python实现进程的三种方式及其区别
在python中有三种方式用于实现进程
多进程中, 每个进程中所有数据( 包括全局变量) 都各有拥有⼀份, 互不影响
1.fork()方法
ret = os.fork()
if ret == 0:
#子进程
else:
#父进程
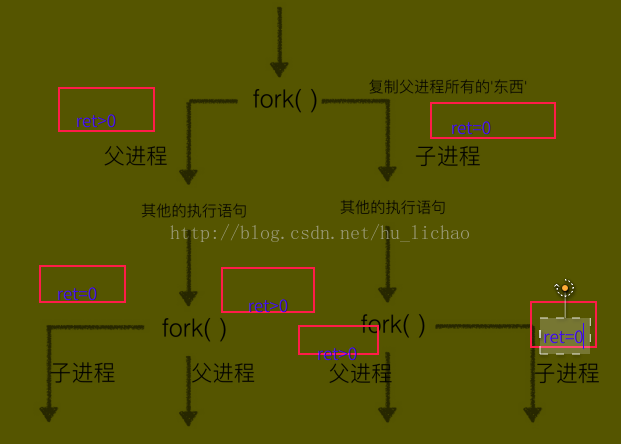
这是python中实现进程最底层的方法,其他两种从根本上也是利用fork()方法来实现的,下面是fork()方法的原理示意图
getpid()、getppid()方法
import os
rpid = os.fork()
if rpid<0:
print("fork调⽤失败。 ")
elif rpid == 0:
print("我是⼦进程( %s) , 我的⽗进程是(%s) "%(os.getpid(),os.getppid()))
x+=1
else:
print("我是⽗进程( %s) , 我的⼦进程是( %s) "%(os.getpid(),rpid))
print("⽗⼦进程都可以执⾏这⾥的代码")我是⽗进程( 19360) , 我的⼦进程是( 19361)
⽗⼦进程都可以执⾏这⾥的代码
我是⼦进程( 19361) , 我的⽗进程是( 19360)
⽗⼦进程都可以执⾏这⾥的代码注意:
(1)其中os.fork()的返回值ret在第一行执行后,会开辟另外一个子进程,然后父进程跟子进程同时从此句往下执行,对于子进程来说,ret值是0,对于父进程来说ret值是一个大于0的值,这个值实际上就是新开子进程的pid.
(2)此种开辟进程的方式不会发生堵塞,也就是父进程结束并不会影响子进程的继续执行。实际上是根据操作系统的调度算法来实现的,父子进程相互不影响。
多进程修改全局变量
#coding=utf-8
import os
import time
num = 0
# 注意, fork函数, 只在Unix/Linux/Mac上运⾏, windows不可以
pid = os.fork()
if pid == 0:
num+=1
print('哈哈1---num=%d'%num)
else:
time.sleep(1)
num+=1
print('哈哈2---num=%d'%num)运行结果
哈哈1---num=1
哈哈2---num=1
#多进程不共享全局变量多次fork()问题
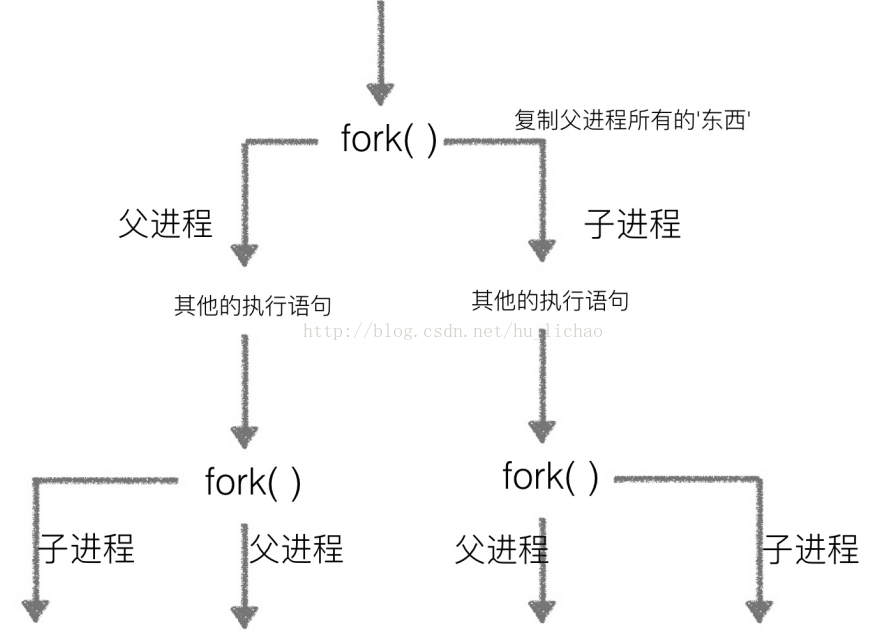
结论:多次fork()会有多个进程生成,生成规则同上。
2,Process方法
python是跨平台的,所以自然肯定会为我们提供实现多进程的库,毕竟在win里面用不了fork()。此方法需要导入对应模块
from multiprocessing import Process
p1=Process(target=xxxx)
p1.start()这个方法常用场景是使用少量进程做主动服务,如qq客户端,等这样的可以开多个。
还可以继承Process模块并实现run方法来调用,此时xxxx方法等价于run方法执行的内容,在重写过run方法后,在执行子类实例对象的start方法时,会自动调用实现的run方法,这个跟java里面也是类似的。
注意,此种方法子进程不结束,父进程也会堵塞,也就是等子进程都结束后,父进程才会结束,通常应用于进程间的同步。
代码实现演示
#coding=utf-8
from multiprocessing import Process
import os
# ⼦进程要执⾏的代码
def run_proc(name):
