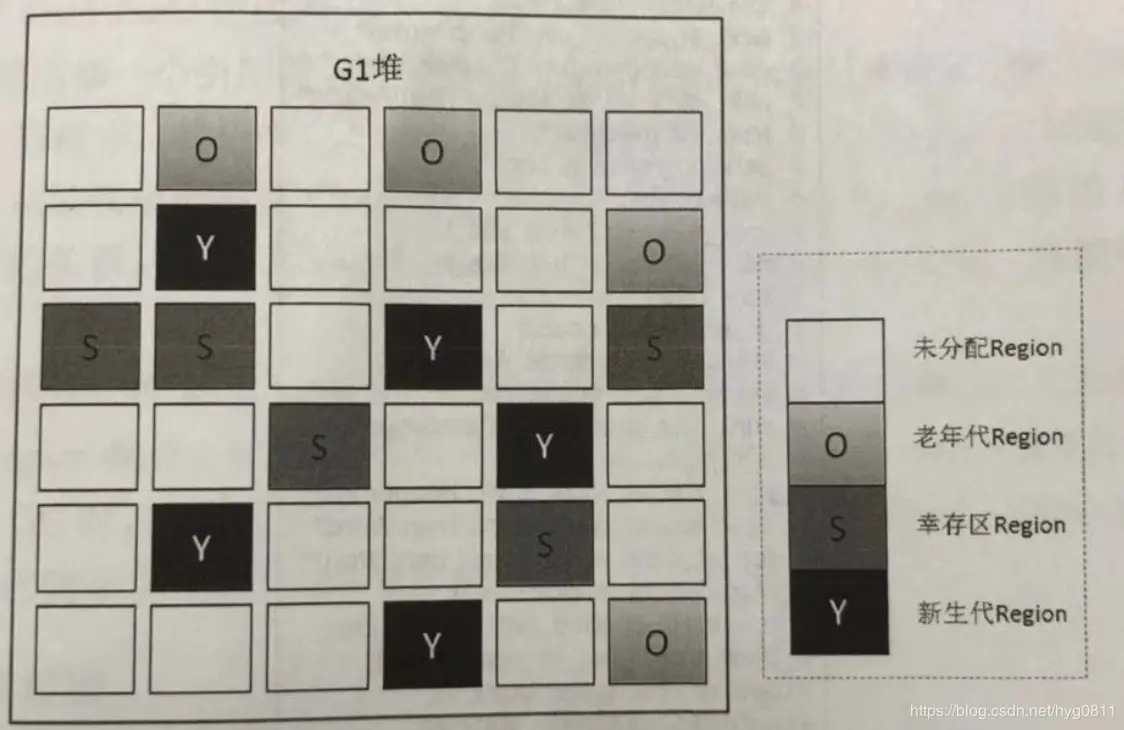
https://blog.csdn.net/jiankunking/article/details/85626279
23、mysql索引
B+树和B树
单一节点存储的元素更多,使得查询的IO次数更少,所以也就使得它更适合做为数据库MySQL的底层数据结构了。
所有的叶子节点形成了一个有序链表,更加便于查找。
24、hashMap 、 concurrentHashMap
hashMap : 数据 + 链表 红黑树
concurrentHashMap:
1.7 segment 分段式锁
1.8 Node CAS + synchronize
首先通过 hash 找到对应链表过后, 查看是否是第一个object, 如果是, 直接用cas原则插入,无需加锁。
然后, 如果不是链表第一个object, 则直接用链表第一个object加锁,这里加的锁是synchronized,虽然效率不如 ReentrantLock, 但节约了空间,这里会一直用第一个object为锁, 直到重新计算map大小, 比如扩容或者操作了第一个object为止。

25、AQS
state queue
26、redis
高性能:
纯内存存储、IO多路复用技术、单线程架构
27、tcp iostat timewait


28、设计模式
创建、结构、行为
https://javadoop.com/post/design-pattern
29、dubbo 和 thrift
https://blog.csdn.net/zl_StepByStep/article/details/89303881#%E2%97%8F%C2%A0Dubbo
https://www.jianshu.com/p/f2b8e0b11f73
https://www.infoq.cn/article/ujea*5ch0HjW2racClC9
30 、Hystrix
https://segmentfault.com/a/1190000005988895
断路器: 打开 关闭 半打开
Metric: 滑动窗口
隔离方式: 线程 & 信号量
在hystrix中,有5种异常会被fallback:
- FAILURE:执行失败,抛出异常。
- TIMEOUT:执行超时。
- SHORT_CIRCUITED:断路器打开。
- THREAD_POOL_REJECTED:线程池拒绝。
- SEMAPHORE_REJECTED:信号量拒绝。
参数配置 https://www.jianshu.com/p/3dfe6855e1c5
https://www.javazhiyin.com/25945.html
31、数据库和缓存数据一致性
https://www.cnblogs.com/lingqin/p/10279393.html
a、写数据库 + 更新缓存
线程安全问题, 写请求较多时会出现不一致问题,不推荐使用。
b、写数据库 + 删除缓存
Cache-Aside pattern
读快、写慢 出错的概率小,勉强推荐。
延时删除
c、删除缓存 + 写数据库
读请求较多时会出现不一致问题,不推荐使用。
采用延时双删策略
删除缓存失败问题: 自己消息队列 或 订阅binlog
https://www.cnblogs.com/llzhang123/p/9037346.html
32、jstack
系统问题排查工具、方法论
https://www.sohu.com/a/343836125_172964
33、netty
连接保持
常连接 心跳
34、zk 脑裂
投票>n/2
35、对象结构
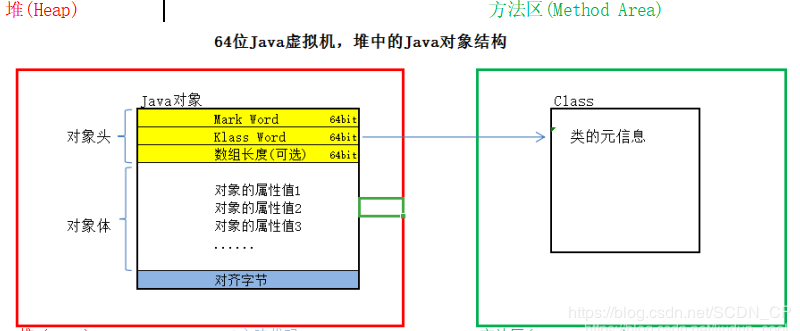
https://blog.csdn.net/scdn_cp/article/details/86491792
36、容量评估
日活DAU PV
2/8原则 80%请求20时间
qps 设置线程数
压测 系统水位
https://blog.csdn.net/java_zyq/article/details/84956659
qps*接口响应时间 + buffer
37、关于spring boot的优化
tomcat优化: connector io模型,线程池配置
jvm优化
https://www.cnblogs.com/kismetv/p/7806063.html
38、synhronized 优化
https://www.jianshu.com/p/46a874d52b71
39、 tcp流量控制 拥塞控制
流量控制是为了让接收方能来得及接收(端对端的通信),而拥塞控制是为了降低整个网络的拥塞程度(全局性)。
流量控制:
ack报文中的可用滑动窗口大小字段,控制客户端发送包的大小
拥塞控制:
算法支持: 慢开始,拥塞避免,快重传,快恢复
https://my.oschina.net/u/4045381/blog/3097269
40 zookeeper
分布式协议:zab协议
两个模式:消息广播、崩溃恢复
消息广播:类两阶段提交,过半commit
奔溃恢复:leader选举
ZAB 让整个 Zookeeper 集群在两个模式之间转换,消息广播和崩溃恢复,消息广播可以说是一个简化版本的 2PC,通过崩溃恢复解决了 2PC 的单点问题,通过队列解决了 2PC 的同步阻塞问题。
https://msd.misuland.com/pd/3070888491219950536

![]()
马通过zk感知到切换到备用进程
41 mysql 事物实现原理
https://www.jianshu.com/p/081a3e208e32
https://juejin.im/post/5cb2e3b46fb9a0686e40c5cb
- 事务的原子性是通过 undo log 来实现的
- 事务的持久性性是通过 redo log 来实现的
- 事务的隔离性是通过 (读写锁+MVCC)来实现的
- 而事务的终极大 boss 一致性是通过原子性,持久性,隔离性来实现的!!!
