Kafka utils包最后一篇~~~
十五、ShutdownableThread.scala
可关闭的线程抽象类! 继承自Thread同时还接收一个boolean变量isInterruptible表明是否允许中断。既然是可关闭的,因此一定不是守护线程,而是一个用户线程(不会阻塞JVM关闭)。提供的方法有:
1. doWork: 抽象方法。子类必须实现这个方法,从名字来说应该是指定线程要完成的操作。
2. initiateShutdown: 发起关闭请求。首先通过CAS的方式判断是否线程在运行中;如果是的话将表明运行状态的isRunning变量设置为false,同时根据该线程的可中断性(通过isInterruptible)调用Thread.interupt方法中断该线程并返回true。
3. awaitShutdown: 用于发起关闭请求(initiateShutdown)之后调用该方法等待关闭操作完全结束。实现方式是调用CountDownLatch的await方法等待shutdownLacth对象变为0——shutdownLatch是该类维护的一个关闭阀门。在运行线程结束之后程序会将该对象减为0。
4. run方法: 复写了Thread的run方法。该类维护的isRunning类似于一个状态标志,控制着线程何时退出执行操作的循环。每次循环前检测isRunning值,如果一旦发现是false,则退出执行并将shutdownLatch阀门至于关闭状态;如果是true,则调用doWork来执行真正的操作。
十六、Throttle.scala
主要目的是限制某些操作的执行速度,其实主要用于清理日志时限制IO速度。这个类会接收一个给定的期望速率(单位是**/每秒,这里的**其实不重要,可以是字节或个数,主要是限制速率)。构造函数参数如下:
1. desiredRatePerSec: 期望速率
2. checkIntervalMs: 检查间隔,单位ms
3. throttleDown: 是否需要往下调节速度,即降低速率
4. metricName: 待调节项名称
5. units: 待调节项单位,默认是字节
6. time: 时间字段
该类还实现了KafkaMetricsGroup trait,你可以认为后者就是构造度量元对象用的(例如通过newMeter)。Throttle类只有一个方法: maybeThrottle。该方法代码写了一大堆,一句一句分析太枯燥,我直接举个例子说吧: 假设我们要限制IO速率,单位是字节/秒,每100毫秒查一次。我们想要限制速率为10字节/毫秒。现在我们在500ms内检测到一共发送了6000字节,那么实际速率是6000/500 = 12字节/毫秒,比期望速率要高,因此我们要限制IO速率,此时怎么办呢?很简单,如果是按照期望速率,应该花费6000/10 = 600ms,比实际多花了100ms,因此程序sleep 100ms把那段多花的时间浪费掉就起到了限制速率的效果。简单来说程序就是这么实现的: )
十七、Time.scala
封装了一些与时间相关的常量,另外提供了很多抽象方法供子类实现,比如milliseconds、nanoseconds和sleep。最后真的提供了一个子类实现了Time trait并实现了前面的三个方法。
十八、ToolsUtils.scala
使用jopt-simple工具库验证命令行参数提供的host/port格式是否正确,validatePortOrDie方法对接收到的host: port字符串进行split,过滤掉那些不符合host: port格式的项得到一个Array[String],如果这个数组的个数与split出来的Array长度不匹配,说明有不合格项,直接打印调用方法并结束程序。
okay! 我们快接近胜利了!不过一想到kafka.uitls包中还有3个超长的源代码文件就脑袋疼。我们还是一个一个啃吧。
十九、Utils.scala
按照这个文件中注释提示的那样,这个文件里面的帮助函数都是最最常用的函数,并不限定为Kafka的逻辑服务。因此如果要在这个文件中添加一个函数,一定要确保这个函数有很完善的文档另外还要保证一定不能只在某个特定的领域使用,应该适用于最常见的场景中。
okay,反正是一个个独立的function,还是老规矩,一个一个说:
1. runnable: 接收一个无返回值的函数封装到一个新建的Java Runnable对象中返回。
2. daemonThread: 创建一个守护线程用于后台执行。注意,只是创建,不开启该线程。一共提供了3个方法,目的都是一样
3. newThread: 创建新的线程,参数决定线程名称、执行操作以及是否为守护线程
4. readBytes: 读取一段给定的ByteBuffer以及给定位移到一个字节数组
5. loadProps: 加载一个给定路径下的.properties文件到一个Properties对象中
6. openChannel: 根据可变性打开一个文件通道(file channel),如果可以修改,以RandomAccessFile方法打开,如果不可修改,以FileInputStream方法打开
7. swallow: 执行给定的操作(以函数参数方式传递), 记录下任何异常但绝不抛出异常,而是吞掉异常
8. equal: 比较两段ByteBuffer——先比较position,然后是remaining,最后是内部的每个字节
9. readString: 将ByteBuffer中的内容读出来生成一个字符串
10. croak: 打印错误消息并关闭JVM
11. rm: 递归地删除文件或子目录
12. registerMBean: 将给定的mbean注册到平台mbean服务器。如果已经注册过会先卸载该mbean再重新注册。该方法不会抛出任何异常,只是简单滴返回false表示注册失败
13. unregisterMBean: 取消mbean的注册。如果没有注册过,就什么都不做
