一、功能描述
想用我们现代的大案牍术来分析一下《长安十二时称》这部电视剧到底为什么会火,大家都对这部电视剧的评价是什么样的?(所有弹幕最高频的900个词)
二、技术方案
1、分析优酷弹幕的加载方式然后使用requests库爬取
2、抓取整部剧所有集的所有弹幕
3、重点做数据清洗,比如:剧情、人名、高能君弹幕等等
4、将弹幕做成词云
三、技术实现
1、分析并获取弹幕接口的url
①打开优酷网站,点击电视剧播放,在页面鼠标右键选择检查(或F12),调出浏览器的调试窗口。
②复制任意一条弹幕,然后点击调试窗口按Control+F进行搜索!
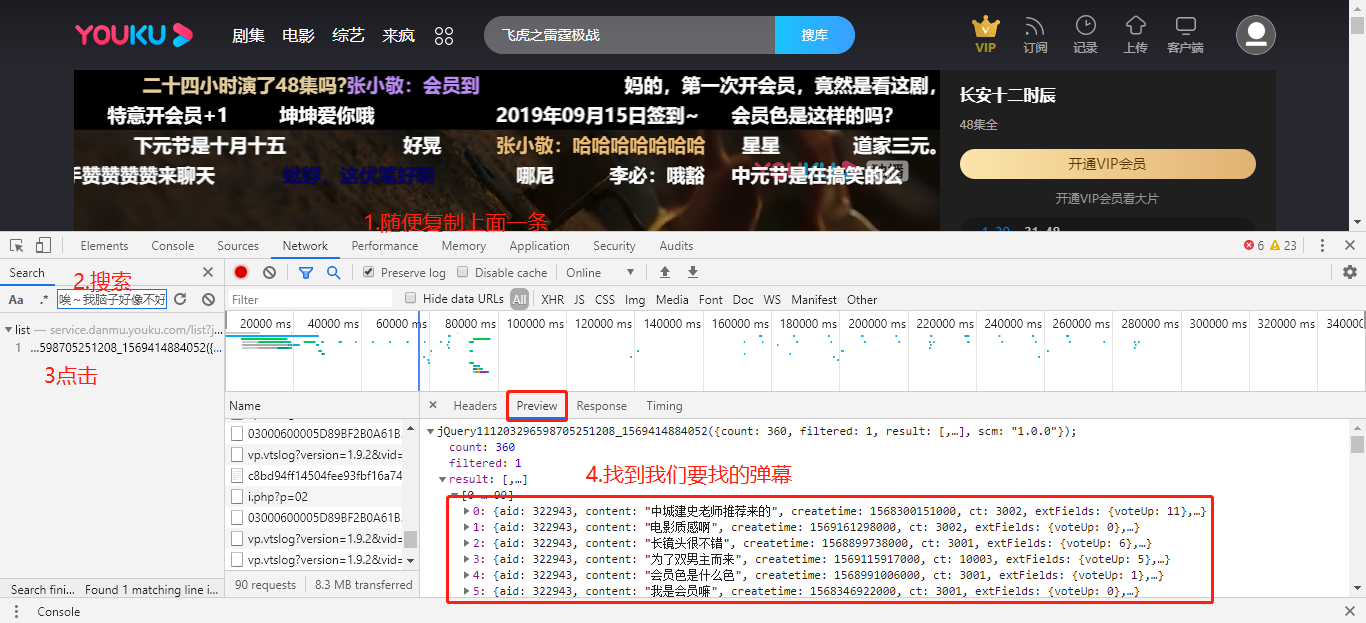
③点击该请求的Headers按钮,查看请求url,并且注意请求头中的Referer和User-Agent参数。

通过上面的步骤,我们就可以轻松加愉快的获取到弹幕加载的url
https://service.danmu.youku.com/list?jsoncallback=jQuery111208275429479734884_1569416025133&mat=0&mcount=1&ct=1001&iid=1061156738&aid=322943&cid=97&lid=0&ouid=0&_=1569416025149
2、爬取弹幕数据
URL找到之后我们便可以开始coding了,还是老规矩:先从一条数据的抓取、提取、保存,这些都没问题之后我们再研究批量抓取。
import requests def spider_danmu(): '''爬取优酷指定页的弹幕''' url = 'https://service.danmu.youku.com/list?jsoncallback=jQuery111208275429479734884_1569416025133&mat=0&mcount=1&ct=1001&iid=1061156738&aid=322943&cid=97&lid=0&ouid=0&_=1569416025149' kv = { 'Referer': 'https://v.youku.com/v_show/id_XNDI0NDYyNjk1Mg==.html?spm=a2h0k.11417342.soresults.dselectbutton&s=efbfbd78efbfbd5cefbf', 'Sec-Fetch-Mode': 'no-cors', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36' } try: r = requests.get(url, headers = kv) r.raise_for_status() print(r.text) except Exception as e: print('爬取失败') if __name__ == '__main__': spider_danmu()
3、提取数据
①提取json数据
我们观察返回的数据会发现,跨域请求用的是jsonp,所以我们需要对返回的数据进行稍微的截取,就是将jQuery111208275429479734884_1569416025133(和最后的)去掉,只保留中间的json数据。
import json import requests def spider_danmu(): '''爬取优酷指定页的弹幕''' url = 'https://service.danmu.youku.com/list?jsoncallback=jQuery111208275429479734884_1569416025133&mat=0&mcount=1&ct=1001&iid=1061156738&aid=322943&cid=97&lid=0&ouid=0&_=1569416025149' kv = { 'Referer': 'https://v.youku.com/v_show/id_XNDI0NDYyNjk1Mg==.html?spm=a2h0k.11417342.soresults.dselectbutton&s=efbfbd78efbfbd5cefbf', 'Sec-Fetch-Mode': 'no-cors', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36' } try: r = requests.get(url, headers = kv) r.raise_for_status() # 找到jsonp数据的左括号位置并加1 json_start_index = r.text.index('(') + 1 # 截取json数据字符串 r_json_str = r.text[json_start_index:-2] # 字符串转换为json对象 r_json_obj = json.loads(r_json_str) print(r_json_obj) except Exception as e: print('爬取失败') if __name__ == '__main__': spider_danmu()
②提取弹幕数据
得到json之后,我们就来分析弹幕数据在哪里,我们可以在浏览器的调试窗口的Preview里面查看

可以看到result字段里面便是弹幕数据,而且它的数据格式是一个列表,列表中是每个弹幕对象,弹幕对象中的content字段就是实际的弹幕内容,好那我们用json把他们提取并打印出来。
import json import requests def spider_danmu(): '''爬取优酷指定页的弹幕''' url = 'https://service.danmu.youku.com/list?jsoncallback=jQuery111208275429479734884_1569416025133&mat=0&mcount=1&ct=1001&iid=1061156738&aid=322943&cid=97&lid=0&ouid=0&_=1569416025149' kv = { 'Referer': 'https://v.youku.com/v_show/id_XNDI0NDYyNjk1Mg==.html?spm=a2h0k.11417342.soresults.dselectbutton&s=efbfbd78efbfbd5cefbf', 'Sec-Fetch-Mode': 'no-cors', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36' } try: r = requests.get(url, headers = kv) r.raise_for_status() # 找到jsonp数据的左括号位置并加1 json_start_index = r.text.index('(') + 1 # 截取json数据字符串 r_json_str = r.text[json_start_index:-2] # 字符串转换为json对象 r_json_obj = json.loads(r_json_str) r_json_result = r_json_obj['result'] for r_json_danmu in r_json_result: print(r_json_danmu['content']) except Exception as e: print('爬取失败')
4、存储数据
想要的数据提取出来之后,我们就可以把数据保存。数据保存我们还是使用文件来保存,原因是操作方便,满足需求。
import json import requests def spider_danmu(): '''爬取优酷指定页的弹幕''' url = 'https://service.danmu.youku.com/list?jsoncallback=jQuery111208275429479734884_1569416025133&mat=0&mcount=1&ct=1001&iid=1061156738&aid=322943&cid=97&lid=0&ouid=0&_=1569416025149' kv = { 'Referer': 'https://v.youku.com/v_show/id_XNDI0NDYyNjk1Mg==.html?spm=a2h0k.11417342.soresults.dselectbutton&s=efbfbd78efbfbd5cefbf', 'Sec-Fetch-Mode': 'no-cors', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36' } try: r = requests.get(url, headers = kv) r.raise_for_status() # 找到jsonp数据的左括号位置并加1 json_start_index = r.text.index('(') + 1 # 截取json数据字符串 r_json_str = r.text[json_start_index:-2] # 字符串转换为json对象 r_json_obj = json.loads(r_json_str) r_json_result = r_json_obj['result'] for r_json_danmu in r_json_result: with open('danmu.txt','a+', encoding='utf-8') as f: f.write(r_json_danmu['content']+' ') print(r_json_danmu) except Exception as e: print(e) if __name__ == '__main__': spider_danmu()
5、批量爬取
完成一次请求请求的爬取、提取、保存之后,我们来研究下如何批量保存数据。这里和其他批量爬取有所区别:如何爬取多集的批量数据?
