当我们训练好一模型之后,如何判断模型的好坏呢,这就需要用到评价指标(evaluation metrics)。下面介绍一下在二分类任务中的一些评价指标。
| 真实-Positive(正方形左侧) | 真实-Negative(正方形右侧) | |
|---|---|---|
| 预测-Positive(圆形内) | TP(True Positive) | FP(False Positve) |
| 预测-Negative(圆形外) | FN(False Negative) | TN(True Negative) |
准确率(accuracy)
准确率的计算公式是:
[accuracy = frac{TP+TN}{总样本数}
]
即类别预测正确的样本在总样本数据的占比。
精确率(precision)与召回率(recall)
精确率与召回率往往一起使用的,将两者结合的指标就是F1-score。
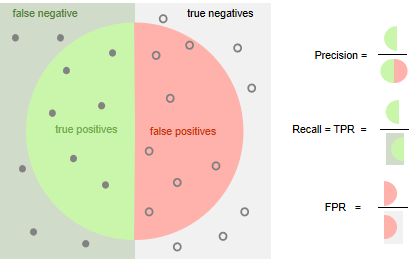
如果提高阀值,精确率会不断提高,对就上图理解的话,可以理解成圆形变小并向左移动了。
如果缩小阀值,召回率会不断提高,对就上图理解的话,可以理解成圆形变大并向右移动了。
[Precision = frac{TP}{TP+FP} \
Recall = frac{TP}{FN+TP}
]
Precision vs Accuracy
precision与accuracy的区别可以这样理解,如果是在多分类的任务中,accuracy只有一个,就是类别使用正确的样本数量在总体样本的占比;而precision在每一个类别上是单独计算的,如果要合成一个指标只能取各个类别的平均值。
另外一个例子是:假如一个测试集有正样本1个,负样本99个。我们设计的模型是个无脑模型,即把所有的样本都预测为负样本,那这个模型的accuracy是99%而precision是0%。当然如果正样本99,负样本1,全部预测为正样本,那两者都是99%。可以看出precision更侧重正样本,而accuracy并无侧重。
ROC曲线与AUC
TRP的解释是,在所有正例中有多少正例被预测对了;
FPR的解释是,在所有负例中有多少负例被预测错了;
[TRP = frac{TP}{FN+TP} \
FPR = frac{FP}{TN+FP}
]
ROC曲线的计算步骤:
- 对所有测试样例进行预测
- 将有有样例按得分从大到小排序
- 从上到下分别取阀值并计算TRP和FPR
- 将所有TRP和FPR点画到坐标上
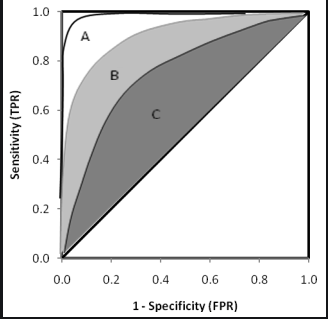
如果一条ROC曲线完全包含另一个ROC曲线,则说明前者的性能比后者好;那如果两条ROC曲线是交叉的该如何比较这两者呢?比较合理的判断依据是ROC曲线的面积,即AUC(Area Under ROC Curve)。
AUC的计算方式在这里就不详述了,在不同的机器学习相关的包都有相应API提供。