首先,为什么需要定制呢?很多同学可能觉得默认的不也挺好的嘛?最开始,我也是觉得的,而且我们一开始也是用默认的解析方式的,因为我们与外部约定的数据格式一直都比较稳定。但当外部数据不稳定,那么Gson默认配置的弊端就体现出来。很多同学可能觉得,你应该叫后台改啊,坦白说,我也觉得是这样的,毕竟我们都是按协议去开发数据模型的,你不按约定的协议去做,不是你的锅,难道是我的啊?!首先,一点是明确的,那就是如果后台没有按双方之前约定的格式输出数据,那一定是后台的问题,这点,我也不否认的。
但是,我始终觉得,我们所有的开发和努力都应该是为了更好地服务用户而做的。简而言之,我们是为产品的最终用户负责的。而作为最靠近用户一端的APP,责无旁贷地要肩负起这个潜在的责任。后台数据错了,我们可以认为外部环境有问题了,APP运行的外部环境出问题了,当然APP肯定很难独善其身,但我们更应该尽可能地减少对用户的影响,而之后的分锅大会毕竟是我们内部的事了……
好,那我们说说,为什么Gson的默认配置有那些对于我们来说是缺陷的问题,
1、一个字段有错,则整个字段出错。//但是我们希望这个字段出错,就不要解析这个字段了;
2、字段如果是null的话,则该字段就为null。//但是我们希望所有字段不要有null值存在,特别是基本数据类型;
3、如果该字段是一个对象,则定义为String就报错。//但是我们希望的是无论是什么字段,只要定义为String就永远是对的;
而这些要求Gson的默认配置都是不能满足的,要自己去定义。很多同学可能觉得,要求这么多,新加坡硕士留学条件还不如自己做个Json解析器得了。真心话是:不到万不得已,不要自己去造轮子。因为人生苦短……,如果必须得造,也尽量参考成熟的轮子,毕竟已经使用这么多年,总归会有些经验值得借鉴的。
我们定制的时候更多也是参考内置解析器去做的,有的是直接改内置解析器去做的。这样即安全,也高效。
gson在做解析的时候内部全是基于JsonReader去操作的,所以理解这个类是进行解析的关键。如果大家去搜就会发现,其实没有什么博客去写这个类的使用。但是作为过来人,我知道大家肯定很想有个“从入门到精通”的博客来给大家介绍这个类。那这个教程在哪?就是这个类的源码!如果,你看不下去,哪后面可能就不太好理解了……
因为JsonReader对每一步操作都有个判断的枚举类:JsonToken。这个枚举类包含了每一个将要进行的操作的字段类型:
BEGIN_ARRAY, END_ARRAY, BEGIN_OBJECT, END_OBJECT, NAME, STRING, NUMBER, BOOLEAN, NULL, END_DOCUMENT
其含义直接看名字就知道。这也是我们进行自定义解析的前提。
1、如何知道哪个字段出错呢?就是通过判断JsonReader.peek()去获取即将要操作的字段信息是否与返回的类型相匹配,如果不能匹配,那就会报错。
所以,如果我们可以修改为,如果不匹配就直接忽略该字段;比如我们要解析的是List,但是我们通过peek后发现即将操作的并不是List,有可能是null或者空的Object,那我们便可以忽略该字段,而直接返回一个空的List。核心代码如下:
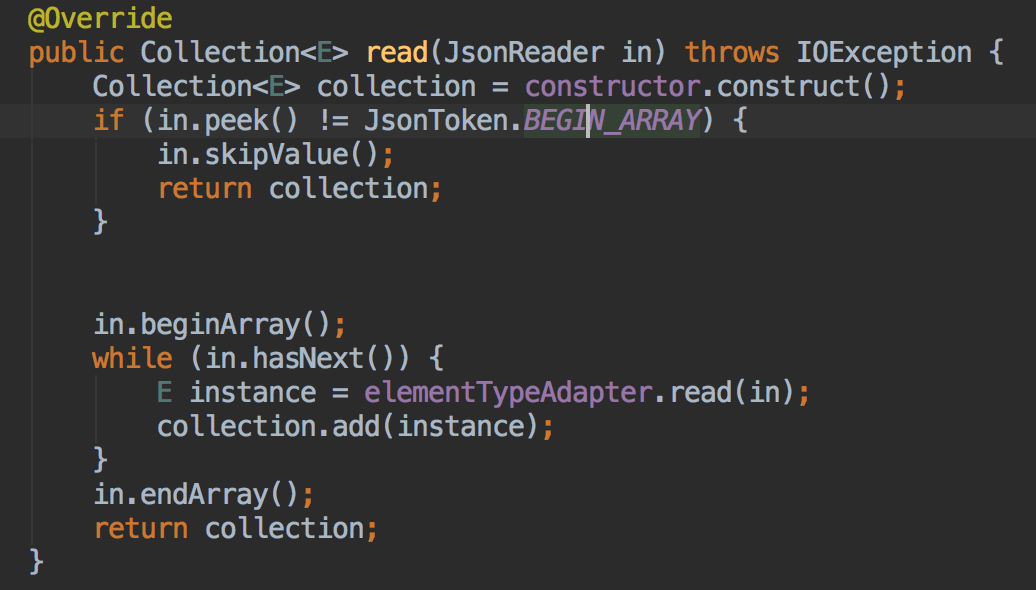
2、所以如果要知道每个字段出错了,那就得每个都判断一下,这比较繁琐,但是只有这种办法。但是由于最基本的结构通常都是:int、long、float、double、String五种,我们可以先自定义这五种,如果后面还有写比较奇怪的类型,我们可以再慢慢加加。
3、首先我们解析的就是String,为什么定义一个字段为String竟然不能成功。所以我们得单独为String做个比较特别的解析器。就是除了正常的String字段以外,即便它不是String,比如数组或者对象,我们依然能够进行String的解析。核心代码如下:

经过这样的定制以后,Gson的解析就可以符合我们的开篇的需求了。