原子性,持久性,隔离性折腾半天的目的也是为了保障数据的一致性!
https://www.jianshu.com/p/081a3e208e32
42 分布式事物 方案
1、两阶段提交
事物管理器 、资源管理器
2、TCC
try confirm cancle
补偿的概念
3、本地消息表
业务+消息 ->
MQ ->
消息+业务
4、可靠消息最终一致性
RocketMQ
处理方 保证处理幂等
5、最大努力通知
最大努力通知服务
43、 mysql 分库分表
拆分方法:水平、垂直
架构:client 、独立server
迁移方案:
a、停机 + 后台迁移多线程程序
b、双写
双写、迁移数据、数据验证
https://juejin.im/entry/5b5eb7f2e51d4519700f7d3c
44、hashmap
resize:
扩容大小*2 重新计算hashcode做数据迁移 迁移完成修改引用 重新计算threshold
https://www.liangzl.com/get-article-detail-14655.html
链表头尾:
HashMap在jdk1.7中采用头插入法,在扩容时会改变链表中元素原本的顺序,以至于在并发场景下导致链表成环的问题。而在jdk1.8中采用尾插入法,在扩容时会保持链表元素原本的顺序,就不会出现链表成环的问题了。
https://juejin.im/post/5ba457a25188255c7b168023
https://www.cnblogs.com/chengxiao/p/6059914.html#3981914
45、thrift
-
传输层(
Transport Layer):传输层负责直接从网络中读取和写入数据,它定义了具体的网络传输协议;比如说TCP/IP传输等。 -
协议层(
Protocol Layer):协议层定义了数据传输格式,负责网络传输数据的序列化和反序列化;比如说JSON、XML、二进制数据等。 -
处理层(
Processor Layer):处理层是由具体的IDL(接口描述语言)生成的,封装了具体的底层网络传输和序列化方式,并委托给用户实现的Handler进行处理。 -
服务层(
Server Layer):整合上述组件,提供具体的网络线程/IO服务模型,形成最终的服务。
https://juejin.im/post/5b290dbf6fb9a00e5c5f7aaa
https://andrewpqc.github.io/2019/02/24/thrift/
46 dubbo 使用协议
https://juejin.im/post/5ce82b496fb9a07ea9444b04
47 java实现死锁
Object A;
Object B;
thread1:
synchronize (A){
synchronize (B){
}
}
thread2:
synchronize (B){
synchronize (A){
}
}
48 redis 为啥单线程
因为CPU不是Redis的瓶颈。Redis的瓶颈最有可能是机器内存或者网络带宽。
既然单线程容易实现,而且CPU不会成为瓶颈,那就顺理成章地采用单线程的方案了。
https://www.iteye.com/blog/uule-2432048
高性能:
单线程(无上下文切换、加锁)
io多路复用 epoll模型
纯内存操作
数据结构设计
49 redis高级命令
multi exec watch
https://www.jianshu.com/p/f6d26f82fa30
50 kafka 高可用
Partition 冗余多个副本
producer ack : 0 1 all
高性能:
读 :sendfile zero copy
写: 顺序写、mmp 内存映射文件
压缩
https://juejin.im/post/5e847f6951882573b753674d
51 jvm gc 分配担保机制
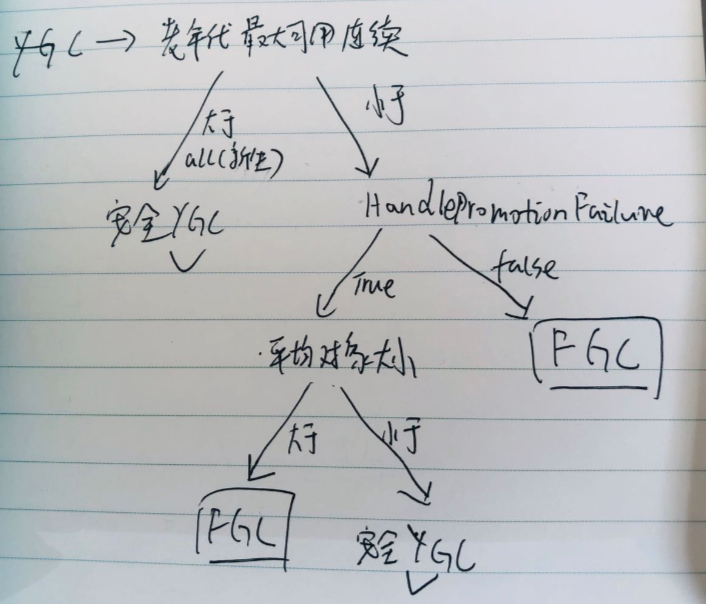

避免Full GC过于频繁
https://zhuanlan.zhihu.com/p/41139289
52 protobuf 底层原理
1、信息紧凑、更小更 varint 类似与mysql varchar
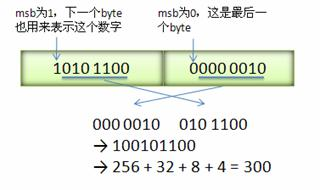
2、封包结构
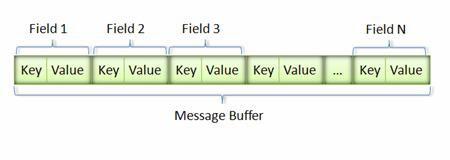
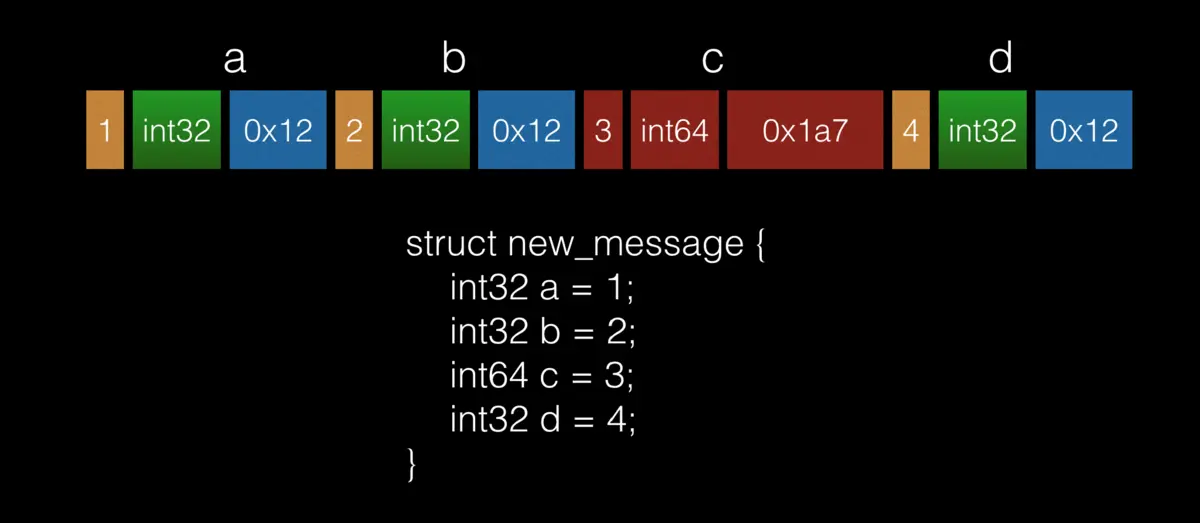
key : 标示数字id + 数据类型
https://www.cnblogs.com/onlysun/p/4569595.html
https://www.jianshu.com/p/522f13206ba1
53、redis 数据结构优化
sds
跳表
...
