不多说直接上代码
首先需要安装需要的库,安装命令如下
pip install BeautifulSoup
pip install requests
pip install urllib
pip install lxmlfrom bs4 import BeautifulSoup # 贵族名宠网页爬虫
import requests import urllib.request # 网址 url = 'http://www.hengdadog.com/sale-1.html' def allpage(): # 获得所有网页 all_url = [] for i in range(1, 8): #循环翻页次数 each_url = url.replace(url[-6], str(i)) # 替换 all_url.append(each_url) return (all_url) # 返回地址列表 if __name__ == '__main__': img_url = allpage() # 调用函数 for url in img_url: # 获得网页源代码 print(url) requ = requests.get(url) req = requ.text.encode(requ.encoding).decode() html = BeautifulSoup(req, 'lxml') t = 0 # 选择目标url img_urls = html.find_all('img') for k in img_urls: img = k.get('src') # 图片 print(img) name = str(k.get('alt')) # 名字,这里的强制类型转换很重要 type(name) # 先本地新建一下文件夹,保存图片并且命名 path = 'F:\CAT\' # 路径 file_name = path + name + '.jpg' imgs = requests.get(img) # 存储入文件 try: urllib.request.urlretrieve(img, file_name) # 打开图片地址,下载图片保存在本
except: print("error")
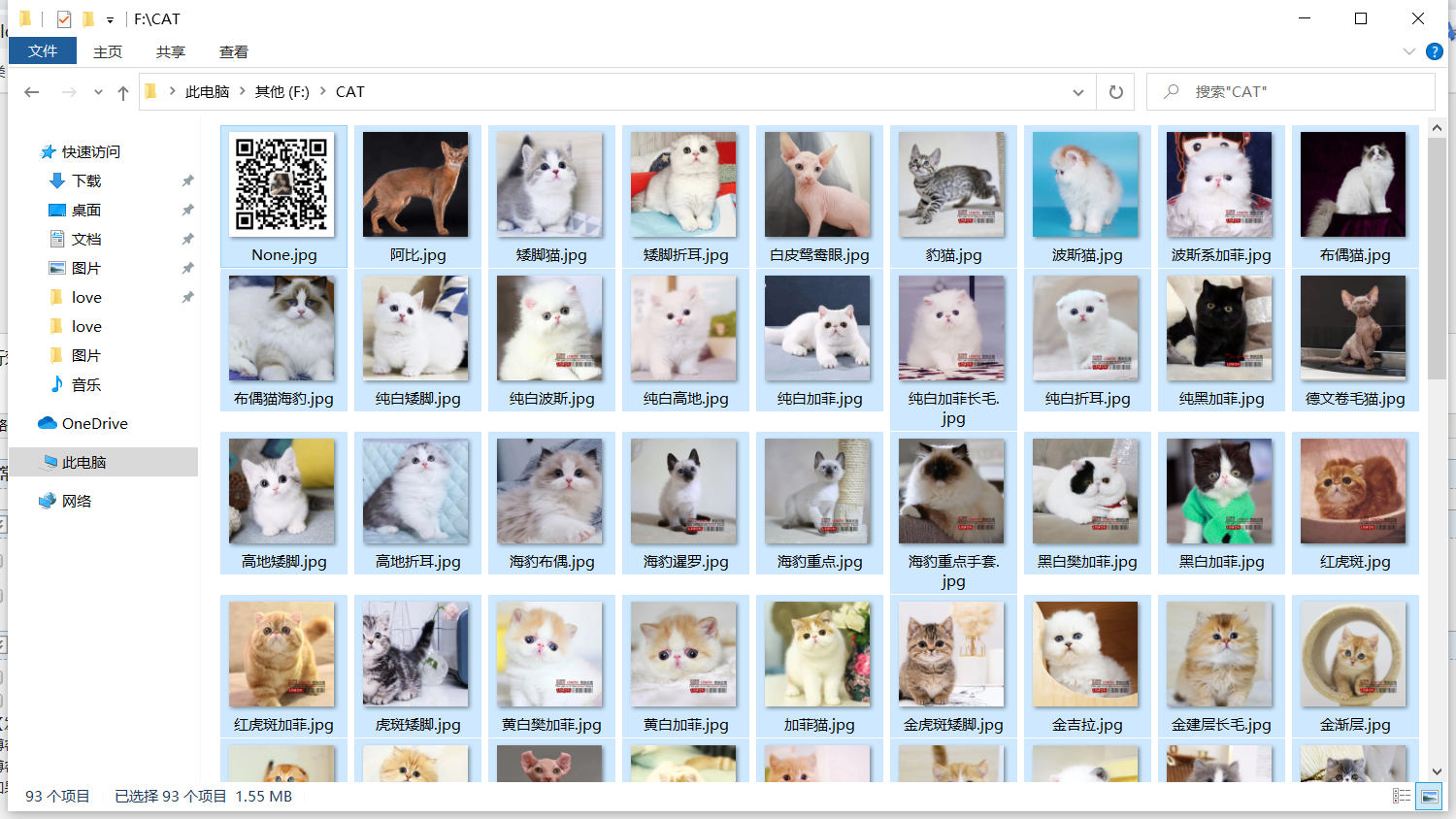
运行效果:
上面代码有不少缺陷,比如需要手动创建目录以及判断目录是否存在,下载没有提示,于是做了些优化:
from bs4 import BeautifulSoup # 贵族名宠网页爬虫 import requests import urllib.request import os # 网址 url = 'http://www.hengdadog.com/sale-1.html' if os.path.exists('F:\CAT'):#判断目录是否存在,存在则跳过,不存在则创建 pass else: os.mkdir('F:\CAT') def allpage(): # 获得所有网页 all_url = [] for i in range(1, 10): #循环翻页次数 each_url = url.replace(url[-6], str(i)) # 替换 all_url.append(each_url) return (all_url) # 返回地址列表 if __name__ == '__main__': img_url = allpage() # 调用函数 for url in img_url: # 获得网页源代码 print(url) requ = requests.get(url) req = requ.text.encode(requ.encoding).decode() html = BeautifulSoup(req, 'lxml') t = 0 # 选择目标url img_urls = html.find_all('img') for k in img_urls: img = k.get('src') # 图片 print(img) name = str(k.get('alt')) # 名字,这里的强制类型转换很重要 type(name) # 保存图片并且命名 path = 'F:\CAT\' # 路径 file_name = path + name + '.jpg' imgs = requests.get(img) # 存储入文件 try: urllib.request.urlretrieve(img, file_name) # 打开图片地址,下载图片保存在本地, print('正在下载图片到F:CAT目录······') except: print("error")
打包成EXE文件:
进入文件目录输入如下命令
pyinstaller -F get_cat.py