一 正则表达式
在线测试工具 http://tool.chinaz.com/regex/
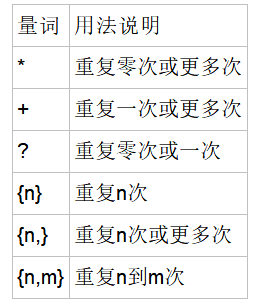
字符
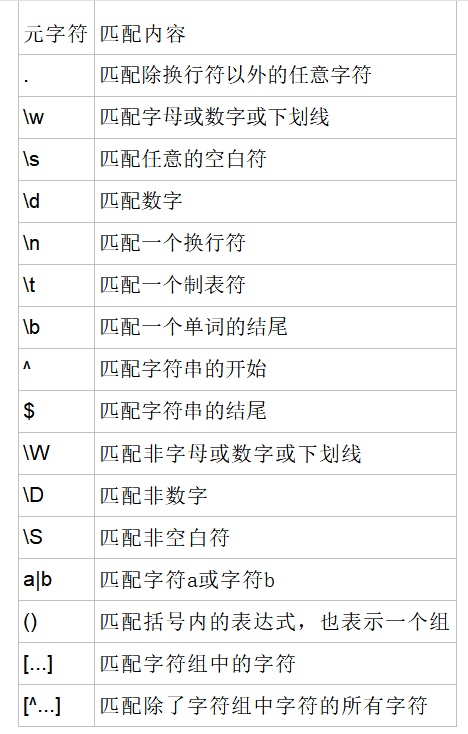
量词
贪婪匹配
贪婪匹配:在满足匹配时,匹配尽可能长的字符串,默认情况下,采用贪婪匹配,<.*>
加上?为将贪婪匹配模式转为非贪婪匹配模式,会匹配尽量短的字符串<.*?>
几个常用的非贪婪匹配Pattern
*? 重复任意次,但尽可能少重复
+? 重复1次或更多次,但尽可能少重复
?? 重复0次或1次,但尽可能少重复
{n,m}? 重复n到m次,但尽可能少重复
{n,}? 重复n次以上,但尽可能少重复
.*?的用法. 是任意字符* 是取 0 至 无限长度
? 是非贪婪模式。 合在一起就是 取尽量少的任意字符,一般不会这么单独写,他大多用在: .*? 就是取前面任意长度的字符,直到一个x出现
二 re模块
1 findall search match split sub subn等方法
1 import re 2 3 ret = re.findall('a','abc egon yuan') # 返回所有满足匹配条件的结果,放在列表里 4 print(ret) ##结果['a', 'a'] 5 6 7 ret1 = re.search('d+','8787abc 97897engo yuan657').group()#函数会在字符串内查找模式匹配,只到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以 8 # 通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None。 9 print(ret1) ##结果 8787 只匹配第一个数字 10 11 12 ret3=re.match('d+','1abc78797 97897engo yuan657').group()# 同search,不过只能在字符串开始处进行匹配 13 print(ret3) 14 # #ret4=re.match('a','bca').group() ##这种的就会报错 15 # # print(ret4) 16 17 ret5=re.split('[ab]','abcd')#先按'a'分割得到''和'bcd',在对''和'bcd'分别按'b'分割 18 print(ret5) ##结果['', '', 'cd'] 19 20 ret6 = re.sub('d', 'H', 'eva3egon4yuan4', 1)##将数字替换成'H',参数1表示只替换1个 21 print(ret6) 22 23 ret7 = re.subn('d', 'H', 'eva3egon4yuan4')#将数字替换成'H',返回元组(替换的结果,替换了多少次) 24 print(ret7) 25 26 obj = re.compile('d{3}') #将正则表达式编译成为一个 正则表达式对象,规则要匹配的是3个数字 27 28 ret8 = obj.search('abc123eeee') #正则表达式对象调用search,参数为待匹配的字符串 29 print(ret8.group()) 30 31 ret = re.finditer('d', 'ds3sy4784a') 32 print(ret) 33 print(ret.__next__().group()) 34 print(next(ret).group()) 35 36 #第二种取值方式 37 print([i.group()for i in ret])
二 findall和split优先级
1 ##findall优先级 2 ret = re.findall('www.(oldboy|baidu).com', 'www.oldboy.com') 3 ##这是因为findall会优先把匹配结果组里内容返回,如果想要匹配结果取消优先级 4 print(ret)##结果是oldboy 5 6 ret = re.findall('www.(?:baidu|oldboy).com', 'www.oldboy.com') 7 print(ret) # ['www.oldboy.com'] 8 9 ##split优先级查询 10 ret = re.split("d+",'eva3egon4yuan') 11 print(ret) 12 13 ret = re.split('(d+)','eva3egon4yuan') 14 print(ret) 15 16 ##在匹配部分加上()之后所切出的结果是不同的, 17 #没有()的没有保留所匹配的项,但是有()的却能够保留了匹配的项, 18 #这个在某些需要保留匹配部分的使用过程是非常重要的