54、 CopyOnWriteList
读写分离的思想
读的时候不加锁 读旧的,写的时候加锁,防止有多个copy
延时懒惰策略 , 可能会有延迟
候,我们的系统应对的都是读多写少的并发场景。CopyOnWriteArrayList容器允许并发读,读操作是无锁的,性能较高。至于写操作,比如向容器中添加一个元素,则首先将当前容器复制一份,然后在新副本上执行写操作,结束之后再将原容器的引用指向新容器。
https://www.cnblogs.com/chengxiao/p/6881974.html
55、jmm happen before原则
前一个操作的结果,可以被后续的操作获取,即内存可见性。
happens-before规则非常重要,它是判断数据是否存在竞争、线程是否安全的主要依据
时间先后顺序与happens-before原则之间基本没有太大的关系,所以我们在衡量并发安全问题的时候不要受到时间顺序的干扰,一切必须以happens-before原则为准。
-
单线程中,程序顺序执行,即上面的操作先于>下面的操作;
-
一个unlock先于>随后对同一个锁的lock操作;
-
volatile变量的写操作先于>任意后续对该变量的读操作;
-
一个线程start()方法先于>该线程每一个操作;
-
线程所有方法先于>该线程的结束状态;
-
对线程interrupt()的调用先于>检测到该线程中断事件的发生;
-
一个对象初始化完成(构造函数执行完成)先于>该对象finalize()的执行;
-
传递性,A>B,B>C,则A>C;
https://zhuanlan.zhihu.com/p/90050523
56、读取jvm配置的类
ManagementFactory
57、CMS 浮动垃圾 、垃圾碎片 、 concurrent mode failure
CMS是基于标记-清除算法的,CMS只会删除无用对象,不会对内存做压缩,会造成内存碎片,这时候我们需要用到这个参数:-XX:CMSFullGCsBeforeCompaction=n 意思是说在上一次CMS并发GC执行过后,到底还要再执行多少次full GC才会做压缩。默认是0promotion),而此时年老代满了无法容纳更多对象,通常伴随full gc,因而导致的promotion failure。这种情况通常需要增加年轻代大小,尽量让新生对象在年轻代的时候尽量清理掉。
https://blog.csdn.net/yangguosb/article/details/79857844
https://www.jianshu.com/p/ad00621d675a
https://www.cnblogs.com/bootdo/p/10482853.html
