欢迎来到深入学习Kubernetes API Server的系列文章的第二部分。在上一部分中我们对APIserver总体,相关术语及request请求流进行探讨说明。在本部分文章中,我们主要聚焦于探究如何对Kubernetes 对象的状态以一种可靠,持久的方式进行管理。之前的文章中提到过 API Server自身是无状态的,并且它是唯一能够与分布式存储etcd直接通信的组件。
etcd的简要说明
在*nix操作系统中,我们一般使用/etc来存储相关配置数据。实际上etcd的名字就是由此发展而来,在etc后面加上个”d”表示”distributed”分布式。任何分布式系统都需要有像etcd这样能够存储系统数据的东西,使其能够以一致和可靠的方式检索相关数据。为了能实现分布式的数据访问,etcd使用Raft 协议。从概念上讲,etcd支持的数据模型是键值(key-value)存储。在etcd2中,各个key是以层次结构存在,而在etcd3中这个就变成了遍布模型,但同时也保持了层次结构方式的兼容性。
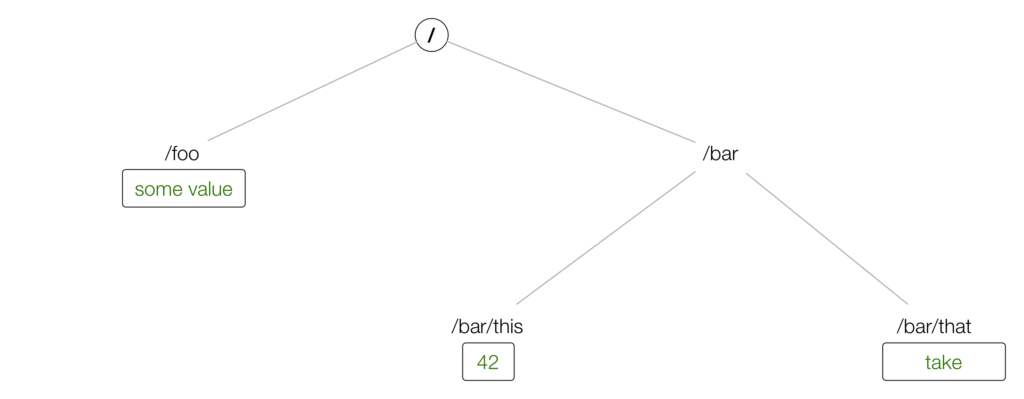
使用容器化版本的etcd,我们可以创建上面的树,然后按如下方式检索它:
$ docker run --rm -d -p 2379:2379
--name test-etcd3 quay.io/coreos/etcd:v3.1.0 /usr/local/bin/etcd
--advertise-client-urls http://0.0.0.0:2379 --listen-client-urls http://0.0.0.0:2379
$ curl localhost:2379/v2/keys/foo -XPUT -d value="some value"
$ curl localhost:2379/v2/keys/bar/this -XPUT -d value=42
$ curl localhost:2379/v2/keys/bar/that -XPUT -d value=take
$ http localhost:2379/v2/keys/?recursive=true
HTTP/1.1 200 OK
Content-Length: 327
Content-Type: application/json
Date: Tue, 06 Jun 2017 12:28:28 GMT
X-Etcd-Cluster-Id: 10e5e39849dab251
X-Etcd-Index: 6
X-Raft-Index: 7
X-Raft-Term: 2
{
"action": "get",
"node": {
"dir": true,
"nodes": [
{
"createdIndex": 4,
"key": "/foo",
"modifiedIndex": 4,
"value": "some value"
},
{
"createdIndex": 5,
"dir": true,
"key": "/bar",
"modifiedIndex": 5,
"nodes": [
{
"createdIndex": 5,
"key": "/bar/this",
"modifiedIndex": 5,
"value": "42"
},
{
"createdIndex": 6,
"key": "/bar/that",
"modifiedIndex": 6,
"value": "take"
}
]
}
]
}
}
现在我们已经大致了解了etcd是如何工作的,接下去我们继续讨论etcd在Kubernetes是如何被使用的。
集群中的etcd
在Kubernetes中,etcd是控制平面中的一耳光独立组成部分。在Kubernetes1.5.2版本之前,我们使用的是etcd2版本,而在Kubernetes1.5.2版本之后我们就转向使用etcd3版本了。值得注意的是在Kubernetes1.5.x版本中etcd依旧使用的是v2的API模型,之后这将开始变为v3的API模型,包括使用的数据模型。站在开发者角度而言这个似乎没什么直接影响,因为API Server与存储之前是抽象交互,而并不关心后端存储的实现是etcd v2还是v3。但是如果是站在集群管理员的角度来看,还是需要知道etcd使用的是哪个版本,因为集群管理员需要日常对数据进行一些备份,恢复的维护操作。
你可以API Server的相关启动项中配置使用etcd的方式,API Server的etcd相关启动项参数如下所示:
$ kube-apiserver -h
...