这里我们把批量爬取分为两步:第一步批量爬取一集的所有弹幕;第二步爬取多集的弹幕!
第一步:爬取某一集所有弹幕
批量爬取的关键就在于找到分页参数,找分页的技巧就是:比较两个请求url的参数,看看有何不同。
https://service.danmu.youku.com/list?jsoncallback=jQuery111203042330950003598_1569417439433&mat=0&mcount=1&ct=1001&iid=1061156738&aid=322943&cid=97&lid=0&ouid=0&_=1569417439449 https://service.danmu.youku.com/list?jsoncallback=jQuery111203042330950003598_1569417439433&mat=1&mcount=1&ct=1001&iid=1061156738&aid=322943&cid=97&lid=0&ouid=0&_=1569417439457
我们比较同一集的第一次请求与第二次请求的url发现mat参数不同,而且还是依次递增的趋势,这个参数便是我们寻找的分页参数(其实mat参数表示分钟数,表示获取第几分钟的弹幕),找到分页参数后我们就可以对原方法改造,改造思路:
将原url中分页参数变为可变参数,由方法传入。然后新建一个批量爬取的方法,循环调用单次爬取方法,每次调用传入页数即可
import json import os import random import time import requests def spider_danmu(i): '''爬取优酷指定页的弹幕''' url = 'https://service.danmu.youku.com/list?jsoncallback=jQuery111208275429479734884_1569416025133&mat=%s&mcount=1&ct=1001&iid=1061156738&aid=322943&cid=97&lid=0&ouid=0&_=1569416025149'%i kv = { 'Referer': 'https://v.youku.com/v_show/id_XNDI0NDYyNjk1Mg==.html?spm=a2h0k.11417342.soresults.dselectbutton&s=efbfbd78efbfbd5cefbf', 'Sec-Fetch-Mode': 'no-cors', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36' } try: r = requests.get(url, headers = kv) r.raise_for_status() # 找到jsonp数据的左括号位置并加1 json_start_index = r.text.index('(') + 1 # 截取json数据字符串 r_json_str = r.text[json_start_index:-2] # 字符串转换为json对象 r_json_obj = json.loads(r_json_str) # 如果请求总数count = 0 则说明弹幕爬取完成 if not r_json_obj['count']: return 0 r_json_result = r_json_obj['result'] for r_json_danmu in r_json_result: with open('danmu.txt','a+', encoding='utf-8') as f: f.write(r_json_danmu['content']+' ') return 1 except Exception as e: print(e) def batch_spider_commnet(): if os.path.exists('danmu.txt'): os.remove('danmu.txt') i = 0 while spider_danmu(i): # 判断返回值,如果爬完了,则返回0, time.sleep(random.random()*5) i += 1 if __name__ == '__main__': batch_spider_commnet()
第二步:爬取多集的所有弹幕
这一步的关键在于找到代表集数的参数,我们可以同样可以使用对比的方法:比较第一集与第二集的第一个弹幕请求URL,从而找到不同参数!
我们发现第一集的iid=1061156738、第二集的iid=1061112026,但是这个iid参数并不是递增,如何找到规律?
