作业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3159
可以用pandas读出之前保存的数据:
newsdf = pd.read_csv(r'F:duymgzccnews.csv')
一.把爬取的内容保存到数据库sqlite3
import sqlite3
with sqlite3.connect('gzccnewsdb.sqlite') as db:
newsdf.to_sql('gzccnews',con = db)
with sqlite3.connect('gzccnewsdb.sqlite') as db:
df2 = pd.read_sql_query('SELECT * FROM gzccnews',con=db)
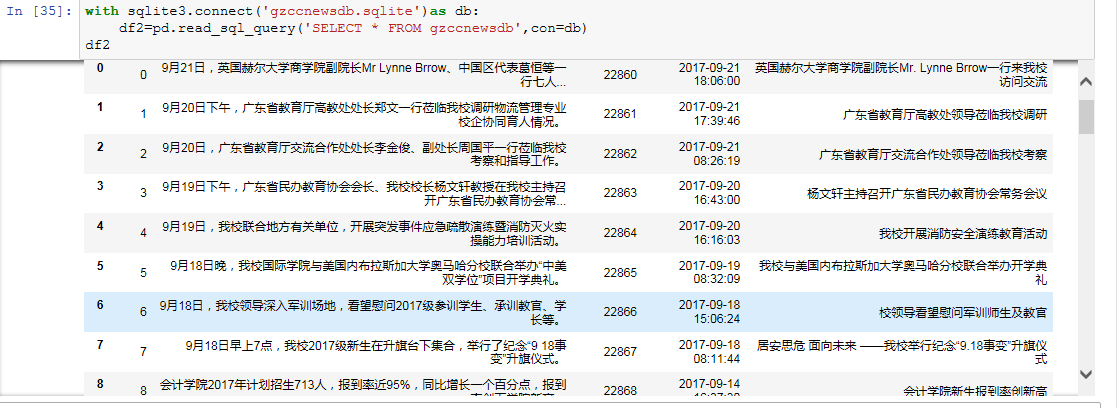
保存到MySQL数据库
- import pandas as pd
- import pymysql
- from sqlalchemy import create_engine
- conInfo = "mysql+pymysql://user:passwd@host:port/gzccnews?charset=utf8"
- engine = create_engine(conInfo,encoding='utf-8')
- df = pd.DataFrame(allnews)
- df.to_sql(name = ‘news', con = engine, if_exists = 'append', index = False)
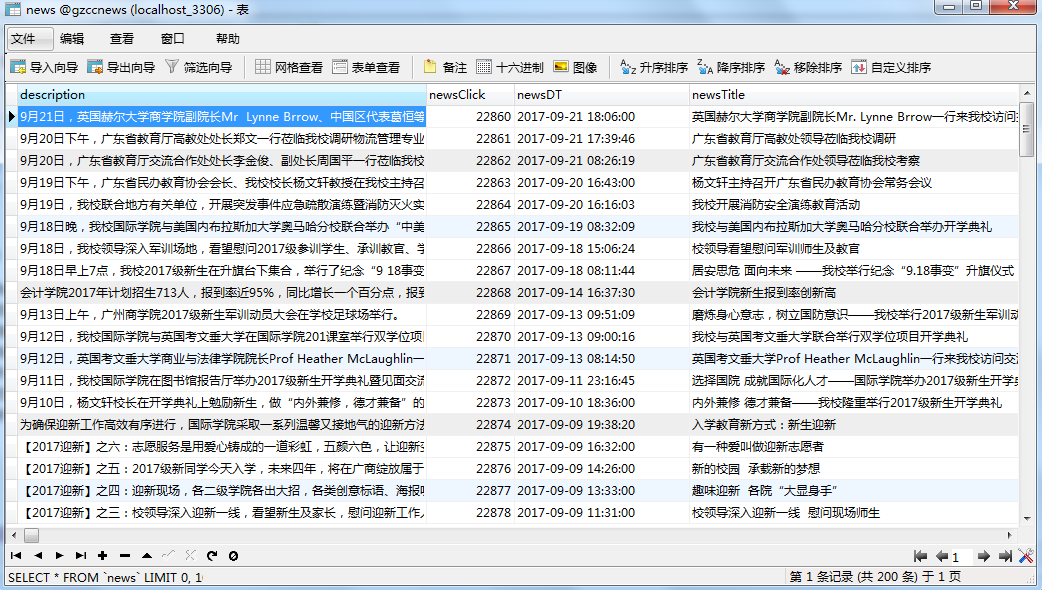
二.爬虫综合大作业
- 选择一个热点或者你感兴趣的主题。
- 选择爬取的对象与范围。
- 了解爬取对象的限制与约束。
- 爬取相应内容。
- 做数据分析与文本分析。
- 形成一篇文章,有说明、技术要点、有数据、有数据分析图形化展示与说明、文本分析图形化展示与说明。
- 文章公开发布。
三.爬虫注意事项
1.设置合理的爬取间隔,不会给对方运维人员造成压力,也可以防止程序被迫中止。
- import time
- import random
- time.sleep(random.random()*3)
2.设置合理的user-agent,模拟成真实的浏览器去提取内容。
- 首先打开你的浏览器输入:about:version。
- 用户代理:
- 收集一些比较常用的浏览器的user-agent放到列表里面。
- 然后import random,使用随机获取一个user-agent
- 定义请求头字典headers={’User-Agen‘:}