--etcd-cafile string SSL Certificate Authority file used to secure etcd communication.
--etcd-certfile string SSL certification file used to secure etcd communication.
--etcd-keyfile string SSL key file used to secure etcd communication.
...
--etcd-quorum-read If true, enable quorum read.
--etcd-servers List of etcd servers to connect with (scheme://ip:port) …
...
Kubernetes 存储在etcd中的数据,是以JSON字符串或Protocol Buffers 格式存储。下面我们来看一个具体的例子:在apiserver-sandbox的命名空间中创建一个webserver的pod。然后我们使用 etcdctl工具来查看相关etcd(在本环节中etcd版本为3.1.0)数据。
$ cat pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: webserver
spec:
containers:
- name: nginx
image: tomaskral/nonroot-nginx
ports:
- containerPort: 80
$ kubectl create -f pod.yaml
$ etcdctl ls /
/kubernetes.io
/openshift.io
$ etcdctl get /kubernetes.io/pods/apiserver-sandbox/webserver
{
"kind": "Pod",
"apiVersion": "v1",
"metadata": {
"name": "webserver",
...
下面我们来看一下这个pod对象是如何最终存储到etcd中,通过kubectl create -f pod.yaml的方式。下图描绘了这个总体流程:
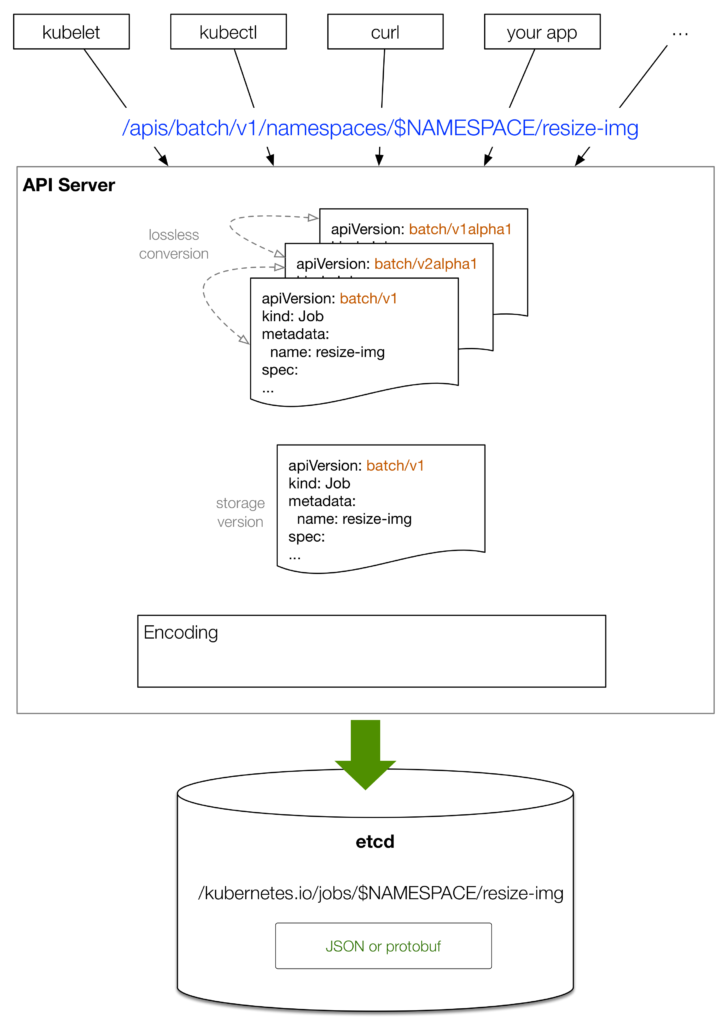
- 客户端(比如kubectl)提供一个理想状态的对象,比如以YAML格式,v1版本提供。
- Kubectl将YAML转换为JSON格式,并发送。
- 对应同类型对象的不同版本,API Server执行无损耗转换。对于老版本中不存在的字段则存储在annotations中。
- API Server将接受到的对象转换为规范存储版本,这个版本由API Server指定,一般是最新的稳定版本,比如v1。
- 最后将对象通过JSON 或protobuf方式解析为一个value,通过一个特定的key存入etcd当中。
我们可以通过配置 kube-apiserver的启动参数--storage-media-type来决定想要序列化数据存入etcd的格式,默认情况下为application/vnd.kubernetes.protobuf格式。我们也可以通过配置--storage-versions启动参数,来确定存入etcd的每个群组Group对象的默认版本号。
现在让我们来看看无损转换是如何进行的,我们将使用Kubernetes 对象Horizontal Pod Autoscaling (HPA)来列举说明。HPA顾名思义是指通过监控资源的使用情况结合ReplicationController控制Pod的伸缩。
首先我们期待一个API代理(以便于我们能够在本地直接访问它),并启动ReplicationController,以及HPA 。
$ kubectl proxy --port=8080 &
$ kubectl create -f https://raw.githubusercontent.com/mhausenblas/kbe/master/specs/rcs/rc.yaml