这时候我们还是要回到网页中寻找答案,我们复制第一集的iid值1061156738到浏览器的调试窗口搜索,找到iid就是某接口的vid值。
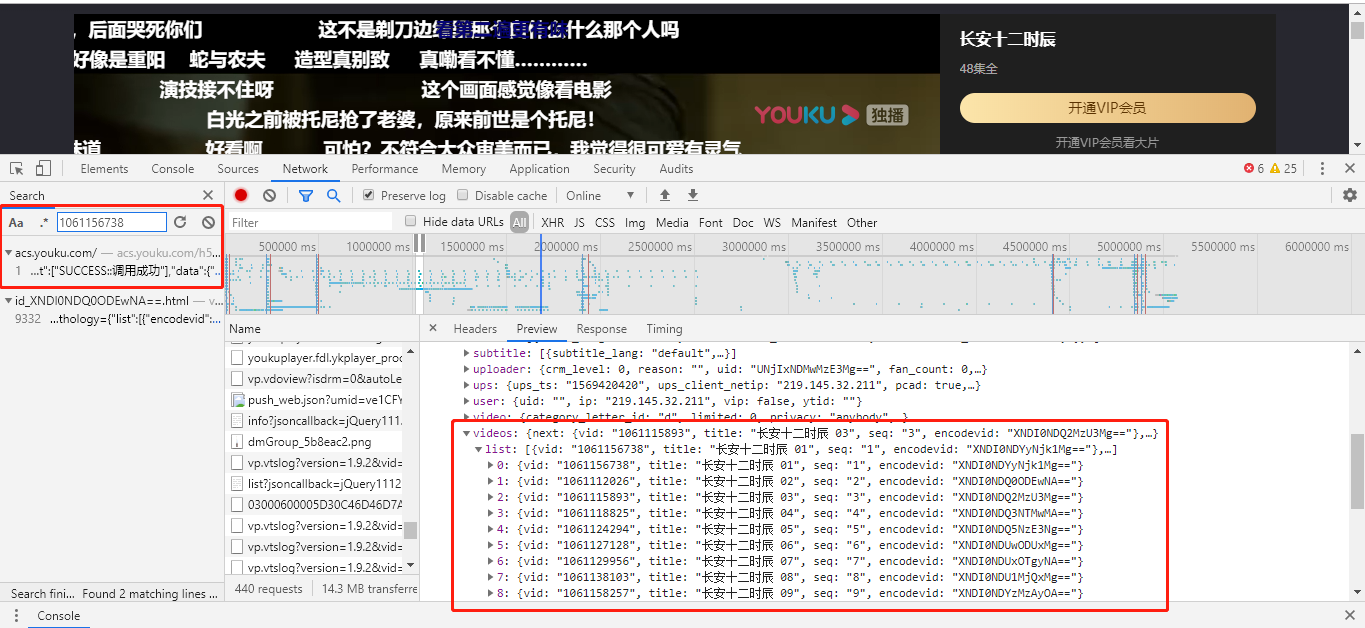
找到集数参数之后,我们就可以写一个函数将所有集数参数爬取到。
import requests def spider_jishu(): '''爬取集数''' url = 'https://acs.youku.com/h5/mtop.youku.play.ups.appinfo.get/1.1/?jsv=2.4.16&appKey=24679788&t=1569420420811&sign=20948aee5c6366f01ac4f9e920621ad3&api=mtop.youku.play.ups.appinfo.get&v=1.1&timeout=20000&YKPid=20160317PLF000211&YKLoginRequest=true&AntiFlood=true&AntiCreep=true&type=jsonp&dataType=jsonp&callback=mtopjsonp1&data=%7B%22steal_params%22%3A%22%7B%5C%22ccode%5C%22%3A%5C%220502%5C%22%2C%5C%22client_ip%5C%22%3A%5C%22192.168.1.1%5C%22%2C%5C%22utid%5C%22%3A%5C%22ve1CFYo4KygCAa%2B%2Fy0oetkRW%5C%22%2C%5C%22client_ts%5C%22%3A1569420420%2C%5C%22version%5C%22%3A%5C%221.9.2%5C%22%2C%5C%22ckey%5C%22%3A%5C%22120%23bX1bSVkn%2BmDVauQx6cTUzzU%2F%2FZoQpqQ6kmvsjBzcWpZkZ8iV6Qg3s%2FNi%2FxKz6g6rWs2FwYkKucaKY0N4gWl52SLy8Xw6dlGUq%2FMki7B%2Fnp1cvGv94wDRpK08zqV9LiBboedoZCYVN2eozwi7gMqaTpYs9IVMfCbwDEc%2FbbYt7aPyyE0ACZ6P%2B174vgvIb1G74Jii4C4Rej%2FIVsTlXHizN1Jppz3DaDcAziGiThDKE9EFi0Gif3Hv%2BnP76OP1pwmOb6MkeoxBB8WEDXyiJjzuouAMB8FugAMXAFfIh5G8AKKsp1RCpnhF55S2duN3suo8TIYlsQTGuebMSNcHTeRtxjTTrXMnlNPUcmSi1Bw5luaBp5SETdw2rySpDkNXiywgtH2NPewbWu83FCNC9oe8LB47fgYR7SXQlv38xGqMkHZ6XkdLiQ8fSLH5NhwztQ6OYmMR8vFBFAg7AaZgFADF6gfZYquxh%2FWnrE02rphGNv7kXebRKNgCUYy%2BMSeXuUOCRku8rHPJlj1%2F%2BwzdIh%2BgYFJ2swhuOVhnv%2BD3cxg6hpWGMjdkUlvc0qTwjFse6VRV0J6OohmFvaD81x%2FJoMyV1NSMJIkQFfX%2Fb5bCXufxxFPDdTDI%2FzjoNwC2BeX6s5rPStajSEkSXBM3SKoxkhFujzO4GEa103YcourXbJno6a1PmqRNVUTFNvP9qE%2FubnQHNU2dNprm%2BHWBiro%2FmPDw4nme1DxfXcc1UU2e2%2FQ9dDdmZsuCOea5EK%2BA%2Fb%3D%3D%5C%22%7D%22%2C%22biz_params%22%3A%22%7B%5C%22vid%5C%22%3A%5C%22XNDI0NDQ0ODEwNA%3D%3D%5C%22%2C%5C%22play_ability%5C%22%3A5376%2C%5C%22current_showid%5C%22%3A%5C%22322943%5C%22%2C%5C%22preferClarity%5C%22%3A3%2C%5C%22master_m3u8%5C%22%3A1%2C%5C%22media_type%5C%22%3A%5C%22standard%2Csubtitle%5C%22%2C%5C%22app_ver%5C%22%3A%5C%221.9.2%5C%22%7D%22%2C%22ad_params%22%3A%22%7B%5C%22vs%5C%22%3A%5C%221.0%5C%22%2C%5C%22pver%5C%22%3A%5C%221.9.2%5C%22%2C%5C%22sver%5C%22%3A%5C%222.0%5C%22%2C%5C%22site%5C%22%3A1%2C%5C%22aw%5C%22%3A%5C%22w%5C%22%2C%5C%22fu%5C%22%3A0%2C%5C%22d%5C%22%3A%5C%220%5C%22%2C%5C%22bt%5C%22%3A%5C%22pc%5C%22%2C%5C%22os%5C%22%3A%5C%22win%5C%22%2C%5C%22osv%5C%22%3A%5C%2210%5C%22%2C%5C%22dq%5C%22%3A%5C%22auto%5C%22%2C%5C%22atm%5C%22%3A%5C%22%5C%22%2C%5C%22partnerid%5C%22%3A%5C%22null%5C%22%2C%5C%22wintype%5C%22%3A%5C%22interior%5C%22%2C%5C%22isvert%5C%22%3A0%2C%5C%22vip%5C%22%3A0%2C%5C%22emb%5C%22%3A%5C%22AjEwNjExMTIwMjYCdi55b3VrdS5jb20CL3Zfc2hvdy9pZF9YTkRJME5EWXlOamsxTWc9PS5odG1s%5C%22%2C%5C%22p%5C%22%3A1%2C%5C%22rst%5C%22%3A%5C%22mp4%5C%22%2C%5C%22needbf%5C%22%3A2%7D%22%7D' kv = { 'Referer': 'https://v.youku.com/v_show/id_XNDI0NDYyNjk1Mg==.html?spm=a2h0k.11417342.soresults.dselectbutton&s=efbfbd78efbfbd5cefbf', 'Sec-Fetch-Mode': 'no-cors', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36' } try: r = requests.get(url, headers=kv) r.raise_for_status() print(r.text) except Exception as e: print(e) if __name__ == '__main__': spider_jishu()
执行结果:
mtopjsonp1({"api":"mtop.youku.play.ups.appinfo.get","data":{},"ret":["FAIL_SYS_TOKEN_EMPTY::令牌为空"],"v":"1.1"})
令牌为空?很奇怪,URL和headers我们都填了为什么还是不行?而浏览器却可以?
这里需要引入另一个请求头:Cookie,Cookie是干什么的?