- 发送request.get时,带上自定义了User-Agen的headers
爬取对象:猫眼电影复仇者联盟4,:终局之战
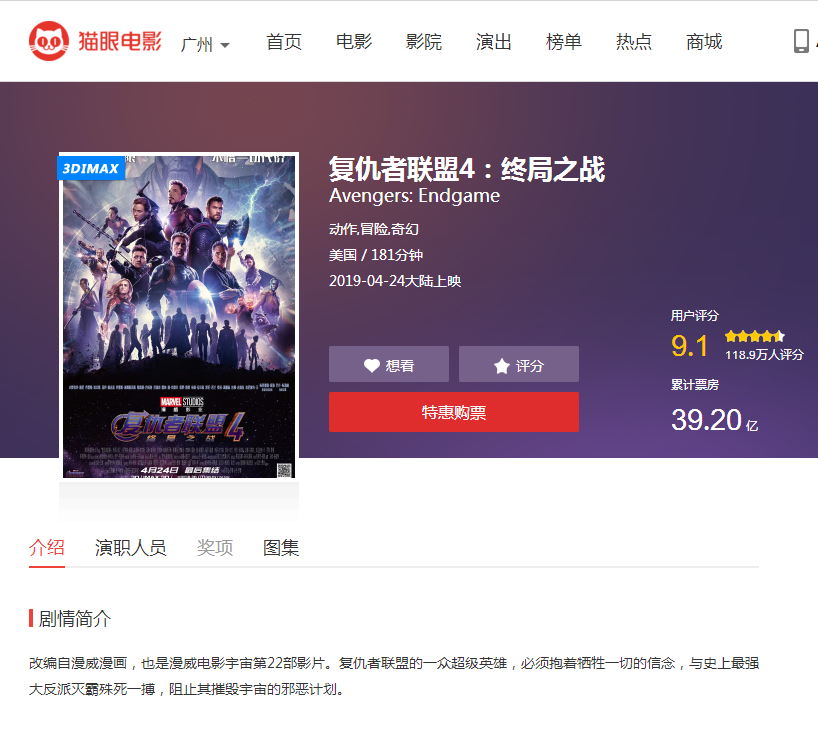
爬取链接:https://maoyan.com/films/248172
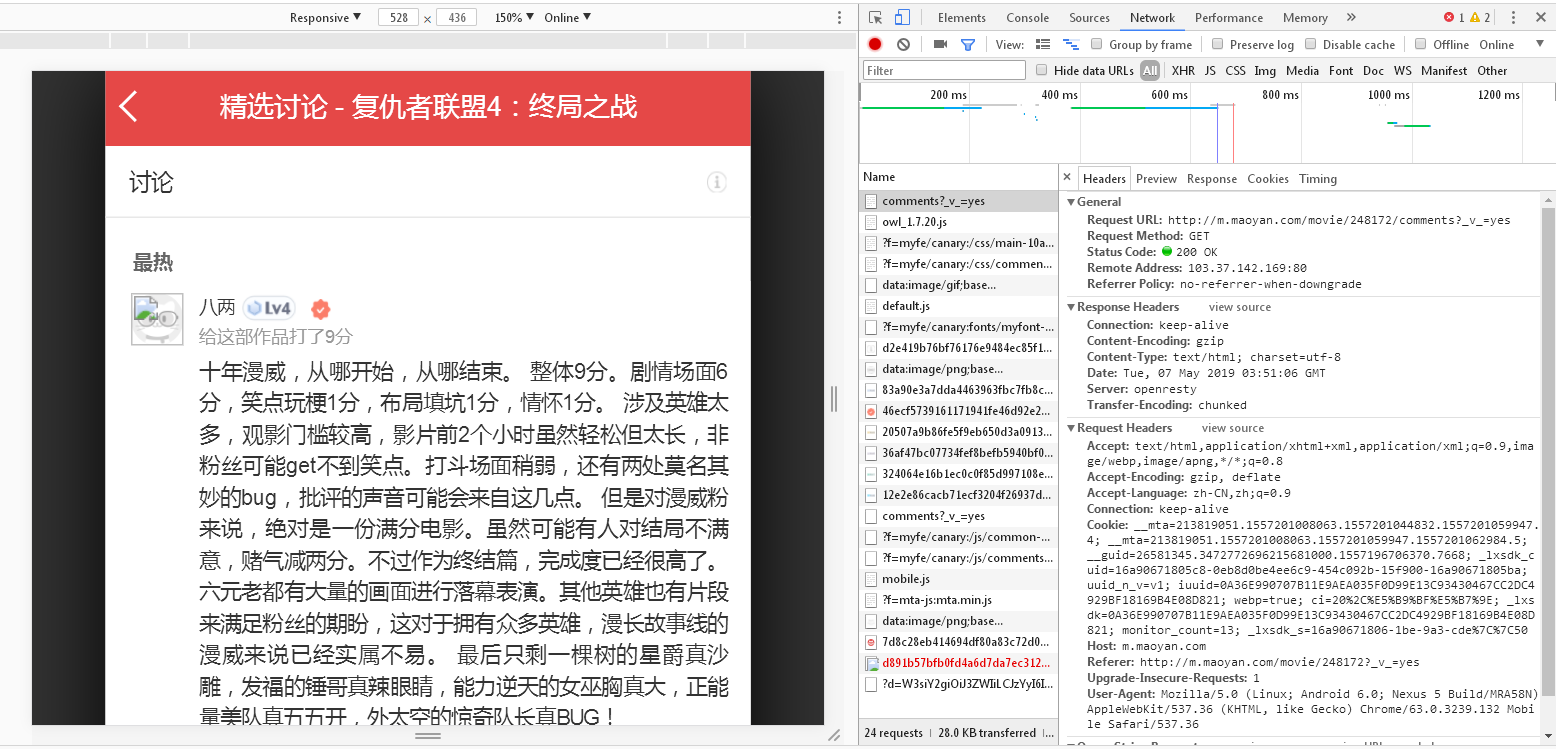
通过分析发现猫眼APP的评论数据接口为:http://m.maoyan.com/review/v2/comments.json?movieId=248172&userId=-1&offset=0&limit=15&ts=0&type=3

通过对评论数据进行分析,得到如下信息:
返回的是json格式数据
1200486表示电影的专属id;offset表示偏移量;startTime表示获取评论的起始时间,从该时间向前取数据,即获取最新的评论
cmts表示评论,每次获取15条,offset偏移量是指每次获取评论时的起始索引,向后取15条
hcmts表示热门评论前10条
total表示总评论数
代码实现:
这里先定义一个函数,用来根据指定url获取数据,且只能获取到指定的日期向前获取到15条评论数据,对获取的数据进行处理,转换为json。
为了能够获取到所有评论数据,方法是:从当前时间开始,向前获取数据,根据url每次获取15条,然后得到末尾评论的时间,从该时间继续向前获取数据,直到影片上映日期(2019-04-24)为止,获取这之间的所有数据。
from urllib import request
import json
import time
from datetime import datetime
from datetime import timedelta
# 获取数据,根据url获取
def get_data(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36'
}
req = request.Request(url, headers=headers)
response = request.urlopen(req)
if response.getcode() == 200:
return response.read()
return None
# 处理数据
def parse_data(html):
data = json.loads(html)['cmts'] # 将str转换为json
comments = []
for item in data:
comment = {
'id': item['id'],
'nickName': item['nickName'],
'cityName': item['cityName'] if 'cityName' in item else '', # 处理cityName不存在的情况