https://segmentfault.com/q/1010000013977499/a-1020000013979688
https://my.oschina.net/hosee/blog/674181
https://juejin.im/post/5c7262a15188252f30484351
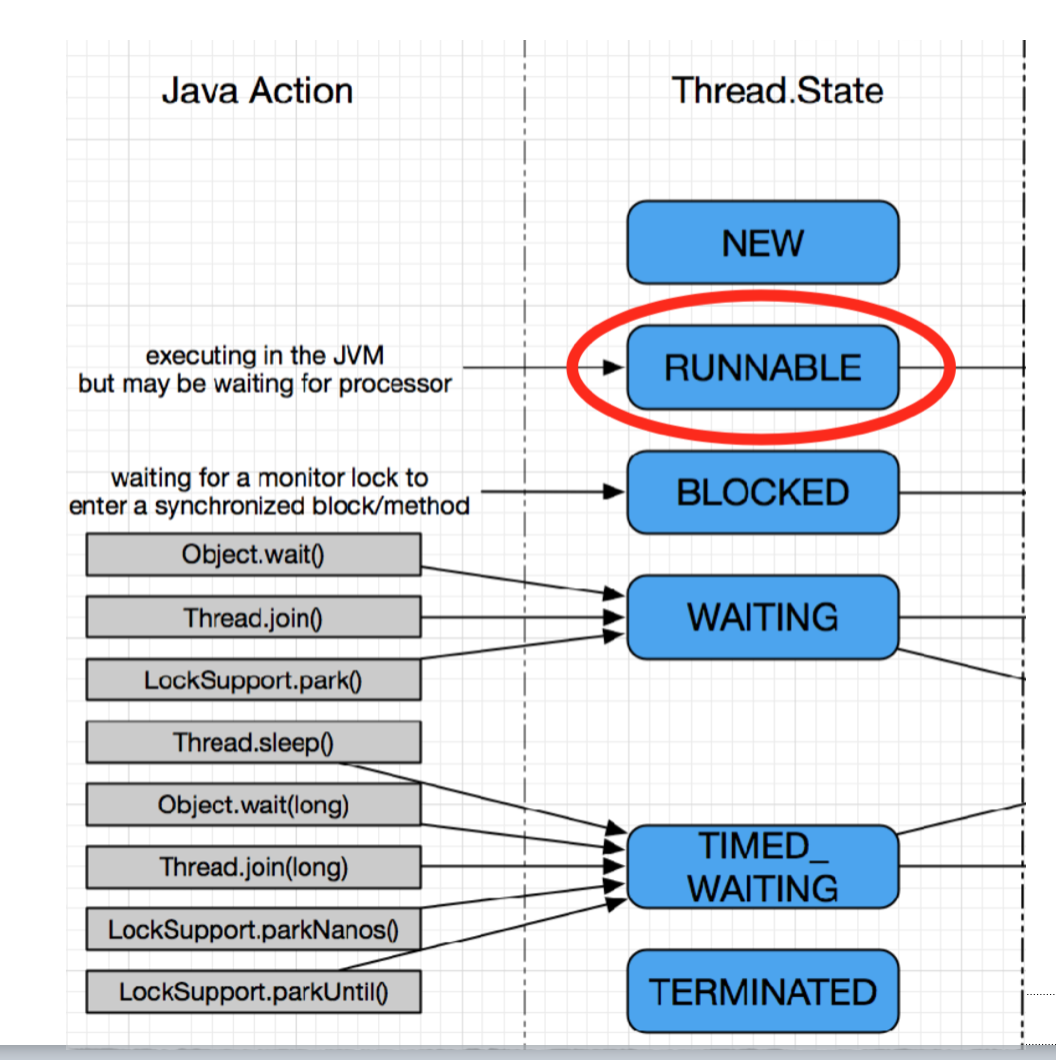
58、线程的状态
等待 阻塞
|
状态名称 |
说明 |
|---|---|
|
NEW |
初始状态,线程被构建,但是还没有调用start()方法 |
|
RUNNABLE |
运行状态,Java线程将操作系统中的就绪和运行两种状态笼统地成为“运行中” |
|
BOLCKED |
阻塞状态,一般指线程阻塞于锁 |
|
WAITING |
等待状态,表示线程进入等待状态,一般是线程执行过程中调用的某个对象的wait()、await()方法, 进入该状态表示当前线程需要等待其他线程做出一些特定动作(通知或中断,即notify(),notifyAll(),interrupted()等) |
|
TIME_WAITING |
超时等待状态,该状态不同于WAITING,他是可以在指定的时间自行返回的,一般线程在调用了 sleep(time)后会处于此状态 |
|
TERMINATED |
终止(消亡)状态,表示当前线程已经执行完毕 |
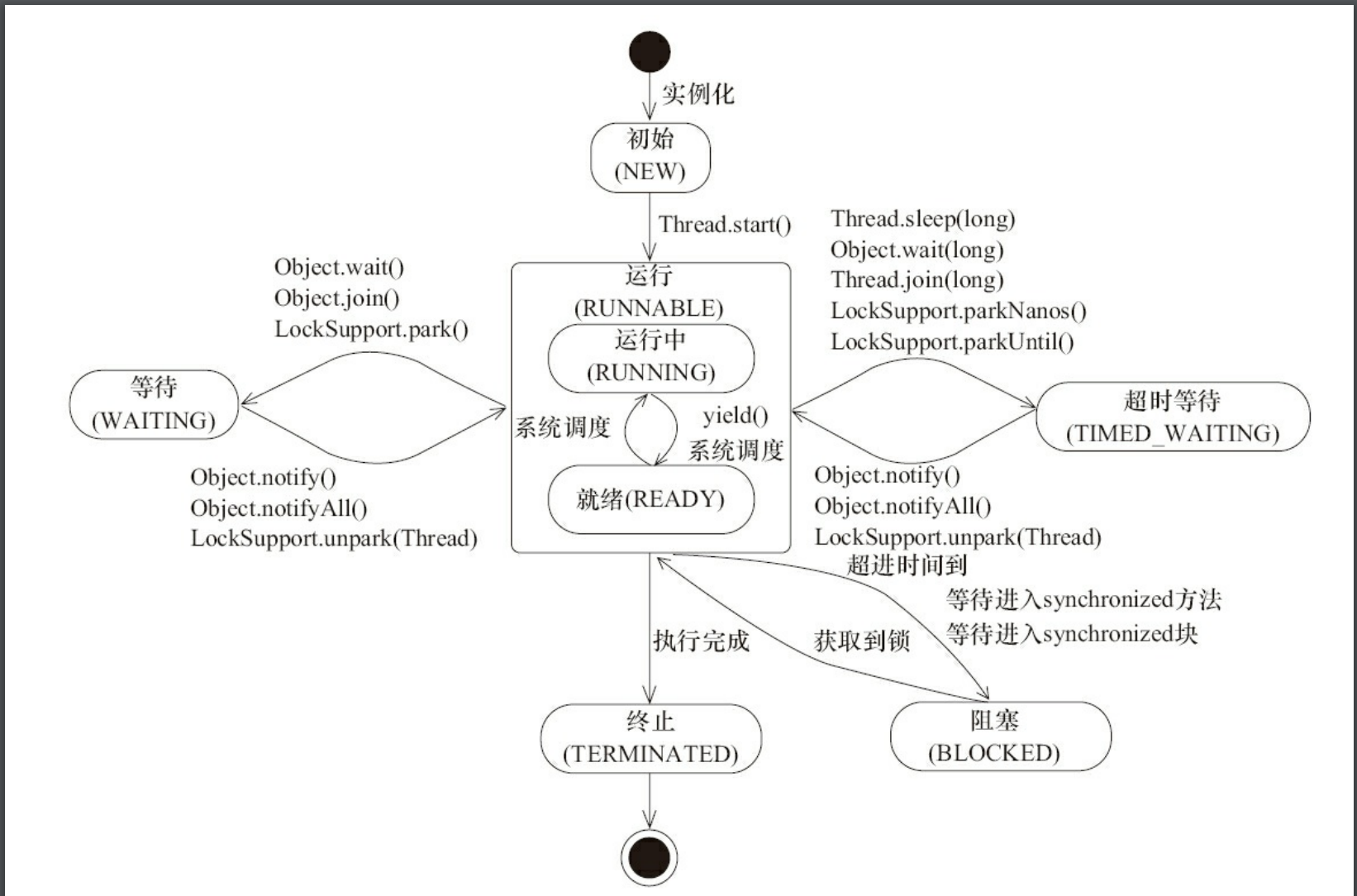
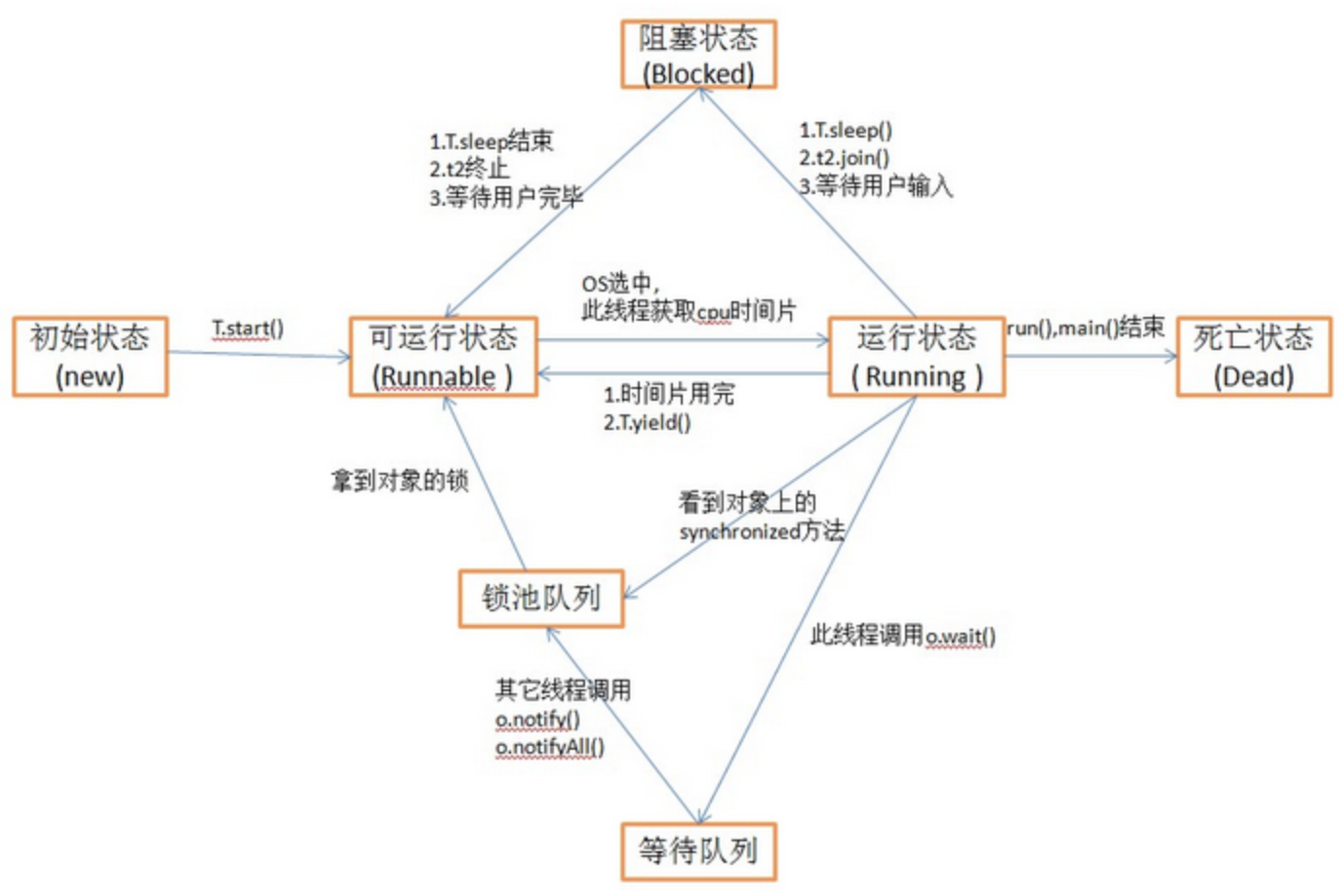
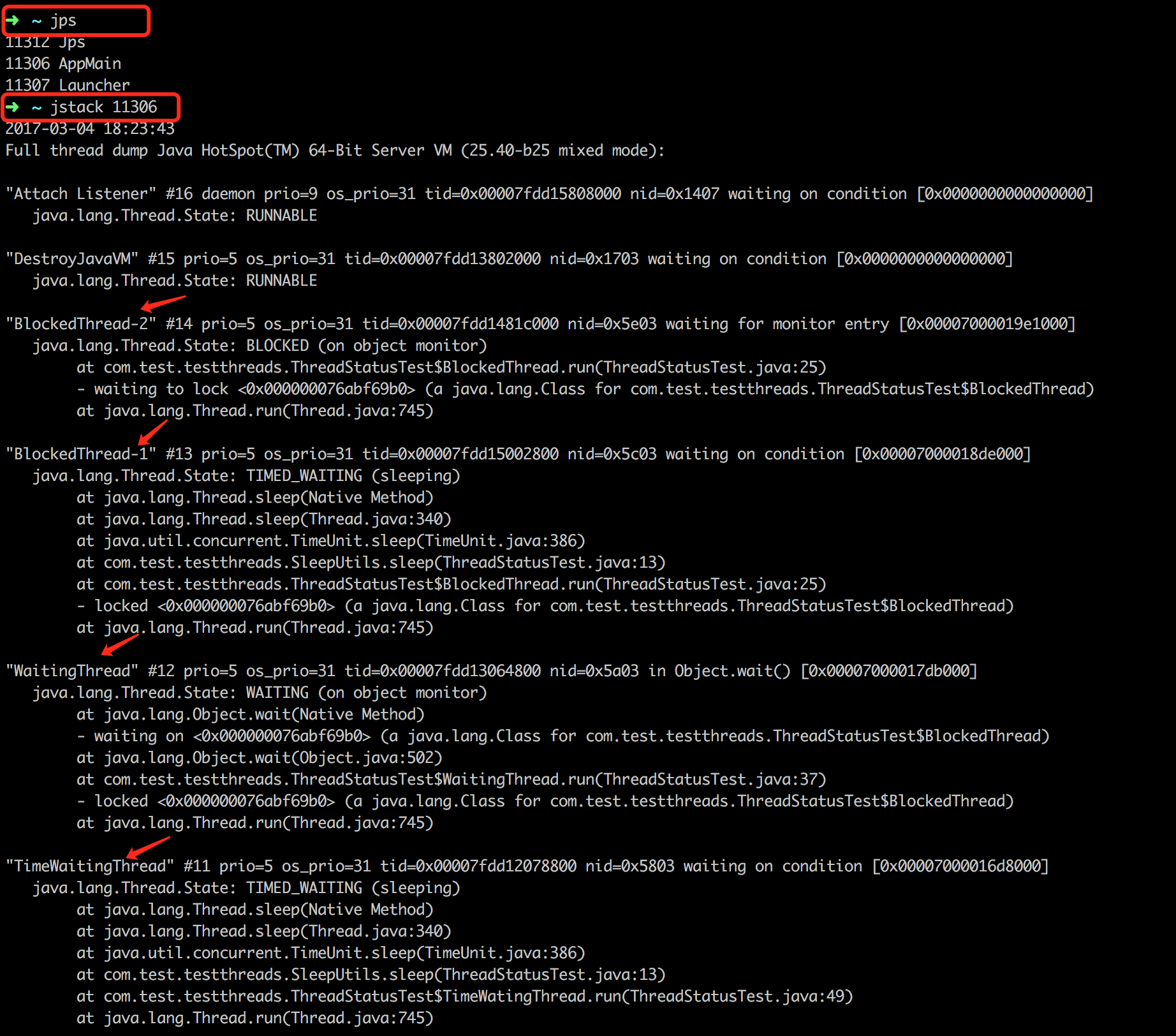
59、JVM参数模板

60、关于JAVA中的String类
String实质是字符数组,两个特点:
1、该类不可被继承;
2、不可变性(immutable),是线程安全的;
定义:
"xx"
new String("xxx")
"x" + "y"
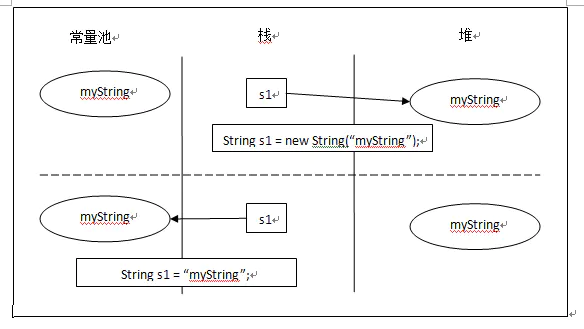
https://www.jianshu.com/p/4b2db583b0ff
61 zookeeper 顺序一致 线性一致
https://blog.51cto.com/14230003/2431702
62 服务通信
a 轮训调用
b 容错

63 、单例双重锁的坑
问题:

解决:
instance声明为volatile,禁止指令重排序
https://www.jianshu.com/p/1c72a061b40e
64 、 垃圾回收 TLAB
65、JDK里的设计模式
https://blog.csdn.net/caoxiaohong1005/article/details/79961539