因为HTTP协议是无状态协议,也就是说下次再请求服务器并不知道你是谁,所以就用Cookie和Seesion来记录状态,最简单的例子就是用户登录后,服务器就给浏览器遗传一串加密字符串(key),然后服务器自己缓存一个key-value,这样浏览器每次来请求都带上这个key,服务器就知道你是哪个用户!
那我们去哪里找Cookie呢?答案当然是浏览器咯!
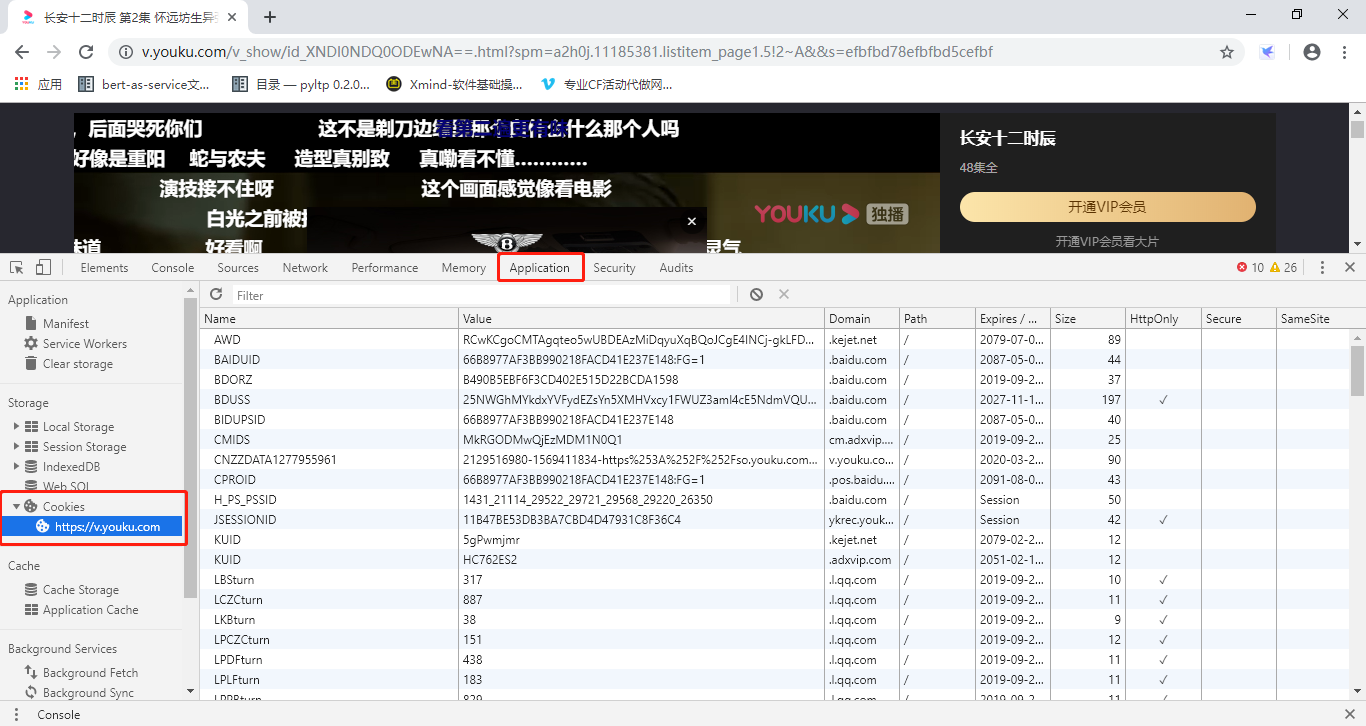
那这么多Cookie到底哪个才是我们要找的那个?这个谁也不知道,也不用找,我们直接把所有Cookie复制到代码里面就可以。
但是这种表格形式的根本无法复制,有没有什么小技巧能方便我们复制Cookie吗?当然有,我们点击浏览器调试窗口的Console按钮,然后输入document.cookie就可以看到全部Cookie啦,直接复制出来就可以,是不是很方便!
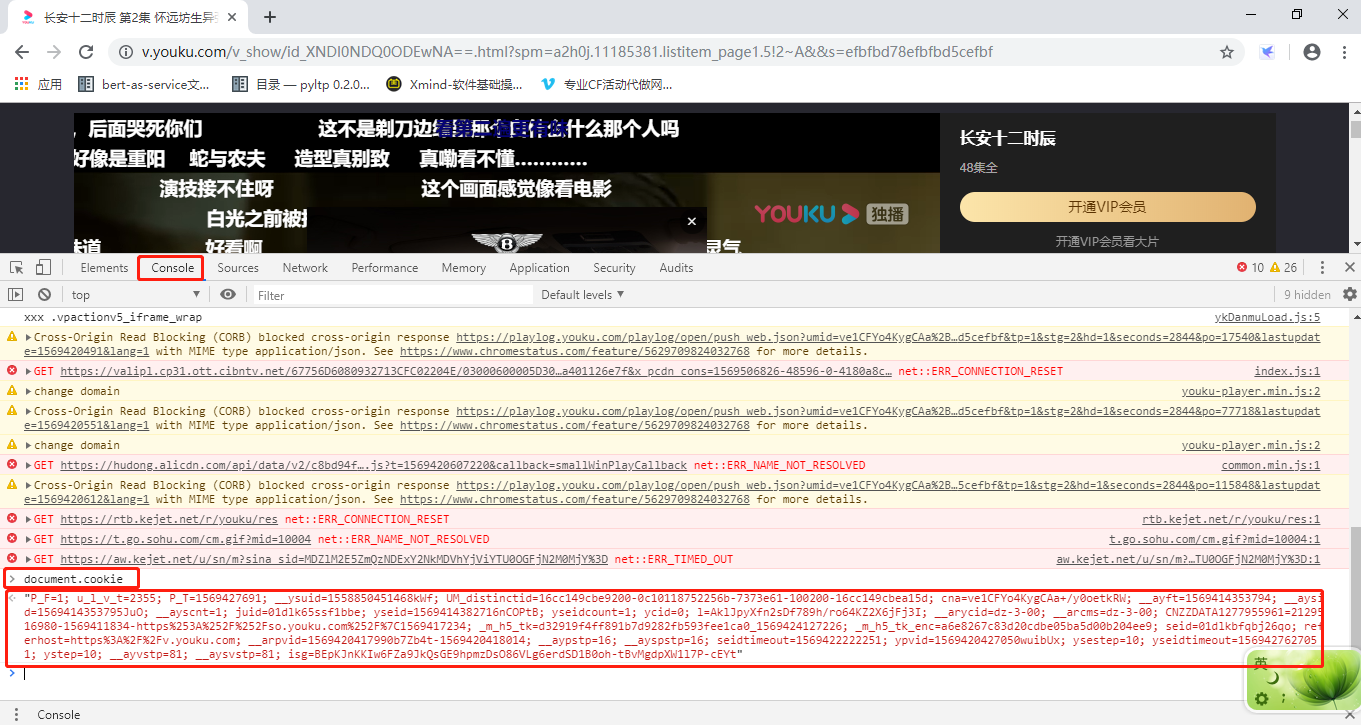
我们把Cookie复制到代码里试试吧,注意Cookie有过期时间,尤其是这个token大概十几分钟可能就会过期,过期之后在浏览器中重新复制即可!