'content': item['content'].replace('
', ' ', 10), # 处理评论内容换行的情况
'score': item['score'],
'startTime': item['startTime']
}
comments.append(comment)
return comments
# 存储数据,存储到文本文件
def save_to_txt():
start_time = datetime.now().strftime('%Y-%m-%d %H:%M:%S') # 获取当前时间,从当前时间向前获取
end_time = '2019-04-24 00:00:00'
while start_time > end_time:
url = 'http://m.maoyan.com/mmdb/comments/movie/248172.json?_v_=yes&offset=0&startTime=' + start_time.replace(' ', '%20')
html = None
'''
问题:当请求过于频繁时,服务器会拒绝连接,实际上是服务器的反爬虫策略
解决:1.在每个请求间增加延时0.1秒,尽量减少请求被拒绝
2.如果被拒绝,则0.5秒后重试
'''
try:
html = get_data(url)
except Exception as e:
time.sleep(0.5)
html = get_data(url)
else:
time.sleep(0.1)
comments = parse_data(html)
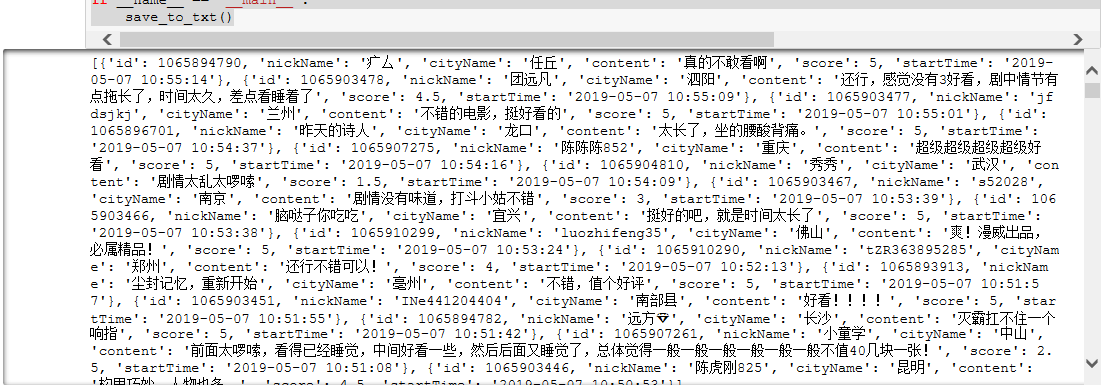
print(comments)
start_time = comments[14]['startTime'] # 获得末尾评论的时间
start_time = datetime.strptime(start_time, '%Y-%m-%d %H:%M:%S') + timedelta(seconds=-1) # 转换为datetime类型,减1秒,避免获取到重复数据
start_time = datetime.strftime(start_time, '%Y-%m-%d %H:%M:%S') # 转换为str
for item in comments:
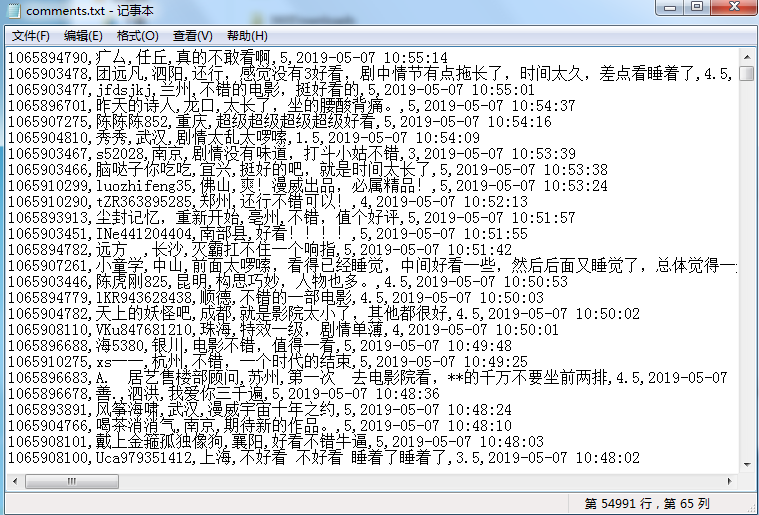
with open('F:comments.txt', 'a+', encoding='utf-8') as f:
text=f.write(str(item['id'])+','+item['nickName'] + ',' + item['cityName'] + ',' + item['content'] + ',' + str(item['score'])+ ',' + item['startTime'] + '
')
if __name__ == '__main__':
save_to_txt()
成功保存到本地文本:
创建及生成词云:
# 导入jieba模块,用于中文分词
import jieba
# 导入matplotlib,用于生成2D图形
import matplotlib.pyplot as plt
# 导入wordcount,用于制作词云图
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
# 获取所有评论
comments = []
with open('comments.txt', mode='r', encoding='utf-8') as f:
rows = f.readlines()
for row in rows:
comment = row.split(',')[3]
if comment != '':
comments.append(comment)
# 设置分词
comment_after_split = jieba.cut(str(comments), cut_all=False) # 非全模式分词,cut_all=false
words = " ".join(comment_after_split) # 以空格进行拼接
# print(words)
# 设置屏蔽词
stopwords = STOPWORDS.copy()
stopwords.add("电影")
stopwords.add("一部")
stopwords.add("一个")
stopwords.add("没有")
stopwords.add("什么")
stopwords.add("有点")
stopwords.add("这部")
stopwords.add("这个")
stopwords.add("不是")
stopwords.add("真的")
stopwords.add("感觉")
stopwords.add("觉得")
stopwords.add("还是")
stopwords.add("但是")
stopwords.add("就是")
# 导入背景图
bg_image = plt.imread('bg.jpg')
# 设置词云参数,参数分别表示:画布宽高、背景颜色、背景图形状、字体、屏蔽词、最大词的字体大小
wc = WordCloud(width=1024, height=768, background_color='white', mask=bg_image, font_path='STKAITI.TTF',
