转自:http://blog.csdn.net/notbaron/article/details/48143409
1. 存储层次结构
由于两个不谋而合的因素如下:
l 硬件:由于不同存储技术的访问时间相差很大。速度较快的技术每个字节的成本要比速度较慢的技术高,而且容量小。CPU和主存之间的速度差距在增大
l 软件:一个编写良好的程序倾向于展示出良好的局部性。
聪明的人类想出了一种组织存储器系统的方法,叫做 存储器层次结构。
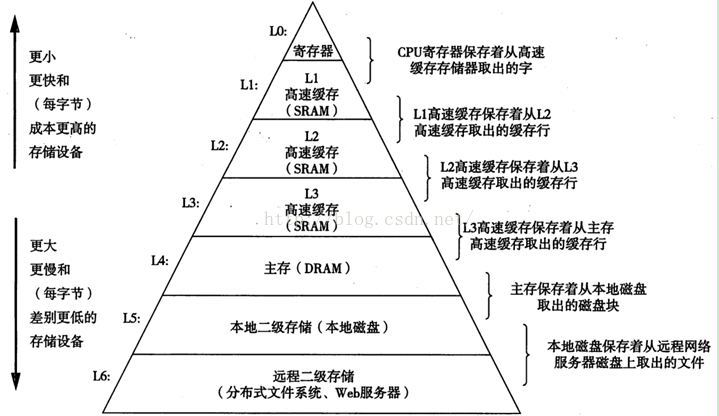
千言万语不如一张图:摘自《深入理解计算机系统第二版》
图1
2. CACHE 缓存什么
CACHE缓存什么么?
不同的缓存都缓存着自己以为重要的东西,来看张图2
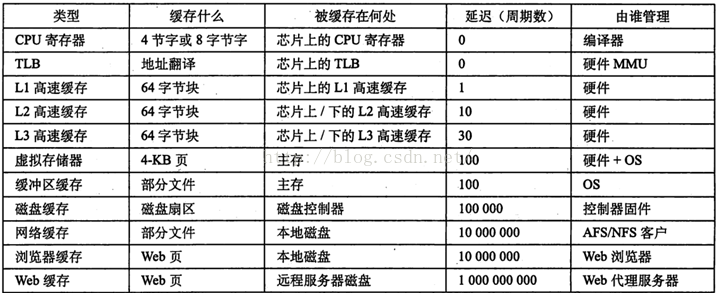
寄存器里面是寄存器有32位和64位(也就是4字节和8字节的)
其中TLB 叫做:翻译后背缓冲器。
MMU:存储管理单元(MemoryManagement Unit)
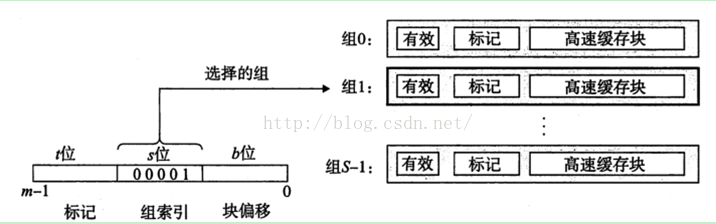
3. 通用高速缓存存储器结构
下图3,讲的非常明白
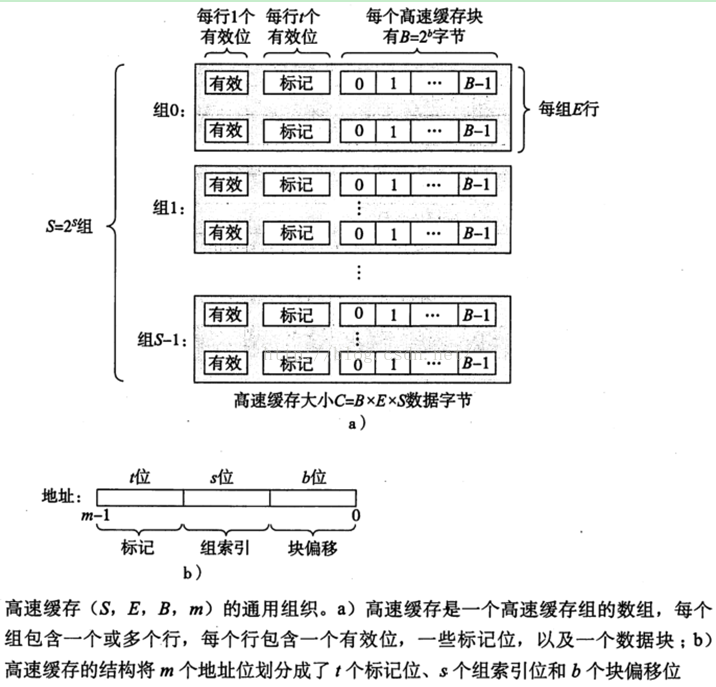
有效位指明这个行是否包含有意义的信息,还有t=m-(b+s), m=t+b+s.
