1.搜索文件名中以指定的字符串开头(如搜索dll,结果中含有dll a,dll abc等)
我的目录下有dll a.txt和dll.txt文件
其中a文件夹下还有这两个文件
我希望通过python选择寻找关键字dll来把这四个文件找出
import os
result=[]
def search(path=".", name=""):
for item in os.listdir(path):
item_path = os.path.join(path, item)
if os.path.isdir(item_path):
search(item_path, name)
elif os.path.isfile(item_path):
if name in item:
global result
result.append(item_path + ";")
print (item_path + ";", end="")
search(path=r"D:\newfile", name="dll")
输出结果:
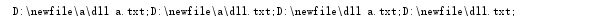
2.如果我只想找出名叫dll的txt,不要dll a.txt,即上文是关键字匹配,这次改为全匹配。那么就要用到搜索指定的文件名
只要将上文代码中
if name in item:
改为
if name+".txt" == item:
即可
3.提取excel某一列中病人姓名并转化为拼音,根据拼音检索某一路径下的对应图片路径
# -*-coding:utf-8-*- import xlrd import os import re from xlwt import * from xpinyin import Pinyin pa=None myItem_path = [] def file_name(file_dir): for root, dirs, files in os.walk(file_dir): return(dirs) #当前路径下所有非目录子文件 def search(path=".", name="1"): for item in os.listdir(path): global pa item_path = os.path.join(path, item) if os.path.isdir(item_path): search(item_path, name) # if(t==None):pa=None elif os.path.isfile(item_path): if name+".jpg" == item: myItem_path.append(item_path+";") print (item_path+";",end="") pa=myItem_path #------------------读数据-------------------------------- fileName="D:\\study\\xmu\\420\\廖希一\\数字化之后\\上机名单-2014,2015.xls" bk=xlrd.open_workbook(fileName) shxrange=range(bk.nsheets) try: sh=bk.sheet_by_name("2014年") except: print ("代码出错") nrows=sh.nrows #获取行数 book = Workbook(encoding='utf-8') sheet = book.add_sheet('Sheet1') #创建一个sheet p = Pinyin() for i in range(1,nrows): # row_data=sh.row_values(i) #获取第i行第3列数据 # #---------写出文件到excel-------- # if i==16: # break a=p.get_pinyin( sh.cell_value(i,2), ' ') search(path=r"D:\study\xmu\420\廖希一\photo", name=a) myItem_path=[] print ("-----正在写入 "+str(i)+" 行") sheet.write(i,0, label = sh.cell_value(i,2)) #向第1行第1列写入获取到的值 sheet.write(i,1, label = sh.cell_value(i,4))#向第1行第2列写入获取到的值 sheet.write(i,2, label=a) sheet.write(i,3, label=pa) pa=None book.save("D:\\study\\xmu\\420\\廖希一\\数字化之后\\上机名单-2014+图片路径.xls")