14. readUnsignedInt: 一共有2个方法,一个是从ByteBuffer当前位置读取4个字节的integer,并更新位移;另一个是从给定位置读取4个字节的integer,但并不修改position信息
15. writeUnsignedInt: 也是提供了2个方法: 一个是将一个long型作为一个4个字节的integer写入ByteBuffer,不考虑溢出的问题;第二个方法就是在给定的位置做第一个方法的事情
16. crc32: 计算字节数组的CRC32校验码
17. hashcode: 计算给定参数项的hashCode
18. groupby: 按照给定的函数计算出来的key进行分组,将相同key的值都放入一个List[V]中,整体作为一个HashMap返回。不过貌似这个函数没有被用到: (
19. read: 读取给定ReadableByteChannel的buffer到一个ByteBuffer,如果读取失败抛出EOFException异常,否则返回读取的字节数
20. notNull: 带泛型类型的方法,如果给定值是null抛出异常,否则直接返回该值
21. stackTrace: 获取给定异常类的栈追踪信息(stack trace),作为字符串返回
22. parseCsvMap: 接收一个逗号分隔的key/value对,类似于key1: value1,key2: value2,... 使用正则表达式解析成一个HashMap并返回。该方法还有个形式,是返回成一个字符串序列,即字符串数组
23. createObject: 通过反射机制为给定类名表示的类创建一个实例
24. nullOrEmpty: 判断给定字符串是否为空。但实现有个问题,如果是多个空格,该方法就会返回false
25. loopIterator: 其实就是个无限遍历的迭代器,为传入的集合生成一个无限流Stream,并返回它的迭代器
26. readFileAsString: 读取文件内容并作为一个字符串返回
27. abs: 计算某个整数的绝对值。如果是最小整数返回0——与Java的实现不同
28. replaceSuffix: 替换字符串的后缀,如果无法找到要替换的后缀直接抛出异常
29. createFile: 根据给定路径创建文件
30. asString: 将一个Properties对象转换成字符串返回
31. readProps: 从给定的字符串中读取属性并返回一个Properties
32. readInt: 从字节数组中的指定位移处读取一个integer
33. inLock: 在加锁的情况下执行一段函数
34. inReadLock/inWriterLock: 使用给定的锁分别获取一个读锁和写锁,然后执行函数体
35. JSONEscapeString: 将字符串中的某些字符进行转义,比如转成\b
36. duplicates: 返回列表中重复项
二十、VerifiableProperties.scala
这个类就是封装了Properties对象,同时维护了一个HashSet表示属性名称集合。具体的方法有:
1. containsKey: 判断是否包含某个key
2. getProperty: 将属性名加入到属性名称集合,然后从props中获取某个属性值之后返回
3. getString: 先检测是否包含这个属性,如果包含则调用getProperty返回属性值
4. getInt: 获取一个integer类型的属性值
5. getIntInRange: 返回一个integer类型的属性值,但该值必须在给定的范围内
6. getShort: 返回一个short类型的属性值
7. getShortInRange: 返回一个short类型的属性值,但该值必须在 给定的范围内
8. getLong: 返回一个long类型的属性值
9. getLongInRange: 返回一个long类型的属性值,但该值必须在给定的范围内
10. getDouble: 返回一个double类型的属性值
11. getBoolean: 返回一个boolean类型的属性值
12. getMap: 从一个属性列表中解析出一个Map[String, String]并返回
13. getCompressionCodec: 从属性列表中读取处codec信息。该方法同时支持解析codec的序号和名称,并返回对应的codec
14. verify: 主要就是验证Properties对象中每个属性是否都在属性名称集合中,即使不在也只是打印一个log而已
二十一、ZkUtils.scala
终于到包里面的最后一个文件了。这个文件代码很长,定义了三个class和两个object。先从简单的开始说吧:
1. ZKConfig class: 这个类定义了zookeeper配置信息,其构造函数接收一个VerifiableProperties对象。Kafka维护的zookeeper配置信息包括:一个CSV格式的zookeeper连接串、最大会话超时时间、连接最大超时时间以及一个zookeeper follower被允许落后于leader的最大时间间隔,默认是2秒
2. ZKGroupDirs class: 名字中的group是指kafka的消费组的,因为Kafka中的consumer都属于一个consumer group。在这个类中定义了3个方法分别返回消费者的根路径,消费者组的路径以及消费者组的id的路径
3. ZKGroupTopicDirs class: 该类继承了ZKGroupDirs类,并提供了2个新的方法用于计算消费者组的位移和拥有者信息。如下图所示:

ZKUtils.scala中还定义了一个ZKStringSerializer object用于序列化/反序列化zookeeper中保存的字节数组。提供的两个方法也很直观:serialize方法将字符串转化成字节数组;deserialize方法将字节数组转换成字符串。