标记位唯一地标识存储在这个高速缓存行中的块。
高速缓存大小,C=SXEXB
我想以上大家都能容易理解的。
3.1 具体工作机制
如上图三所示,参数S和B将m个地址分为了三个字段。
n 其中s个组索引位是一个S个数组的索引。从第0组,第1组,。。到最后一组。组索引位告诉我们这个字必须放在哪个组中。OK。
n 标记位,则告诉我们在这个组的哪一行包含这个字(如果有,需要看有效位是否有效)
n 块偏移位给出了在B个字节的数据块中的字偏移。
我们可以知道对于m位的 内存地址,每个寻址对能对应于CACHE上的一个字节。
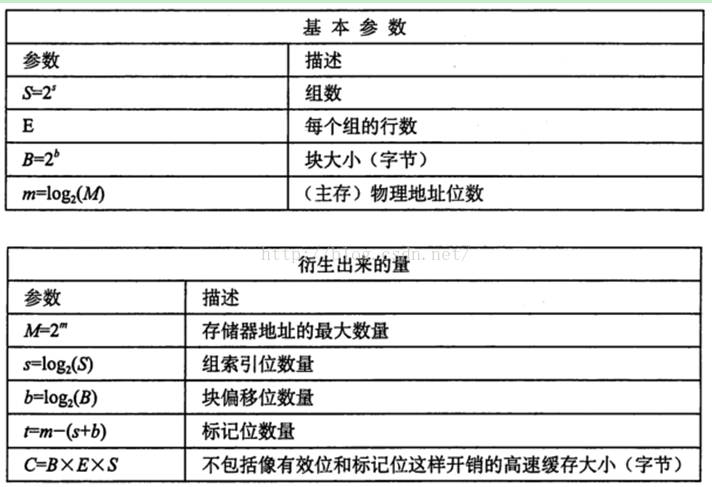
这里放入图4,关于高速缓存参数的小结,这些参数都非常容易理解。
3.1.1 直接映射高速缓存
根据E(每个组的高速缓存行数)高速缓存被分为不同的类。每个组只有一行的高速缓存称为直接高速缓存(direct-mapped cache).
高速缓存确定一个请求是否命中,然后抽取出请求的字的过程,分为三步:
组选择,行匹配,字抽取。
如下图5所示
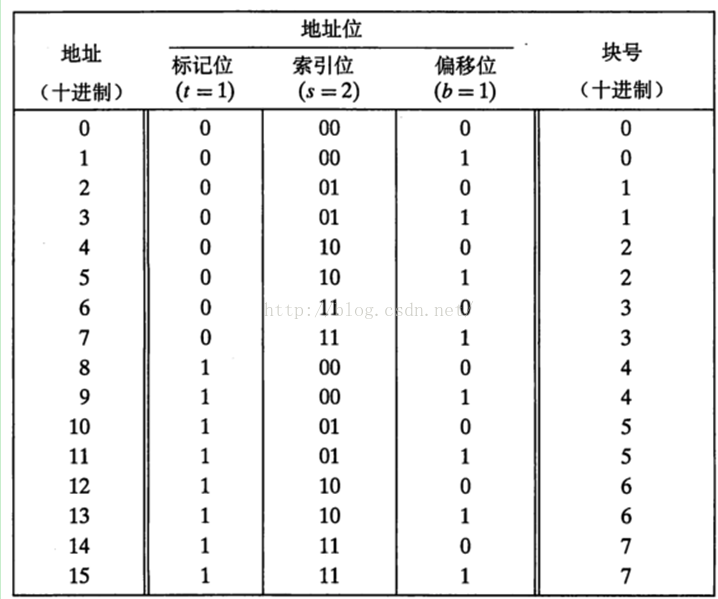
3.1.1.1 例子
这个例子非常好。如下图6-9


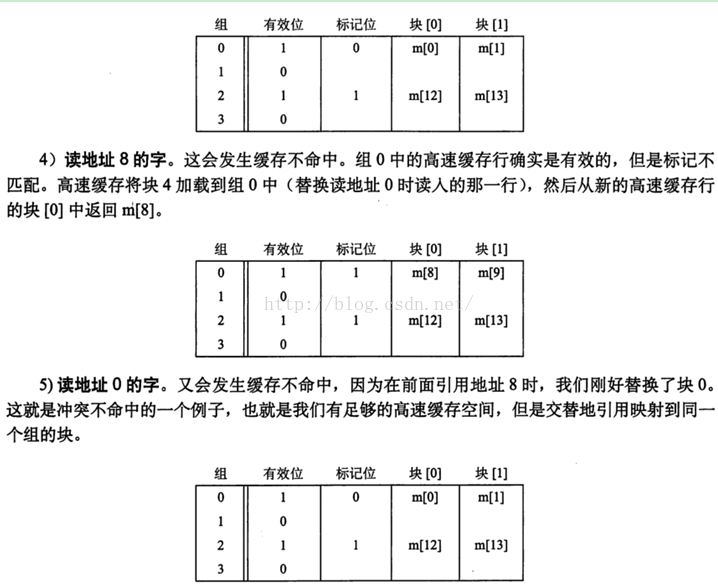
3.1.1.2 直接映射问题
直接映射高速缓存中通常会发生冲突不命中。
即使程序有良好的空间局部性,而且我们的高速缓存中也有足够的空间来存放数据,但是每次引用还是会导致冲突不命中,这是因为这些块被映射到了同一个高速缓存组。
这种抖动导致速度下降2或3倍并不稀奇。这对于更大、更现实的直接映射高速缓存来说,问题很真实。
3.1.2 组相联高速缓存