66、mysql常用优化 高级
67、并发包下常用的类
68、https 加密的过程
HTTPS要使客户端与服务器端的通信过程得到安全保证,必须使用的对称加密算法,但是协商对称加密算法的过程,需要使用非对称加密算法来保证安全,然而直接使用非对称加密的过程本身也不安全,会有中间人篡改公钥的可能性,所以客户端与服务器不直接使用公钥,而是使用数字证书签发机构颁发的证书来保证非对称加密过程本身的安全。这样通过这些机制协商出一个对称加密算法,就此双方使用该算法进行加密解密。从而解决了客户端与服务器端之间的通信安全问题。
CA证书、非对称加密、对称加密
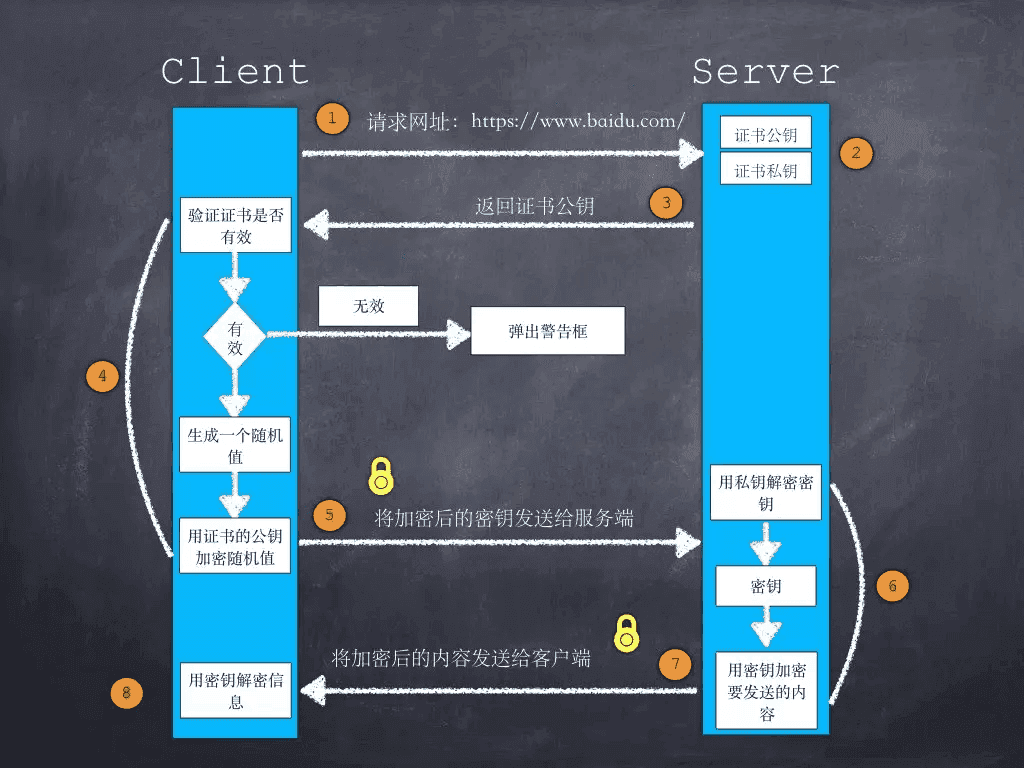
69、ssl dos crlf 安全攻击原理
70、http协议 1.0 1.1 2.0 3.0
- HTTP/1.x 有连接无法复用、队头阻塞、协议开销大和安全因素等多个缺陷
- HTTP/2 通过多路复用、二进制流、Header 压缩等等技术,极大地提高了性能,但是还是存在着问题的
- QUIC 基于 UDP 实现,是 HTTP/3 中的底层支撑协议,该协议基于 UDP,又取了 TCP 中的精华,实现了即快又可靠的协议
https://www.ruanyifeng.com/blog/2016/08/http.html
https://blog.fundebug.com/2019/03/07/understand-http2-and-http3/
71、锁优化
https://www.jianshu.com/p/3aac4239a84c
偏向锁 轻量锁 重量锁
72、实现生产者消费者模型
https://www.cnblogs.com/twoheads/p/10137263.html
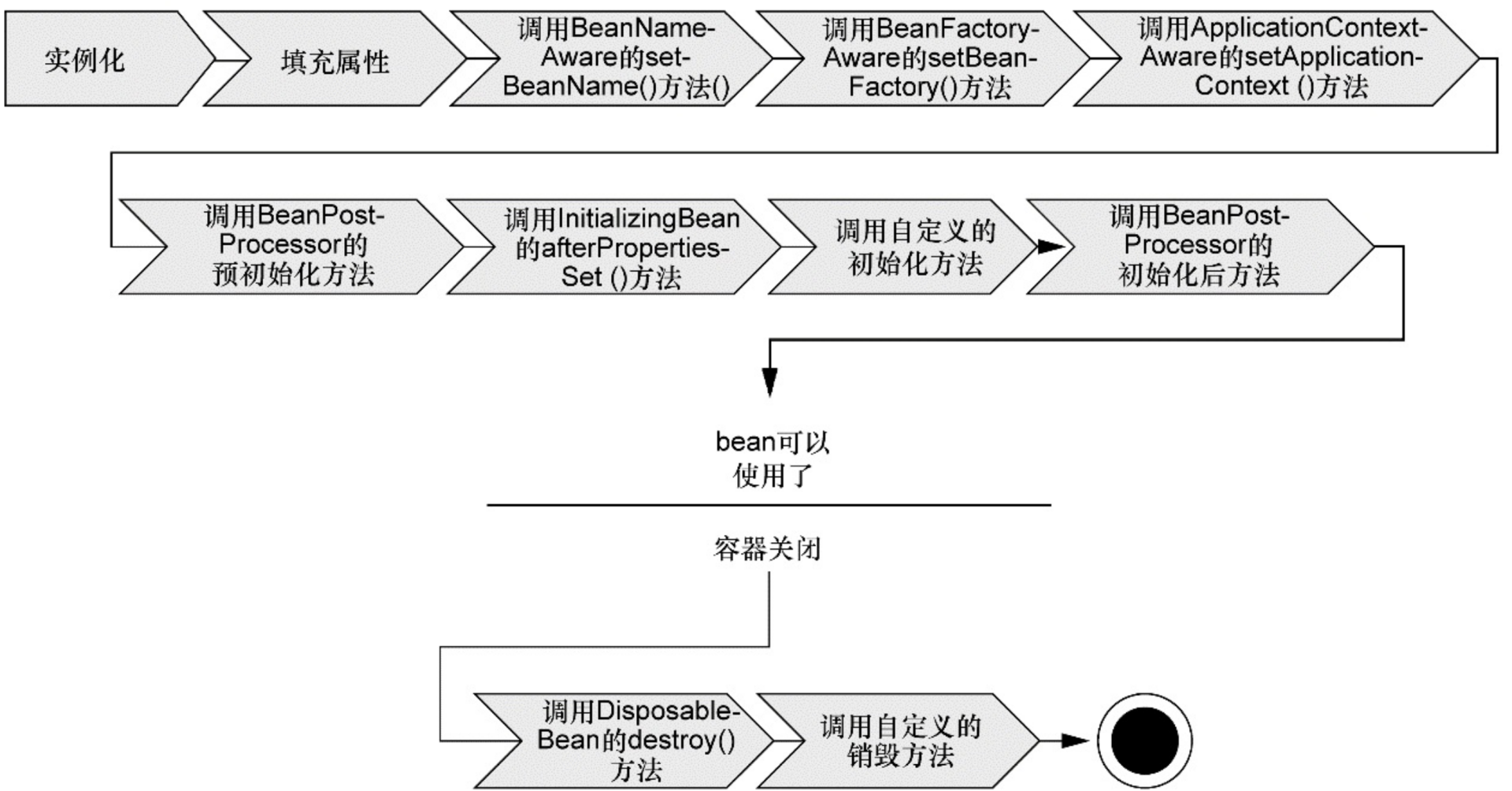
73、spring bean 生命周期
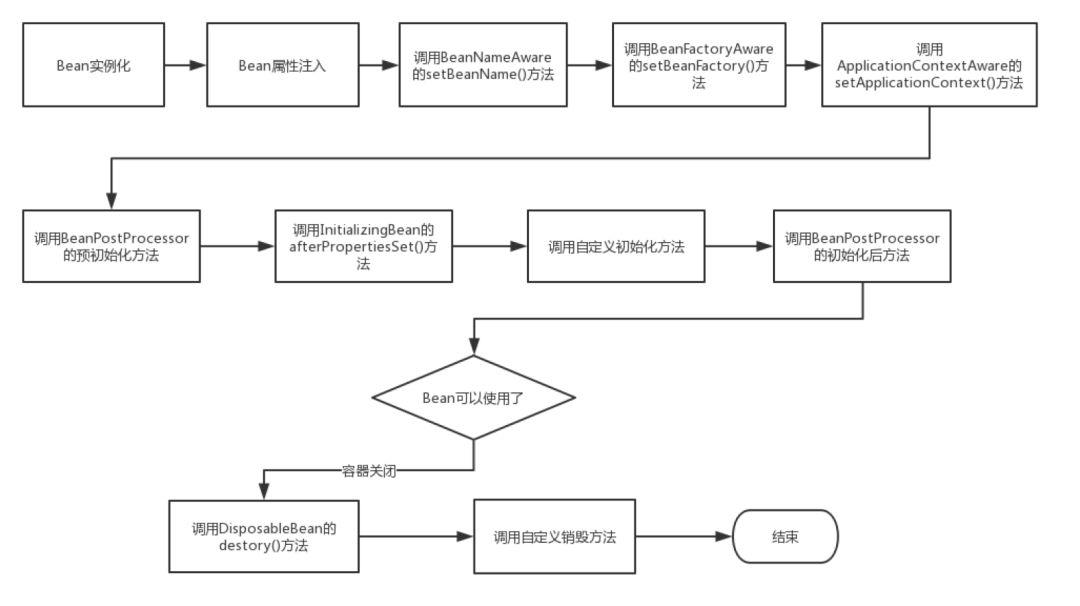
bean内部准备工作:
PostConstruct (P),afterPropertiesSet (A),init-method (I) ---> PAI (圆周率π)
注解 - @PostConstruct
接口 - public interface InitializingBean { void afterPropertiesSet() throws Exception; }
属性 - <bean id="myClass" class="com.demo.MyClass" init-method="init"/>
BeanPostProcessor 切面 ,在前后分别执行

|
类型 |
方法 |
调用方式 |
作用 |
|---|---|---|---|