print('⼦进程运⾏中, name= %s ,pid=%d...' % (name, os.getpid()))
if __name__=='__main__':
print('⽗进程 %d.' % os.getpid())
p = Process(target=run_proc, args=('test',))
print('⼦进程将要执⾏')
p.start()
p.join()
print('⼦进程已结束')运行结果
⽗进程 4857.
⼦进程将要执⾏
⼦进程运⾏中, name= test ,pid=4858...
⼦进程已结束Process类常⽤⽅法:
is_alive(): 判断进程实例是否还在执⾏;
join([timeout]): 是否等待进程实例执⾏结束, 或等待多少秒;
start(): 启动进程实例( 创建⼦进程) ;
run(): 如果没有给定target参数, 对这个对象调⽤start()⽅法时, 就将执⾏对象中的run()⽅法;
terminate(): 不管任务是否完成, ⽴即终⽌;
is_alive(): 判断进程实例是否还在执⾏;
join([timeout]): 是否等待进程实例执⾏结束, 或等待多少秒;
start(): 启动进程实例( 创建⼦进程) ;
run(): 如果没有给定target参数, 对这个对象调⽤start()⽅法时, 就将执⾏对象中的run()⽅法;
terminate(): 不管任务是否完成, ⽴即终⽌;
3,利用进程池Pool
当需要创建的⼦进程数量不多时, 可以直接利⽤multiprocessing中的Process动态成⽣多个进程, 但如果是上百甚⾄上千个⽬标, ⼿动的去创建进程的⼯作量巨⼤, 此时就可以⽤到multiprocessing模块提供的Pool⽅法。此方法也需导入对应模块
from multiprocessing import Pool
pool=Pool(3)
pool.apply_async(xxxx)xxxx表示要在进程中运行的代码块或方法、函数
此方法可以用来做服务器端的响应,往往主进程比较少,而Pool()中的参数值,也就是进程池的大小,真正的任务都在子进程中执行。
使用示例
from multiprocessing import Pool
import os,time,random
def worker(msg):
t_start = time.time()
print("%s开始执⾏,进程号为%d"%(msg,os.getpid()))
#random.random()随机⽣成0~1之间的浮点数
time.sleep(random.random()*2)
t_stop = time.time()
print(msg,"执⾏完毕, 耗时%0.2f"%(t_stop-t_start))
po=Pool(3) #定义⼀个进程池, 最⼤进程数3
for i in range(0,10):
#Pool.apply_async(要调⽤的⽬标,(传递给⽬标的参数元祖,))
#每次循环将会⽤空闲出来的⼦进程去调⽤⽬标
po.apply_async(worker,(i,))
print("----start----")
po.close() #关闭进程池, 关闭后po不再接收新的请求
po.join() #等待po中所有⼦进程执⾏完成, 必须放在close语句之后
print("-----end-----")----start----
----start----
0开始执⾏,进程号为5025
----start----
1开始执⾏,进程号为5026
----start----
----start----
----start----
----start----