stopwords=stopwords, max_font_size=400, random_state=50)
# 将分词后数据传入云图
wc.generate_from_text(words)
plt.imshow(wc)
plt.axis('off') # 不显示坐标轴
plt.show()
# 保存结果到本地
wc.to_file('词云图.jpg')

生成评分图:
# 导入Pie组件,用于生成饼图
from pyecharts import Pie
# 获取评论中所有评分
rates = []
with open('comments.txt', mode='r', encoding='utf-8') as f:
rows = f.readlines()
for row in rows:
rates.append(row.split(',')[4])
# print(rates)
# 定义星级,并统计各星级评分数量
attr = ["五星", "四星", "三星", "二星", "一星"]
value = [
rates.count('5') + rates.count('4.5'),
rates.count('4') + rates.count('3.5'),
rates.count('3') + rates.count('2.5'),
rates.count('2') + rates.count('1.5'),
rates.count('1') + rates.count('0.5')
]
# print(value)
pie = Pie('《复仇者联盟4:终局之战》评分星级比例', title_pos='center', width=900)
pie.add("7-17", attr, value, center=[75, 50], is_random=True,
radius=[30, 75], rosetype='area',
is_legend_show=False, is_label_show=True)
pie.render('评分.html')
如图:
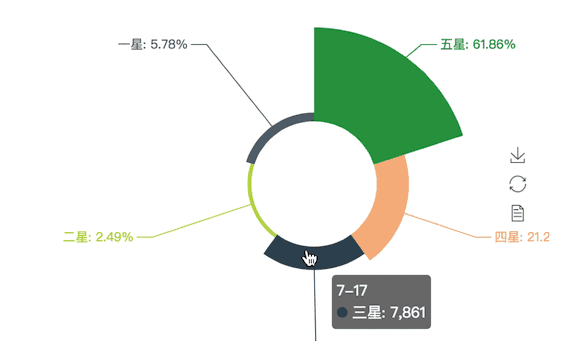
从图中可以看出,五星比例接近62%,四星比例为21%,两者合计高达83%,可见口碑还是相当不错的,一星占比不足6%
《复仇者联盟4:终局之战》作为复仇者系列的最后一部电影,同时也是斯坦李漫威老爷子的终身制作,不仅成就了漫威的英雄电影,还成就了众多参与拍摄的演职人员。在拍摄过程中导演和老爷子对每个角色的要求是很严格的,不论是一直追随的漫威忠实迷,还是因为美队和妮妮入坑的粉丝,都对这部电影贡献了很大的票房,又或者出于对已逝老爷子--漫威之父斯坦李的缅怀,都造就了这部电影。所以有这样的成绩,也是理所当然。