import requests def spider_jishu(): '''爬取集数''' url = 'https://acs.youku.com/h5/mtop.youku.play.ups.appinfo.get/1.1/?jsv=2.4.16&appKey=24679788&t=1569420420811&sign=20948aee5c6366f01ac4f9e920621ad3&api=mtop.youku.play.ups.appinfo.get&v=1.1&timeout=20000&YKPid=20160317PLF000211&YKLoginRequest=true&AntiFlood=true&AntiCreep=true&type=jsonp&dataType=jsonp&callback=mtopjsonp1&data=%7B%22steal_params%22%3A%22%7B%5C%22ccode%5C%22%3A%5C%220502%5C%22%2C%5C%22client_ip%5C%22%3A%5C%22192.168.1.1%5C%22%2C%5C%22utid%5C%22%3A%5C%22ve1CFYo4KygCAa%2B%2Fy0oetkRW%5C%22%2C%5C%22client_ts%5C%22%3A1569420420%2C%5C%22version%5C%22%3A%5C%221.9.2%5C%22%2C%5C%22ckey%5C%22%3A%5C%22120%23bX1bSVkn%2BmDVauQx6cTUzzU%2F%2FZoQpqQ6kmvsjBzcWpZkZ8iV6Qg3s%2FNi%2FxKz6g6rWs2FwYkKucaKY0N4gWl52SLy8Xw6dlGUq%2FMki7B%2Fnp1cvGv94wDRpK08zqV9LiBboedoZCYVN2eozwi7gMqaTpYs9IVMfCbwDEc%2FbbYt7aPyyE0ACZ6P%2B174vgvIb1G74Jii4C4Rej%2FIVsTlXHizN1Jppz3DaDcAziGiThDKE9EFi0Gif3Hv%2BnP76OP1pwmOb6MkeoxBB8WEDXyiJjzuouAMB8FugAMXAFfIh5G8AKKsp1RCpnhF55S2duN3suo8TIYlsQTGuebMSNcHTeRtxjTTrXMnlNPUcmSi1Bw5luaBp5SETdw2rySpDkNXiywgtH2NPewbWu83FCNC9oe8LB47fgYR7SXQlv38xGqMkHZ6XkdLiQ8fSLH5NhwztQ6OYmMR8vFBFAg7AaZgFADF6gfZYquxh%2FWnrE02rphGNv7kXebRKNgCUYy%2BMSeXuUOCRku8rHPJlj1%2F%2BwzdIh%2BgYFJ2swhuOVhnv%2BD3cxg6hpWGMjdkUlvc0qTwjFse6VRV0J6OohmFvaD81x%2FJoMyV1NSMJIkQFfX%2Fb5bCXufxxFPDdTDI%2FzjoNwC2BeX6s5rPStajSEkSXBM3SKoxkhFujzO4GEa103YcourXbJno6a1PmqRNVUTFNvP9qE%2FubnQHNU2dNprm%2BHWBiro%2FmPDw4nme1DxfXcc1UU2e2%2FQ9dDdmZsuCOea5EK%2BA%2Fb%3D%3D%5C%22%7D%22%2C%22biz_params%22%3A%22%7B%5C%22vid%5C%22%3A%5C%22XNDI0NDQ0ODEwNA%3D%3D%5C%22%2C%5C%22play_ability%5C%22%3A5376%2C%5C%22current_showid%5C%22%3A%5C%22322943%5C%22%2C%5C%22preferClarity%5C%22%3A3%2C%5C%22master_m3u8%5C%22%3A1%2C%5C%22media_type%5C%22%3A%5C%22standard%2Csubtitle%5C%22%2C%5C%22app_ver%5C%22%3A%5C%221.9.2%5C%22%7D%22%2C%22ad_params%22%3A%22%7B%5C%22vs%5C%22%3A%5C%221.0%5C%22%2C%5C%22pver%5C%22%3A%5C%221.9.2%5C%22%2C%5C%22sver%5C%22%3A%5C%222.0%5C%22%2C%5C%22site%5C%22%3A1%2C%5C%22aw%5C%22%3A%5C%22w%5C%22%2C%5C%22fu%5C%22%3A0%2C%5C%22d%5C%22%3A%5C%220%5C%22%2C%5C%22bt%5C%22%3A%5C%22pc%5C%22%2C%5C%22os%5C%22%3A%5C%22win%5C%22%2C%5C%22osv%5C%22%3A%5C%2210%5C%22%2C%5C%22dq%5C%22%3A%5C%22auto%5C%22%2C%5C%22atm%5C%22%3A%5C%22%5C%22%2C%5C%22partnerid%5C%22%3A%5C%22null%5C%22%2C%5C%22wintype%5C%22%3A%5C%22interior%5C%22%2C%5C%22isvert%5C%22%3A0%2C%5C%22vip%5C%22%3A0%2C%5C%22emb%5C%22%3A%5C%22AjEwNjExMTIwMjYCdi55b3VrdS5jb20CL3Zfc2hvdy9pZF9YTkRJME5EWXlOamsxTWc9PS5odG1s%5C%22%2C%5C%22p%5C%22%3A1%2C%5C%22rst%5C%22%3A%5C%22mp4%5C%22%2C%5C%22needbf%5C%22%3A2%7D%22%7D' kv = { 'Referer': 'https://v.youku.com/v_show/id_XNDI0NDYyNjk1Mg==.html?spm=a2h0k.11417342.soresults.dselectbutton&s=efbfbd78efbfbd5cefbf', 'Sec-Fetch-Mode': 'no-cors', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36', 'Cookie': '"P_F=1; u_l_v_t=2477; P_T=1569428606; __ysuid=1558850451468kWf; UM_distinctid=16cc149cbe9200-0c10118752256b-7373e61-100200-16cc149cbea15d; cna=ve1CFYo4KygCAa+/y0oetkRW; __ayft=1569414353794; __aysid=1569414353795JuO; __ayscnt=1; juid=01dlk65ssf1bbe; yseid=1569414382716nCOPtB; yseidcount=1; ycid=0; l=AklJpyXfn2sDf789h/ro64KZ2X6jFj3I; __arycid=dz-3-00; __arcms=dz-3-00; CNZZDATA1277955961=2129516980-1569411834-https%253A%252F%252Fso.youku.com%252F%7C1569417234; _m_h5_tk=d32919f4ff891b7d9282fb593fee1ca0_1569424127226; _m_h5_tk_enc=a6e8267c83d20cdbe05ba5d00b204ee9; seid=01dlkbfqbj26qo; referhost=https%3A%2F%2Fv.youku.com; __arpvid=1569421380032DKZSGN-1569421380058; __aypstp=17; __ayspstp=17; seidtimeout=1569423184746; ypvid=1569421389178o8j8T2; ysestep=11; yseidtimeout=1569428589180; ystep=11; __ayvstp=86; __aysvstp=86; isg=BIuL34lGUtlxHY5meEB35JHSGi91IJ-i94W_wv2KR0ohHK5-hPCn8k-u9FxXO_ea"' } try: r = requests.get(url, headers=kv) r.raise_for_status() print(r.text) except Exception as e: print(e) if __name__ == '__main__': spider_jishu()

我们可以观察到返回的数据同样是个jsonp函数,同样需要提取内部的json数据,所以我们可以封装一个公用方法,用于提取jsonp返回的数据转为json对象,这样提高了复用性!