好了, 就差最后一个object没说了。ZkUtils object首先定义了很多常量,都是Kafka不同组件使用的Zookeeper上路径,比如Consumer的根路径是/consumers等。值得注意的是,目前kafka还不支持我们定制这些路径的值。这个object定义了很多方法,虽然很直观,但还是值得我们简单地浏览一遍:
1. getTopicPath: 获取topic的zk路径
2. getTopicPartitionsPath: 获取topic分区的zk路径
3. getTopicConfigPath: 获取topic config的zk路径。这个路径是在0.8.1引入的,主要是在创建或修改topic分区赋值时会更新该路径下的zk信息
4. getDeleteTopicPath: 获取已删除topic的zk路径
5. readDataMaybeNull: 返回给定/controller路径下的(controller名,状态)元组,如果无法找到那个zk节点直接返回(None,空Stat)
6. getController: 调用readDataMaybeNull方法获取controller名称,如果为空直接抛出异常,否则返回一个integer类型的controller id(通过调用KafkaController.parseControllerId方法)
7. getTopicPartitionPath: 返回/brokers/topics/<my-topic>/partitions/<my-partition-id>这样形式的zk路径
8. getTopicPartitionLeaderAndIsrPath: 返回/brokers/topics/<my-topic>/partitions/<my-partition-id>/state这样形式的zk节点
9. getChildren: 返回给定path路径下的所有子路径名
10. getSortedBrokerList: 为/borkers/ids下所有broker按照broker id排序之后做成一个列表返回
11. getChildrenParentMayNotExist: 获取给定path的所有子目录名,如果path代表的节点不存在返回Nil
12. getBrokerInfo: 读取/brokers/ids/<给定broker id>节点的数据,如果存在则调用Broker.createBroker创建一个broker实例返回,否则返回None
13. getAllBrokerInCluster: 获取/brokers/ids下的broker列表并排序,遍历该列表顺序地为每个非None的broker创建一个Broker对象,最后封装到一个Seq中返回
14. getLeaderAndIsrForPartition: 为指定的topic及其partition查询出leader node和所有isr以及epoch信息,然后提取出leader和isr信息封装为一个LeaderAndIsr对象返回——LeaderAndIsr是个case class封装了leader信息及其isr列表信息
15. makeSurePersistentPathExists: 确保给定的路径在zookeeper中存在,如果不存在创建该path
16. setupCommandPaths: 调用makeSurePersistentPathExists确保类开头定义的所有路径都已经存在
17. getLeaderForPartition: 获取某个topic的某个partition的leader id。例如在下图中,该方法应该返回0
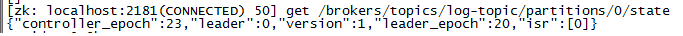

18. getEpochForPartition: 读取某个topic某个分区下的epoch信息。如果还是上图的话应该返回leader_epoch的值,即20
19. getInSyncReplicasForPartition: 读取某个topic某个分区下的所有isr列表,如果还是上图的话,应该返回isr的值,也是0——笔者的Kafka是个单节点的集群,因此并不能看出太大的区别
20. getReplicasForPartition: 读取某个topic某个分区下的一组副本,如果是下图的话topic名称是log-topic,分区号是0的话,应该返回[0]——如果是生产环境应该是一组已分配的副本


21. registerBrokerInZk: 为给定的broker id在zookeeper上创建一个临时节点
22. getConsumerPartitionOwnerPath: 返回诸如/consumers/console-consumer-33497/owners/log-topic/partitionId这样形式的zk路径
23. leaderAndIsrZkData: 将给定的LeaderAndIsr对象和epoch编码为json格式的字符串
24. replicaAssignmentZkData: 将一组replica编码成json格式的字符串: "version" : 1, "partitions":{...}
25. createParentPath: 创建父路径代表的持久化节点
26. createEphemeralPath: 根据给定数据和路径创建临时节点
27. createEphemeralPathExpectConflict: 顾名思义,创建一个临时节点,如果已经存在抛出异常
28. createEphemeralPathExpectConflictHandleZKBug: 更加严谨的一个方法用于创建zk临时节点——主要是处理了Zookeeper会话超时的bug
29. createPersistentPath: 级联创建一个持久化节点