kubectl autoscale rc rcex --min=2 --max=5 --cpu-percent=80
kubectl get hpa/rcex -o yaml
现在,你能够使用httpie ——当然你也能够使用curl的方式——向API server 请求获取HPA对象使用当前的稳定版本(autoscaling/v1),或者使用之前的版本(extensions/v1beta1),获取的两个版本的区别如下所示:
$ http localhost:8080/apis/extensions/v1beta1/namespaces/api-server-deepdive/horizontalpodautoscalers/rcex > hpa-v1beta1.json
$ http localhost:8080/apis/autoscaling/v1/namespaces/api-server-deepdive/horizontalpodautoscalers/rcex > hpa-v1.json
$ diff -u hpa-v1beta1.json hpa-v1.json
{
"kind": "HorizontalPodAutoscaler",
- "apiVersion": "extensions/v1beta1",
+ "apiVersion": "autoscaling/v1",
"metadata": {
"name": "rcex",
"namespace": "api-server-deepdive",
- "selfLink": "/apis/extensions/v1beta1/namespaces/api-server-deepdive/horizontalpodautoscalers/rcex",
+ "selfLink": "/apis/autoscaling/v1/namespaces/api-server-deepdive/horizontalpodautoscalers/rcex",
"uid": "ad7efe42-50ed-11e7-9882-5254009543f6",
"resourceVersion": "267762",
"creationTimestamp": "2017-06-14T10:39:00Z"
},
"spec": {
- "scaleRef": {
+ "scaleTargetRef": {
"kind": "ReplicationController",
"name": "rcex",
- "apiVersion": "v1",
- "subresource": "scale"
+ "apiVersion": "v1"
},
"minReplicas": 2,
"maxReplicas": 5,
- "cpuUtilization": {
- "targetPercentage": 80
- }
+ "targetCPUUtilizationPercentage": 80
我们能够看到HorizontalPodAutoscale的版本从v1beta1变为了v1。API server能够在不同的版本之前无损耗转换,不论在etcd中实际存的是哪个版本。
在了解整个存储流程之后,我们下面来探究一下API server如何将数据进行编码,解码存入etcd中以JSON 或protobuf的方式,同时也考虑到etcd的版本。
API Server将所有已知的Kubernetes对象类型保存在名为Scheme的Go类型注册表(registry)中。在此注册表中,定义每种了Kubernetes对象的类型以及如何转换它们,如何创建新对象,以及如何将对象编码和解码为JSON或protobuf。

当API Server从客户端接收到一个对象时,比如kubectl,通过HTTP路径,能够知道这个对象的具体版本号。首先会为这个对象使用对应的版本Scheme创建一个空对象,然后通过JSON或protobuf将HTTP传过来的对象内容进行解码转换。解码完成后创建对象,存入etcd中。