import json import requests def jsonp_func_to_json_obj(jsonp_func): """ jsonp返回函数提取json并转换为对象 :param jsonp_func: jsonp请求返回的数据,格式xxx(json) :return: json对象 """ # 找到jsonp数据的左括号位置并加1 json_start_index = jsonp_func.index("(") + 1 json_end_index = jsonp_func.index(')') # 截取json数据字符串 r_json_str = jsonp_func[json_start_index:json_end_index] return json.loads(r_json_str) def spider_jishu(): '''爬取集数''' url = 'https://acs.youku.com/h5/mtop.youku.play.ups.appinfo.get/1.1/?jsv=2.4.16&appKey=24679788&t=1569420420811&sign=20948aee5c6366f01ac4f9e920621ad3&api=mtop.youku.play.ups.appinfo.get&v=1.1&timeout=20000&YKPid=20160317PLF000211&YKLoginRequest=true&AntiFlood=true&AntiCreep=true&type=jsonp&dataType=jsonp&callback=mtopjsonp1&data=%7B%22steal_params%22%3A%22%7B%5C%22ccode%5C%22%3A%5C%220502%5C%22%2C%5C%22client_ip%5C%22%3A%5C%22192.168.1.1%5C%22%2C%5C%22utid%5C%22%3A%5C%22ve1CFYo4KygCAa%2B%2Fy0oetkRW%5C%22%2C%5C%22client_ts%5C%22%3A1569420420%2C%5C%22version%5C%22%3A%5C%221.9.2%5C%22%2C%5C%22ckey%5C%22%3A%5C%22120%23bX1bSVkn%2BmDVauQx6cTUzzU%2F%2FZoQpqQ6kmvsjBzcWpZkZ8iV6Qg3s%2FNi%2FxKz6g6rWs2FwYkKucaKY0N4gWl52SLy8Xw6dlGUq%2FMki7B%2Fnp1cvGv94wDRpK08zqV9LiBboedoZCYVN2eozwi7gMqaTpYs9IVMfCbwDEc%2FbbYt7aPyyE0ACZ6P%2B174vgvIb1G74Jii4C4Rej%2FIVsTlXHizN1Jppz3DaDcAziGiThDKE9EFi0Gif3Hv%2BnP76OP1pwmOb6MkeoxBB8WEDXyiJjzuouAMB8FugAMXAFfIh5G8AKKsp1RCpnhF55S2duN3suo8TIYlsQTGuebMSNcHTeRtxjTTrXMnlNPUcmSi1Bw5luaBp5SETdw2rySpDkNXiywgtH2NPewbWu83FCNC9oe8LB47fgYR7SXQlv38xGqMkHZ6XkdLiQ8fSLH5NhwztQ6OYmMR8vFBFAg7AaZgFADF6gfZYquxh%2FWnrE02rphGNv7kXebRKNgCUYy%2BMSeXuUOCRku8rHPJlj1%2F%2BwzdIh%2BgYFJ2swhuOVhnv%2BD3cxg6hpWGMjdkUlvc0qTwjFse6VRV0J6OohmFvaD81x%2FJoMyV1NSMJIkQFfX%2Fb5bCXufxxFPDdTDI%2FzjoNwC2BeX6s5rPStajSEkSXBM3SKoxkhFujzO4GEa103YcourXbJno6a1PmqRNVUTFNvP9qE%2FubnQHNU2dNprm%2BHWBiro%2FmPDw4nme1DxfXcc1UU2e2%2FQ9dDdmZsuCOea5EK%2BA%2Fb%3D%3D%5C%22%7D%22%2C%22biz_params%22%3A%22%7B%5C%22vid%5C%22%3A%5C%22XNDI0NDQ0ODEwNA%3D%3D%5C%22%2C%5C%22play_ability%5C%22%3A5376%2C%5C%22current_showid%5C%22%3A%5C%22322943%5C%22%2C%5C%22preferClarity%5C%22%3A3%2C%5C%22master_m3u8%5C%22%3A1%2C%5C%22media_type%5C%22%3A%5C%22standard%2Csubtitle%5C%22%2C%5C%22app_ver%5C%22%3A%5C%221.9.2%5C%22%7D%22%2C%22ad_params%22%3A%22%7B%5C%22vs%5C%22%3A%5C%221.0%5C%22%2C%5C%22pver%5C%22%3A%5C%221.9.2%5C%22%2C%5C%22sver%5C%22%3A%5C%222.0%5C%22%2C%5C%22site%5C%22%3A1%2C%5C%22aw%5C%22%3A%5C%22w%5C%22%2C%5C%22fu%5C%22%3A0%2C%5C%22d%5C%22%3A%5C%220%5C%22%2C%5C%22bt%5C%22%3A%5C%22pc%5C%22%2C%5C%22os%5C%22%3A%5C%22win%5C%22%2C%5C%22osv%5C%22%3A%5C%2210%5C%22%2C%5C%22dq%5C%22%3A%5C%22auto%5C%22%2C%5C%22atm%5C%22%3A%5C%22%5C%22%2C%5C%22partnerid%5C%22%3A%5C%22null%5C%22%2C%5C%22wintype%5C%22%3A%5C%22interior%5C%22%2C%5C%22isvert%5C%22%3A0%2C%5C%22vip%5C%22%3A0%2C%5C%22emb%5C%22%3A%5C%22AjEwNjExMTIwMjYCdi55b3VrdS5jb20CL3Zfc2hvdy9pZF9YTkRJME5EWXlOamsxTWc9PS5odG1s%5C%22%2C%5C%22p%5C%22%3A1%2C%5C%22rst%5C%22%3A%5C%22mp4%5C%22%2C%5C%22needbf%5C%22%3A2%7D%22%7D' kv = { 'Referer': 'https://v.youku.com/v_show/id_XNDI0NDYyNjk1Mg==.html?spm=a2h0k.11417342.soresults.dselectbutton&s=efbfbd78efbfbd5cefbf', 'Sec-Fetch-Mode': 'no-cors', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36', 'Cookie': '"P_F=1; u_l_v_t=2477; P_T=1569428606; __ysuid=1558850451468kWf; UM_distinctid=16cc149cbe9200-0c10118752256b-7373e61-100200-16cc149cbea15d; cna=ve1CFYo4KygCAa+/y0oetkRW; __ayft=1569414353794; __aysid=1569414353795JuO; __ayscnt=1; juid=01dlk65ssf1bbe; yseid=1569414382716nCOPtB; yseidcount=1; ycid=0; l=AklJpyXfn2sDf789h/ro64KZ2X6jFj3I; __arycid=dz-3-00; __arcms=dz-3-00; CNZZDATA1277955961=2129516980-1569411834-https%253A%252F%252Fso.youku.com%252F%7C1569417234; _m_h5_tk=d32919f4ff891b7d9282fb593fee1ca0_1569424127226; _m_h5_tk_enc=a6e8267c83d20cdbe05ba5d00b204ee9; seid=01dlkbfqbj26qo; referhost=https%3A%2F%2Fv.youku.com; __arpvid=1569421380032DKZSGN-1569421380058; __aypstp=17; __ayspstp=17; seidtimeout=1569423184746; ypvid=1569421389178o8j8T2; ysestep=11; yseidtimeout=1569428589180; ystep=11; __ayvstp=86; __aysvstp=86; isg=BIuL34lGUtlxHY5meEB35JHSGi91IJ-i94W_wv2KR0ohHK5-hPCn8k-u9FxXO_ea"' } try: r = requests.get(url, headers=kv) r.raise_for_status() # 提取json数据并转换为json对象 r_json_obj = jsonp_func_to_json_obj(r.text) # 获取电视剧简介集数 video_list = r_json_obj['data']['data']['videos']['list'] # 创建一个生成器并返回 return (video['vid'] for video in video_list) except Exception as e: print(e) if __name__ == '__main__': for i in spider_jishu(): print(i)
得到json数据之后没我们通过观察可以得到知其数据结构,然后将vid提取出来并返回.