|
Bean自身的方法 |
Bean本身调用的构造方法和setter方法,以及init-method和destroy-method指定的方法 |
反射 |
实现用户自定义的bean创建销毁过程 |
|
Bean级生命周期接口方法 |
BeanNameAware、BeanFactoryAware、ApplicationContextAware、InitializingBean和DiposableBean等接口的方法 |
使用instanceof检查是否实现该接口,如果实现强转后执行 |
让bean获取其名字、工厂、上下文,以及基于spring的bean创建和销毁方法 |
|
容器级生命周期接口方法 |
BeanPostProcesser的postProcessBeforeInitialization和postProcessAfterInitialization方法 |
遍历全部BeanPostProcesser的列表,按顺序执行processer的方法 |
容器级的处理器,对于该容器内bean生效,在bean的自定义初始化方法前后插入处理逻辑 |
https://www.javazhiyin.com/37577.html
DIY

http://www.spring4all.com/article/15121
74、Spring bean 循环依赖
BeanDefinition
bean生命周期
Spring bean 和 java对象区别
bean 三级缓存:
singletonObjects singletonFactories earlySingletonObects
bean对象池spring容器、bean工厂、beanearly对象
https://zhuanlan.zhihu.com/p/62382615
https://juejin.im/post/5e927e27f265da47c8012ed9
75 MVCC
https://zhuanlan.zhihu.com/p/64576887
76 lock + Condition
https://blog.csdn.net/SEU_Calvin/article/details/70211712
https://www.jianshu.com/p/58651d446e03
77 同步 异步 阻塞 非阻塞
IO分两阶段(一旦拿到数据后就变成了数据操作,不再是IO): 1.数据准备阶段 2.内核空间复制数据到用户进程缓冲区(用户空间)阶段
https://www.cnblogs.com/loveer/p/11479249.html
阻塞与非阻塞:区别在于完成一件事情时,当事情还没有完成时,处理这件事情的人除此之外不能再做别的事情;