在API中可能会有很多版本,如果要支持每个版本之间的直接转换,这样往往处理起来比较麻烦。比如某个API下面有三个版本,那么它就要支持一个版本到另两个版本的直接转换(比如v1 ⇔ v1alpha1, v1 ⇔ v1beta1, v1beta1 ⇔ v1alpha1)。为了避免这个问题,在API server中有一个特别的 “internal” 版本。当两个版本之间需要转换时,先转换为internal版本,再转换为相应转换的版本。这样的话,每个版本只要支持能够转换为internal版本,那么就能够与其它任何版本进行间接的转换。所以一个对象先转换为internal版本,然后在转换为稳定的v1版本,然后在存入etcd中。
v1beta1 ⇒ internal ⇒ v1
在转换的第一步中,如果某些字段用户没有赋值指定,那么这些会被赋为一个默认值。比如在v1beta1 中肯定没有在v1版本新增的一个字段。在这种情况下,用户肯定无法在v1beta1 版本为这个字段赋值。这时候,在转换的第一步中,我们会为这个字段赋一个默认值以生成一个有效的internal。
校验及准入
在转换过程中有两个重要的步骤,如下图所示:
v1beta1 ⇒ internal ⇒ | ⇒ | ⇒ v1 ⇒ json/yaml ⇒ etcd
admission validation
准入和校验是创建和更新对象存入etcd之前必须通过的步骤。它们的一些规则如下所示:
- 准入(Admission):查看集群中的一些约束条件是否允许创建或更新此对象,并根据此集群的相关配置为对象设置一些默认值。在Kubernetes有很多这种约束条件,下面列举一些例子:
NamespaceLifecycle:如果命名空间不存在,则拒绝该命名空间下的所有传入请求。
LimitRanger:强制限制命名空间中资源的使用率。
ServiceAccount:为pod创建 service account 。
DefaultStorageClass:如果用户没有为PersistentVolumeClaims赋值,那么将它设置为一个默认值。
ResourceQuota:对群集上的当前用户强制执行配额约束,如果配额不足,可能会拒绝请求。
- 校验(Validation):检查传入对象(在创建和更新期间)是否格式是否合法以及相关值是否有效。比如:
- 检查必填字段是否已填。
- 检查字符串格式是否正确(比如只允许小写形式)。
- 是否有些字段存在冲突(比如,有两个容器的名字一样)。
校验(Validation)并不关心其它类型的对象实例,换言之,它只关心每个对象的静态检查,无关集群配置。
准入(Admission)可以用flag --admission-control=<plugins>来启动或禁用。它们中的大多数可以有集群管理配置。此外,在Kubernetes 1.7中可以用webhook机制来扩展准入机制,使用控制器来实现对对象的传统的校验。
迁移存储对象
关于存储对象迁移的最后说明:当Kubernetes需要升级到新的版本时,根据每个版本的相关文档步骤备份相关集群的数据是至关重要的。这一方面是由于etcd2到etcd3的转变,另一方面是由于Kubernetes 对象的Kind及version的不断发展。
在etcd中,每个对象是首选存储版本(preferred storage version)存在的。但是,随着时间的推移,etcd存储中的对象可能以一个非常老的版本存在。如果在将来某个时间这个对象版本被废弃了,那么将无法再解码它的protobuf 或JSON。因此,在集群升级之前需要重写,迁移这些数据。下面这些资料能够对version切换提供一些帮助:
请参阅集群管理文档升级API版本部分。Upgrading to a different API version
下一次,在深入学习Kubernetes APIServer的第三部分中,我们将讨论如何使用Custom Resource Definitions扩展和自定义API资源。https://www.huaweicloud.com/product/cce.html