----start----
----start----
----start----
2开始执⾏,进程号为5027
0 执⾏完毕, 耗时0.58
3开始执⾏,进程号为5025
1 执⾏完毕, 耗时0.70
4开始执⾏,进程号为5026
2 执⾏完毕, 耗时1.36
5开始执⾏,进程号为5027
3 执⾏完毕, 耗时1.03
6开始执⾏,进程号为5025
4 执⾏完毕, 耗时1.12
7开始执⾏,进程号为5026
5 执⾏完毕, 耗时1.25
8开始执⾏,进程号为5027
7 执⾏完毕, 耗时1.28
9开始执⾏,进程号为5026
6 执⾏完毕, 耗时1.91
8 执⾏完毕, 耗时1.23
9 执⾏完毕, 耗时1.38
-----end-----上面使用的是非堵塞方法,如果使用aply(),则是堵塞方法
from multiprocessing import Pool
import os,time,random
def worker(msg):
t_start = time.time()
print("%s开始执⾏,进程号为%d"%(msg,os.getpid()))
#random.random()随机⽣成0~1之间的浮点数
time.sleep(random.random()*2)
t_stop = time.time()
print(msg,"执⾏完毕, 耗时%0.2f"%(t_stop-t_start))
po=Pool(3) #定义⼀个进程池, 最⼤进程数3
for i in range(0,10):
po.apply(worker,(i,))
print("----start----")
po.close() #关闭进程池, 关闭后po不再接收新的请求
po.join() #等待po中所有⼦进程执⾏完成, 必须放在close语句之后
print("-----end-----")0开始执⾏,进程号为5280
0 执⾏完毕, 耗时0.91
1开始执⾏,进程号为5281
1 执⾏完毕, 耗时1.59
2开始执⾏,进程号为5282
2 执⾏完毕, 耗时1.25
3开始执⾏,进程号为5280
3 执⾏完毕, 耗时0.53
4开始执⾏,进程号为5281
4 执⾏完毕, 耗时1.49
5开始执⾏,进程号为5282
5 执⾏完毕, 耗时0.18
6开始执⾏,进程号为5280
6 执⾏完毕, 耗时1.51
7开始执⾏,进程号为5281
7 执⾏完毕, 耗时0.88
8开始执⾏,进程号为5282
8 执⾏完毕, 耗时1.08
9开始执⾏,进程号为5280
9 执⾏完毕, 耗时0.12
----start----
-----end-----multiprocessing.Pool常⽤函数解析:
apply_async(func[, args[, kwds]]) : 使⽤⾮阻塞⽅式调⽤func( 并⾏执⾏, 堵塞⽅式必须等待上⼀个进程退出才能执⾏下⼀个进程) , args为传递给func的参数列表, kwds为传递给func的关键字参数列表;
apply_async(func[, args[, kwds]]) : 使⽤⾮阻塞⽅式调⽤func( 并⾏执⾏, 堵塞⽅式必须等待上⼀个进程退出才能执⾏下⼀个进程) , args为传递给func的参数列表, kwds为传递给func的关键字参数列表;
apply(func[, args[, kwds]]): 使⽤阻塞⽅式调⽤funcclose(): 关闭Pool, 使其不再接受新的任务;
terminate(): 不管任务是否完成, ⽴即终⽌;
join(): 主进程阻塞, 等待⼦进程的退出, 必须在close或terminate之后使⽤;