直接映射高速缓存中冲突不命中造成的问题源于每个组只有一行这个限制。组相联高速缓存(set associative cache)放松了这条限制,每个组都保存有多于一个的高速缓存行。
E>1 但是 E< E/B叫做E路组相联高速缓存。当E=C/B的时候,就是全相联高速缓存了。
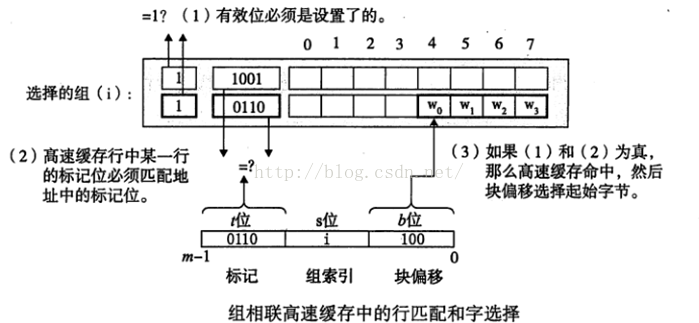
组相联高速缓存中的行匹配比直接映射高速缓存中的更复杂,因为必须检查更多个行的标记位和有效位,以确定所请求的字是是否在集合中。
看如下图10
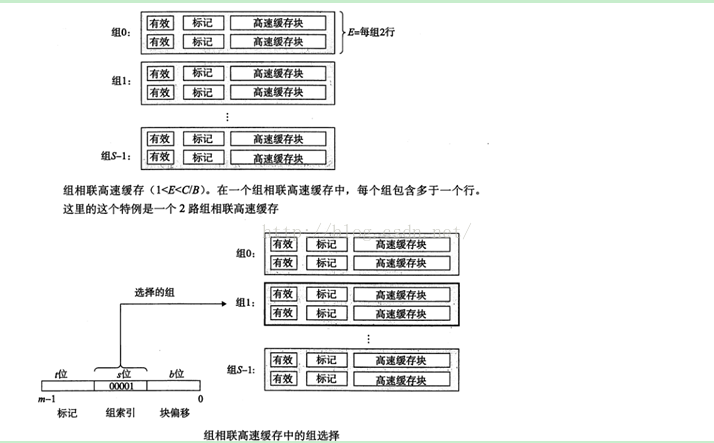
这里需要注意的是,组中任何一行 都可以包含任何映射到这个组的存储器块。
所以高速缓存必须搜索组中的每一行,寻找一个有效的行,其标记与地址中的标记相匹配。
3.1.2.1 有关命中
如果CPU请求的字不再组的任何一行中,那么就是缓存不命中,高速缓存必须从存储器中去取包含这个字的块。如下图11
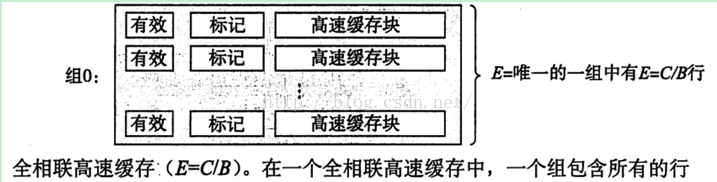
3.1.3 全相联高速缓存
全相联高速缓存(fullyassociative cache)是由一个包含所有高速缓存行的组(即E=C/B)
如下图12
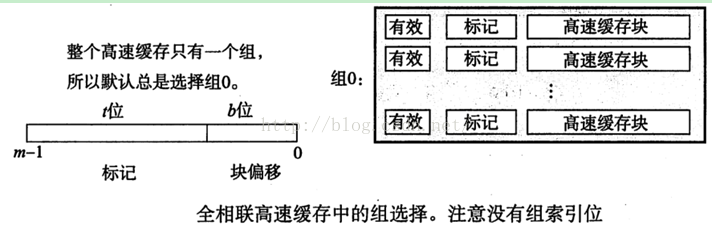
由于全相联,只有一个组,地址只被分为了一个标记和一个块偏移。如下
图13
全相联高速缓存中的行匹配和字选择与组相联高速缓存中的是一样的。区别主要是规模大小的问题。因为高速缓存电路必须并行的搜索许多相匹配的标记,构造一个又大又快的相联高速缓存很困难,而且很昂贵。所以,全相联高速缓存只适合走小的高速缓存,例如TLB,缓存页表项。
3.1.4 有关写
关于读的操作非常简单。写的情况就复杂一些了。