select的调用复杂度是线性的,即O(n)。举个例子,一个保姆照看一群孩子,如果把孩子是否需要尿尿比作网络IO事件,select的作用就好比这个保姆挨个询问每个孩子:你要尿尿吗?如果孩子回答是,保姆则把孩子拎出来放到另外一个地方。当所有孩子询问完之后,保姆领着这些要尿尿的孩子去上厕所(处理网络IO事件)。
在epoll机制下,保姆不再需要挨个的询问每个孩子是否需要尿尿。取而代之的是,每个孩子如果自己需要尿尿的时候,自己主动的站到事先约定好的地方,而保姆的职责就是查看事先约定好的地方是否有孩子。如果有小孩,则领着孩子去上厕所(网络事件处理)。因此,epoll的这种机制,能够高效的处理成千上万的并发连接,而且性能不会随着连接数增加而下降。
https://blog.51cto.com/dadonggg/1947838
select
限制1024
遍历数组
内存拷贝
poll
无限制
遍历链表
内存拷贝
epoll
无限制
共享内存 + 红黑树 + 双向链表
https://www.jianshu.com/p/f2ed97022041
79 IO操作
一次网络数据读取操作(read),可以拆分成两个步骤:
1)网卡驱动等待数据准备好(内核态)
2)将数据从内核空间拷贝到进程空间(用户态)。
80 jvm 关闭钩子
kill-9pid 可以理解为操作系统从内核级别强行杀死某个进程, kill-15pid 则可以理解为发送一个通知,告知应用主动关闭。
kill 9 强制
kill 15 信号量, 关闭钩子程序执行
外部:通知下线
内部:线程池关闭
Spring : disableBean destory()
https://cloud.tencent.com/developer/article/1110765
https://www.jianshu.com/p/e8fba41fa501
81、threadlocal
强 软 弱 虚引用
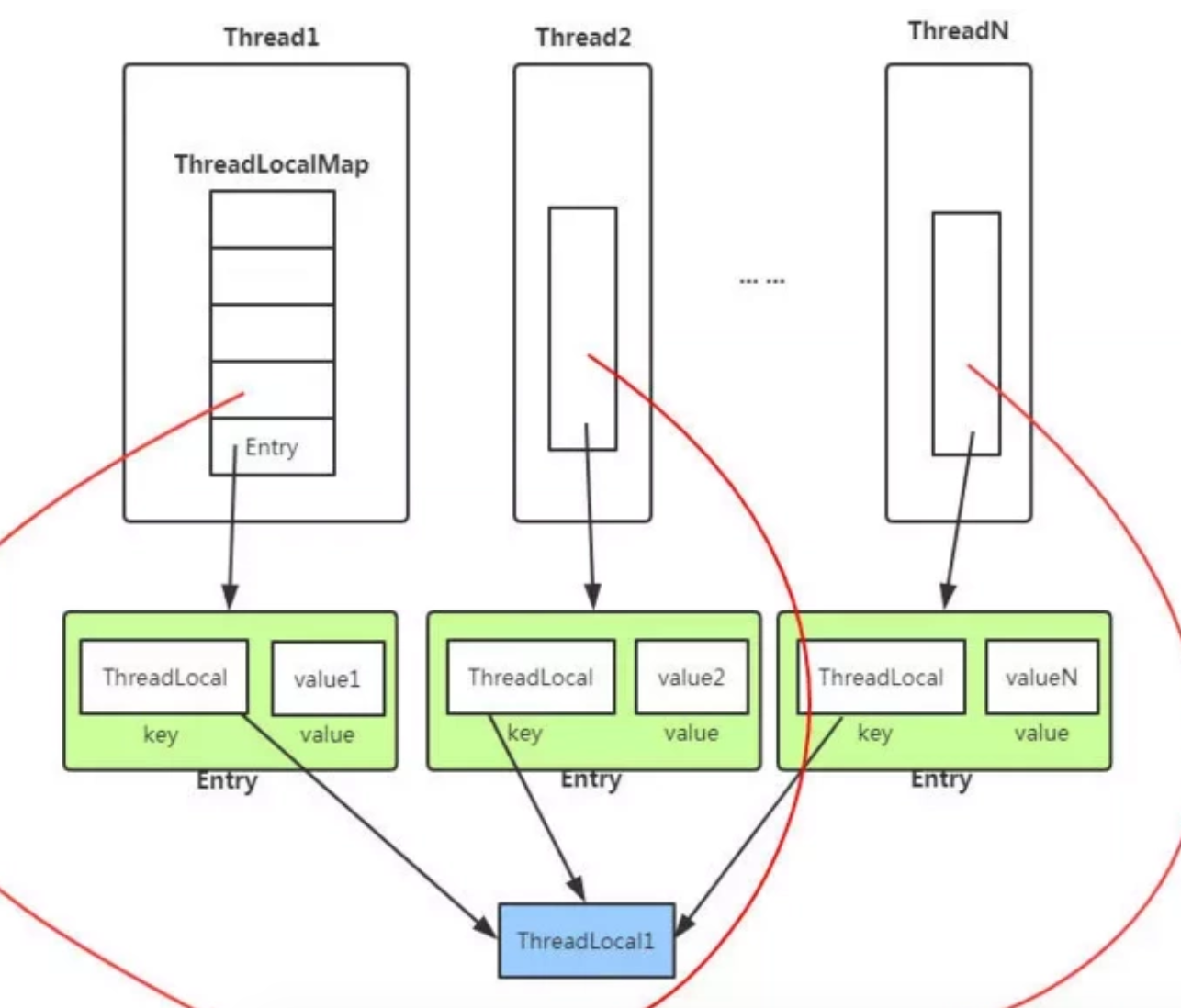
https://blog.csdn.net/qq_30409323/article/details/88945127
https://segmentfault.com/a/1190000020914820
82 fork join
任务窃取算法
83 LRU的算法实现
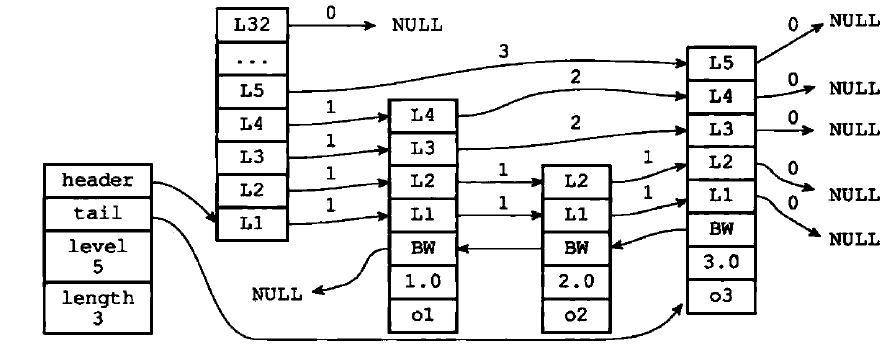
84 跳表实现
空间换时间
上一层为下一层的索引
85 分布式锁
setnx redlock redission
https://zhuanlan.zhihu.com/p/111354065?from_voters_page=true
https://blog.csdn.net/X_X_K/article/details/90144862