代表集数的id拿到了,现在我们就可以双层循环去爬所有的弹幕啦,上代码。
import json import os import random import time import requests def jsonp_func_to_json_obj(jsonp_func): """ jsonp返回函数提取json并转换为对象 :param jsonp_func: jsonp请求返回的数据,格式xxx(json) :return: json对象 """ # 找到jsonp数据的左括号位置并加1 json_start_index = jsonp_func.index("(") + 1 json_end_index = jsonp_func.index(')') # 截取json数据字符串 r_json_str = jsonp_func[json_start_index:json_end_index] return json.loads(r_json_str) def spider_jishu(): '''爬取集数''' url = 'https://acs.youku.com/h5/mtop.youku.play.ups.appinfo.get/1.1/?jsv=2.4.16&appKey=24679788&t=1569420420811&sign=20948aee5c6366f01ac4f9e920621ad3&api=mtop.youku.play.ups.appinfo.get&v=1.1&timeout=20000&YKPid=20160317PLF000211&YKLoginRequest=true&AntiFlood=true&AntiCreep=true&type=jsonp&dataType=jsonp&callback=mtopjsonp1&data=%7B%22steal_params%22%3A%22%7B%5C%22ccode%5C%22%3A%5C%220502%5C%22%2C%5C%22client_ip%5C%22%3A%5C%22192.168.1.1%5C%22%2C%5C%22utid%5C%22%3A%5C%22ve1CFYo4KygCAa%2B%2Fy0oetkRW%5C%22%2C%5C%22client_ts%5C%22%3A1569420420%2C%5C%22version%5C%22%3A%5C%221.9.2%5C%22%2C%5C%22ckey%5C%22%3A%5C%22120%23bX1bSVkn%2BmDVauQx6cTUzzU%2F%2FZoQpqQ6kmvsjBzcWpZkZ8iV6Qg3s%2FNi%2FxKz6g6rWs2FwYkKucaKY0N4gWl52SLy8Xw6dlGUq%2FMki7B%2Fnp1cvGv94wDRpK08zqV9LiBboedoZCYVN2eozwi7gMqaTpYs9IVMfCbwDEc%2FbbYt7aPyyE0ACZ6P%2B174vgvIb1G74Jii4C4Rej%2FIVsTlXHizN1Jppz3DaDcAziGiThDKE9EFi0Gif3Hv%2BnP76OP1pwmOb6MkeoxBB8WEDXyiJjzuouAMB8FugAMXAFfIh5G8AKKsp1RCpnhF55S2duN3suo8TIYlsQTGuebMSNcHTeRtxjTTrXMnlNPUcmSi1Bw5luaBp5SETdw2rySpDkNXiywgtH2NPewbWu83FCNC9oe8LB47fgYR7SXQlv38xGqMkHZ6XkdLiQ8fSLH5NhwztQ6OYmMR8vFBFAg7AaZgFADF6gfZYquxh%2FWnrE02rphGNv7kXebRKNgCUYy%2BMSeXuUOCRku8rHPJlj1%2F%2BwzdIh%2BgYFJ2swhuOVhnv%2BD3cxg6hpWGMjdkUlvc0qTwjFse6VRV0J6OohmFvaD81x%2FJoMyV1NSMJIkQFfX%2Fb5bCXufxxFPDdTDI%2FzjoNwC2BeX6s5rPStajSEkSXBM3SKoxkhFujzO4GEa103YcourXbJno6a1PmqRNVUTFNvP9qE%2FubnQHNU2dNprm%2BHWBiro%2FmPDw4nme1DxfXcc1UU2e2%2FQ9dDdmZsuCOea5EK%2BA%2Fb%3D%3D%5C%22%7D%22%2C%22biz_params%22%3A%22%7B%5C%22vid%5C%22%3A%5C%22XNDI0NDQ0ODEwNA%3D%3D%5C%22%2C%5C%22play_ability%5C%22%3A5376%2C%5C%22current_showid%5C%22%3A%5C%22322943%5C%22%2C%5C%22preferClarity%5C%22%3A3%2C%5C%22master_m3u8%5C%22%3A1%2C%5C%22media_type%5C%22%3A%5C%22standard%2Csubtitle%5C%22%2C%5C%22app_ver%5C%22%3A%5C%221.9.2%5C%22%7D%22%2C%22ad_params%22%3A%22%7B%5C%22vs%5C%22%3A%5C%221.0%5C%22%2C%5C%22pver%5C%22%3A%5C%221.9.2%5C%22%2C%5C%22sver%5C%22%3A%5C%222.0%5C%22%2C%5C%22site%5C%22%3A1%2C%5C%22aw%5C%22%3A%5C%22w%5C%22%2C%5C%22fu%5C%22%3A0%2C%5C%22d%5C%22%3A%5C%220%5C%22%2C%5C%22bt%5C%22%3A%5C%22pc%5C%22%2C%5C%22os%5C%22%3A%5C%22win%5C%22%2C%5C%22osv%5C%22%3A%5C%2210%5C%22%2C%5C%22dq%5C%22%3A%5C%22auto%5C%22%2C%5C%22atm%5C%22%3A%5C%22%5C%22%2C%5C%22partnerid%5C%22%3A%5C%22null%5C%22%2C%5C%22wintype%5C%22%3A%5C%22interior%5C%22%2C%5C%22isvert%5C%22%3A0%2C%5C%22vip%5C%22%3A0%2C%5C%22emb%5C%22%3A%5C%22AjEwNjExMTIwMjYCdi55b3VrdS5jb20CL3Zfc2hvdy9pZF9YTkRJME5EWXlOamsxTWc9PS5odG1s%5C%22%2C%5C%22p%5C%22%3A1%2C%5C%22rst%5C%22%3A%5C%22mp4%5C%22%2C%5C%22needbf%5C%22%3A2%7D%22%7D' kv = { 'Referer': 'https://v.youku.com/v_show/id_XNDI0NDYyNjk1Mg==.html?spm=a2h0k.11417342.soresults.dselectbutton&s=efbfbd78efbfbd5cefbf', 'Sec-Fetch-Mode': 'no-cors', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36', 'Cookie': '"P_F=1; u_l_v_t=2477; P_T=1569428606; __ysuid=1558850451468kWf; UM_distinctid=16cc149cbe9200-0c10118752256b-7373e61-100200-16cc149cbea15d; cna=ve1CFYo4KygCAa+/y0oetkRW; __ayft=1569414353794; __aysid=1569414353795JuO; __ayscnt=1; juid=01dlk65ssf1bbe; yseid=1569414382716nCOPtB; yseidcount=1; ycid=0; l=AklJpyXfn2sDf789h/ro64KZ2X6jFj3I; __arycid=dz-3-00; __arcms=dz-3-00; CNZZDATA1277955961=2129516980-1569411834-https%253A%252F%252Fso.youku.com%252F%7C1569417234; _m_h5_tk=d32919f4ff891b7d9282fb593fee1ca0_1569424127226; _m_h5_tk_enc=a6e8267c83d20cdbe05ba5d00b204ee9; seid=01dlkbfqbj26qo; referhost=https%3A%2F%2Fv.youku.com; __arpvid=1569421380032DKZSGN-1569421380058; __aypstp=17; __ayspstp=17; seidtimeout=1569423184746; ypvid=1569421389178o8j8T2; ysestep=11; yseidtimeout=1569428589180; ystep=11; __ayvstp=86; __aysvstp=86; isg=BIuL34lGUtlxHY5meEB35JHSGi91IJ-i94W_wv2KR0ohHK5-hPCn8k-u9FxXO_ea"' } try: r = requests.get(url, headers=kv) r.raise_for_status() # 提取json数据并转换为json对象 r_json_obj = jsonp_func_to_json_obj(r.text) # 获取电视剧简介集数 video_list = r_json_obj['data']['data']['videos']['list'] # 创建一个生成器并返回 return (video['vid'] for video in video_list) except Exception as e: print(e) def spider_danmu(i,vid): '''爬取优酷弹幕''' url = 'https://service.danmu.youku.com/list?jsoncallback=jQuery111208275429479734884_1569416025133&mat=%s&mcount=1&ct=1001&iid=%s&aid=322943&cid=97&lid=0&ouid=0&_=1569416025149'%(i,vid) kv = { 'Referer': 'https://v.youku.com/v_show/id_XNDI0NDYyNjk1Mg==.html?spm=a2h0k.11417342.soresults.dselectbutton&s=efbfbd78efbfbd5cefbf', 'Sec-Fetch-Mode': 'no-cors', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36' } try: r = requests.get(url, headers=kv) r.raise_for_status() #r_json_obj = jsonp_func_to_json_obj(r.text) # 找到jsonp数据的左括号位置并加1 json_start_index = r.text.index('(') + 1 # 截取json数据字符串 r_json_str = r.text[json_start_index:-2] # 字符串转换为json对象 r_json_obj = json.loads(r_json_str) # 如果请求总数count = 0 则说明弹幕爬取完成 if not r_json_obj['count']: return 0 r_json_result = r_json_obj['result'] for r_json_danmu in r_json_result: with open('danmu.txt','a+', encoding='utf-8') as f: f.write(r_json_danmu['content']+' ') return 1 except Exception as e: print(e) def batch_spider_commnet(): if os.path.exists('danmu.txt'): os.remove('danmu.txt') # 爬取所有集数的vid vids = spider_jishu() for vid in vids: print(vid) i = 0 while spider_danmu(i, vid): # 判断返回值,如果爬完了,则返回0, time.sleep(random.random()*5) i += 1 print('爬取完毕') if __name__ == '__main__': batch_spider_commnet()
一共爬取了近30万条的数据,大概用了40分钟,中间空挡去斗地主赢了一万金币哈哈哈,然如果你觉得时间间隔太长也可缩短,但是建议不要太频繁,不然对人家服务器或者被监控到就不好。
6、数据清洗+生成词云
我们要清洗什么数据?其实这个事先很难猜到,所以我们不做数据清洗直接生成云词看看会是什么效果,然后再做调整。
import jieba import numpy as np from PIL import Image from wordcloud import WordCloud from matplotlib import pyplot as plt def cut_word(): with open('danmu.txt', 'r', encoding='utf-8') as f: comment_txt = f.read() wordlist = jieba.cut(comment_txt, cut_all=False) wl = " ".join(wordlist) print(wl) return wl def create_word_cloud(): # 设置词云形状 wc_mask = np.array(Image.open('bige.jpg')) # 设置词云的一些配置,如字体,背景色,词云形状,大小 wc = WordCloud(background_color='white', max_words=2000, width=940, height=2000,max_font_size=50, random_state=42, font_path='C:WindowsFontsmsyhbd.ttc') # 生成词云 wc.generate(cut_word()) # 在只设置mask情况下,会得到一个拥有图片形状的词云 plt.imshow(wc, interpolation='bilinear') plt.axis('off') plt.figure() plt.show() if __name__ == '__main__': create_word_cloud(

我们看到像:哈哈、不是、这个、什么,会员等这些词比较多,这种单词没有太大的分析价值,所以我们数据清洗便有了方向。(ps:某酷的弹幕没啥内涵。。。)
import jieba import numpy as np from PIL import Image from wordcloud import WordCloud from matplotlib import pyplot as plt def cut_word(): with open('danmu.txt', 'r', encoding='utf-8') as f: comment_txt = f.read() wordlist = jieba.cut(comment_txt, cut_all=False) wl = " ".join(wordlist) print(wl) return wl def create_word_cloud(): stop_words = ['哈哈','哈哈哈','哈哈哈哈','会员', '什么', '为什么','不是','就是','还是','真是','这是','是不是','应该','不能','这个', '电视','电视剧','怎么', '这么','那么','没有','不能','不知','知道', '这样', '还有'] # 设置词云形状 wc_mask = np.array(Image.open('bige.jpg')) # 设置词云的一些配置,如字体,背景色,词云形状,大小 wc = WordCloud(background_color='white', max_words=900, mask=wc_mask, width=940, height=400,scale=10,max_font_size=50, random_state=42, stopwords=stop_words,font_path='C:WindowsFontsmsyhbd.ttc') # 生成词云 wc.generate(cut_word()) # 在只设置mask情况下,会得到一个拥有图片形状的词云 plt.imshow(wc, interpolation='bilinear') plt.axis('off') plt.figure() plt.show() if __name__ == '__main__': create_word_cloud()

7.分析词云图
从上面的词云图中我们可以分析出:
-
此电视剧中的一些主角:张小敬、李必、崔器、龙波、徐斌、竟然还有人喜欢曹破延。
-
有人说好看,有人说看不懂,说明剧情可能有点深度
-
画风可能有点像刺客信条
-
四字弟弟、千玺,说明剧中有易烊千玺
-
片尾曲可能有惊喜
-
大唐、长安说明了故事背景
-
弹幕、智商,可能大家在提醒你:关弹幕,保智商!