如果更新了一个字节的拷贝之后,怎么更新低一层中的拷贝呢?最简单的方法是直写(write-through),就是将w的高速缓存块写回到紧接着的低一层中。虽然简单,但是直写的缺点是每次写都会引起总线流量。另一种是写回(write-back),尽可能的推迟存储器更新,只有当替换算法要驱逐更新过的块时,才把它写到紧接着的第一层中。写回能显著地减少总线流量,但是它的缺点是增加了复杂性。高速缓存必须为每个高速缓存行维护一个额外的修改位,表明这个高速缓存块是否被修改过。
另外一个问题是,如果处理写不命中。一种方法称为写分配(write-allocate),加载相应的低一层的块到高速缓存中,然后更新这个高速缓存块。写分配视图利用写的空间局部性,但是缺点是每次不命中都会导致一个块从低一层传送到高速缓存。另一种方法,称为非写分配(not-write-allocate),避开高速缓存,直接把这个字写到低一层中。直写高速缓存通常是非写分配的。写回高速缓存通常是写分配的。
3.1.5 实际高速缓存剖析
现代处理的高速缓存即保存指令的高速缓存,又保存数据的高速缓存。称为统一的高速缓存。其中指令高速缓存是制度的,比较简单。
图14i7的
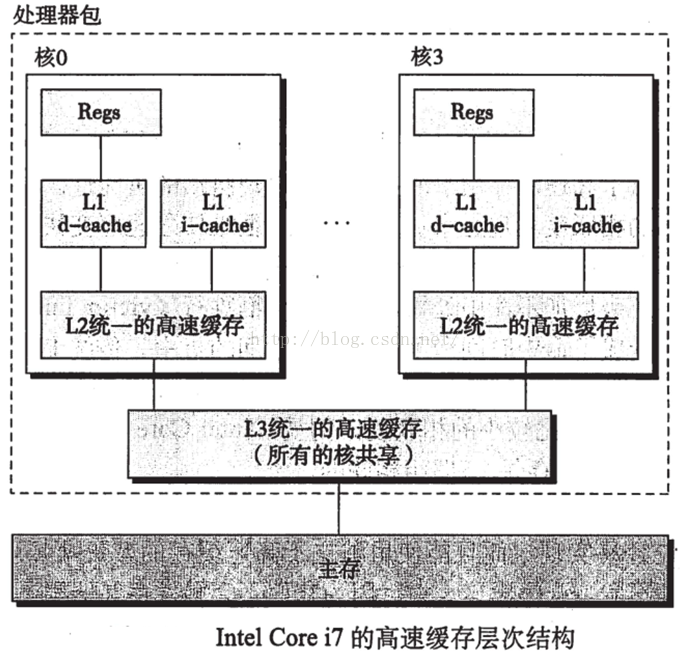
I7高速缓存层次结构的特性如下图15

4. 对性能影响
4.1 高速缓存参数的性能影响
优化高速缓存的成本和性能的折中是一项很精细的工作,需要在现实的基准程序代码上进行大量的模拟。
相联度的优点是降低了高速缓存由于冲突不命中出现抖动的可能性。较高的相联度造成较高的成本,而且很难使速度变快。每一行需要更多的标记位,每一行需要额外的LRU状态为和额外的控制逻辑。也会增加命中时间。
相联度的选择最终编程了命中时间和不命中出发之间的折中。