https://www.jianshu.com/p/7e47a4503b87
https://blog.csdn.net/stone_yw/article/details/88062938
86、 ZeroCopy
传统方法:
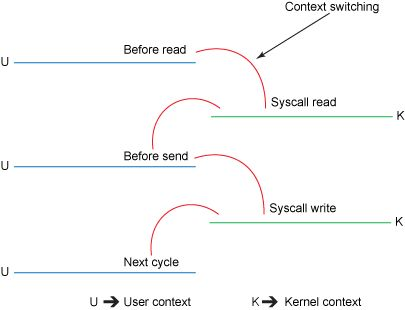
read ->
send
sendfile技术:
通过sendfile实现的零拷贝I/O只使用了2次用户空间与内核空间的上下文切换,以及3次数据的拷贝。其中3次数据拷贝中包括了2次DMA拷贝和1次CPU拷贝。
sendfile系统调用
MMP内存映射文件技术:
mmap(内存映射)是一个比sendfile昂贵
通过mmap实现的零拷贝I/O进行了4次用户空间与内核空间的上下文切换,以及3次数据拷贝。其中3次数据拷贝中包括了2次DMA拷贝和1次CPU拷贝。
mmap系统调用write系统调用
https://www.jianshu.com/p/e76e3580e356
87、zk实现读写锁
顺序节点
读锁 监听前面的一个写锁
写锁 监听前一个锁
countDownLatch阻塞
88、kafka保障消息有序处理
- 一个 topic,一个 partition,一个 consumer,内部单线程消费,单线程吞吐量太低,一般不会用这个。
- 写 N 个内存 queue,具有相同 key 的数据都到同一个内存 queue;然后对于 N 个线程,每个线程分别消费一个内存 queue 即可,这样就能保证顺序性。
http://www.mamicode.com/info-detail-2971151.html
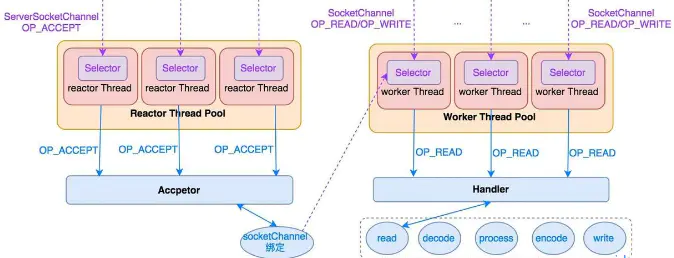
89、Reactor模型
分治 :
Reactor模式将每个步骤映射为一个Task,服务端线程执行的最小逻辑单元不再是一次完整的网络请求,而是Task,且采用非阻塞方式执行。
事件驱动 :
每个Task对应特定网络事件。当Task准备就绪时,Reactor收到对应的网络事件通知,并将Task分发给绑定了对应网络事件的Handler执行。
selector:负责监听响应事件,将事件分发给绑定了该事件的Handler处理;
Handler:事件处理器,绑定了某类事件,负责执行对应事件的Task对事件进行处理;
Acceptor:Handler的一种,绑定了connect事件。当客户端发起connect请求时,Reactor会将accept事件分发给Acceptor处理。
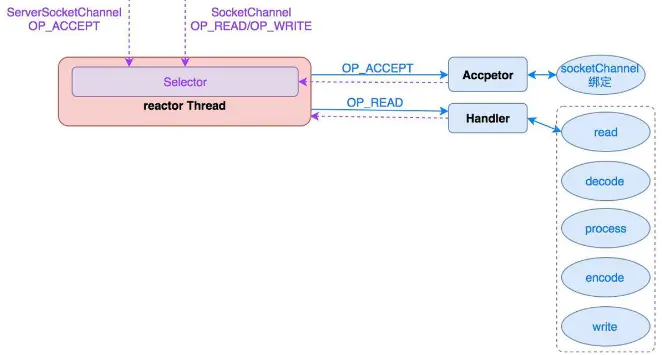
多线程
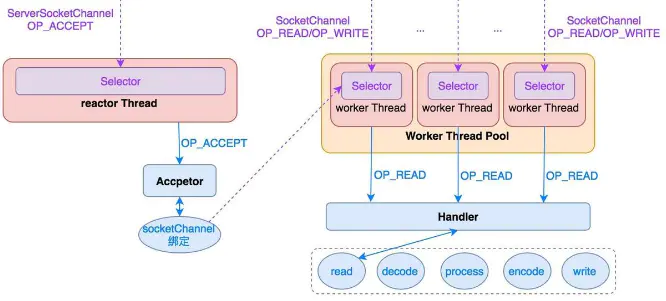
主从多线程