30. createSequentialPersistentPath: 创建一个顺序持久节点(persistent sequential)
31. updatePersistentPath: 更新一个持久节点的值。必要时候创建其父路径,但不会抛出节点已存在的异常
32. conditionalUpdatePersistentPath: 如果给定的path和version都没有问题的话更新节点数据,返回(true, 新版本),否则返回(false, -1)。另外如果捕获了失去连接的异常(比如:ConnectionLossException),zkClient会自动地重试,但有可能上一次更新操作已经成功,因此更新过的版本号与期望版本号不再匹配从而导致该方法失败,因此该方法需要处理这种情况的发生,具体做法就是再提供一个optional函数做进一步的检查
33. conditionalUpdatePersistentPathIfExists: 也是先判断条件然后再决定是否进行更新操作。成功的话返回(true,新版本),否则返回(false, -1)。另外如果path不存在直接抛出异常结束
34. updateEphemeralPath: 更新一个持久化节点的值,必要的时候创建其父路径,但不会抛出NodeExistsException
35. deletePath: 删除给定的path节点,返回true表示成功;如果节点不存在,直接返回false
36. deletePathRecursive: 已递归方式删除给定的path
37. maybeDeletePath: 根据给定的zookeeper客户端连接串创建一个zk client连接,设置会话超时和连接超时都是30秒,然后递归地删除给定的path,之后关闭zkClient对象。如果出现任何异常都不做任何处理,直接吞掉
38. readData: 读取path节点的数据,返回(数据,状态信息)元组
39. pathExists: 检查给定的path是否存在
40. getCluster: 遍历/brokers/ids下面的所有broker,创建Broker对象之后加入到一个Cluster对象实例(Cluster保存的是当前所有可用的broker),然后返回cluster
41. getPartitionLeaderAndIsrForTopics: 给定一组TopicAndPartition对象(TopicAndPartition就是一个topic加上一个分区信息),为每一个查询出对应与这个topic这个分区的LeaderIsrAndControllerEpoch并封装到一个HashMap中返回——简单来说就是就是获取某个topic某个分区的leader信息、isr信息、leaderEpoch信息以及controllerEpoch信息
42. getReplicaAssignmentForTopics: 获取一组topic的所有分区对应的副本broker号
43. getPartitionAssignmentForTopics: 返回HashMap[topic名称, Map[该topic下每一个分区号,一组副本]]这样形式的map
44. getPartitionsForTopics: 返回Map[topic名称,该topic下一组partition]这样形式的map
45. getPartitionsBeingReassigned: 读取所有topic及其分区对应的所有新的副本列表
46. parsePartitionReassignmentDataWithoutDedup: 根据给定的json字符串创建一个元组序列,每个元组都是(TopicAndPartition, Seq[Int])格式的,指定了某个topic的某个分区对应的replica号。其实就是给定一个json字符串,里面指定了哪些replica号是属于哪个topic的哪个partition的,然后提取出来做了一个Seq保存。该方法还有一个变体就是返回一个Map,总之就是保存的数据结构不同罢了
47. parseTopicsData: 从给定的json字符串中提取出topic信息封装到一个List中返回
48. getPartitionReassignmentZkData: 生成{"version" : 1, "partitions" : {"topic" -> ***, "partition" -> ***, "replicas" : {**, **}}}这样形式的json字符串
49. updatePartitionReassignmentData: 调用getPartitionReassignmentZkData方法生成json字符串,然后调用updatePersistentPath方法更新zookeeper
50. getPartitionsUndergoingPreferredReplicaElection: 读取/admin/preferred_replica_election下的所有信息,返回一组TopicAndPartition
51. deletePartition: 删除/brokers/ids/brokerId的节点,并删除/borkers/topics/brokerId的节点
52. getConsumersInGroup: 获取/consumers/group/ids下所有节点名称
53. getConsumersPerTopic: 获取每个topic的所有consumser
54. getBrokerInfo: 根据broker id获取Broker信息
55. getAllTopics: 获取所有的topic封装到一个Seq中
56. getAllPartitions: 获取所有topic的所有partition,扁平化到一个Set中,每个都是TopicAndPartition对象