一、概述
1、赫夫曼编码也翻译为 哈夫曼编码(Huffman Coding),又称霍夫曼编码,是一种编码方式, 属于一种程序算法
2、赫夫曼编码是赫哈夫曼树在电讯通信中的经典的应用之一。
3、赫夫曼编码广泛地用于数据文件压缩。其压缩率通常在20%~90%之间
4、赫夫曼码是可变字长编码(VLC)的一种。Huffman于1952年提出一种编码方法,称之为最佳编码
二、原理
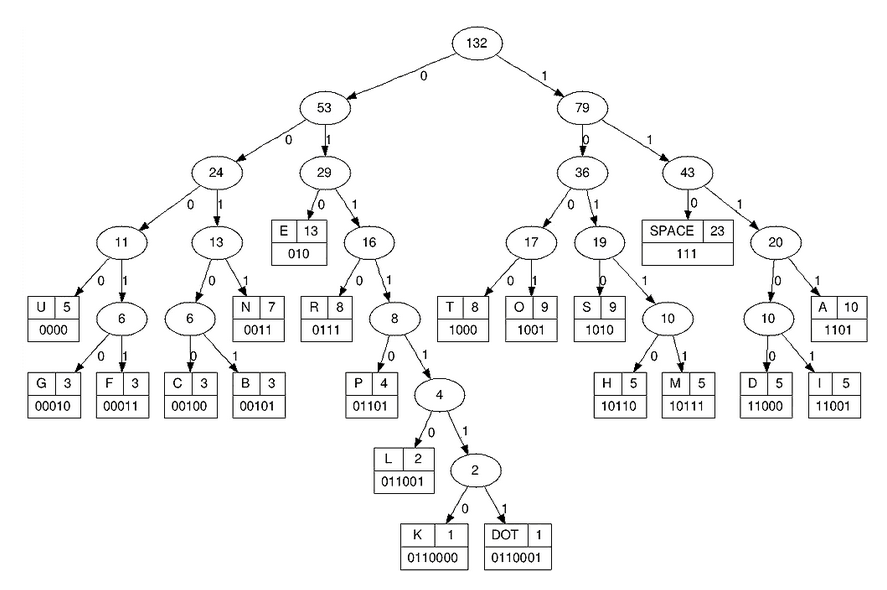
三、代码
1 public class HuffmanCode { 2 //1. 将赫夫曼编码表存放在 Map<Byte,String> 形式 3 // 生成的赫夫曼编码表 4 // 32=01, 97=100, 100=11000, 117=11001, 5 // 101=1110, 118=11011, 105=101, 121=11010, 6 // 106=0010, 107=1111, 108=000, 111=0011} 7 static HashMap<Byte, String> huffmanCodes = new HashMap<>(); 8 //2. 在生成赫夫曼编码表示,需要去拼接路径, 定义一个StringBuilder 存储某个叶子结点的路径 9 static StringBuilder sb = new StringBuilder(); 10 11 public static void main(String[] args) { 12 String content = "i like like like java do you like a java"; 13 byte[] contentBytes = content.getBytes(); 14 System.out.println(Arrays.toString(contentBytes)); 15 16 17 //3.0测试压缩 18 String src = "Uninstall.xml"; 19 String dst = "Uninstall.zip"; 20 //zipFile(src, dst); 21 System.out.println("压缩文件完成"); 22 23 //4.0测试解压文件 24 String zipFile = "Uninstall.zip"; 25 String dstFile = "Uninstall2.xml"; 26 unZipFile(zipFile, dstFile); 27 28 /*2.0 29 //缩减的压缩,解压过程 30 byte[] huffmanCodesBytes = huffmanZip(contentBytes); 31 System.out.println("压缩后的结果是:" + Arrays.toString(huffmanCodesBytes) + " 长度= " + huffmanCodesBytes.length); 32 33 byte[] sourceBytes = decode(huffmanCodes, huffmanCodesBytes); 34 System.out.println("原来的字符串=" + new String(sourceBytes)); 35 */ 36 /* 37 //1.0分析过程 38 39 //1.1获取根据单个字符ASII一样的统计个数的list集合 40 ArrayList<Node> nodes = getNode(contentBytes); 41 //System.out.println(nodes); 42 //1.2创建赫夫曼树 43 Node huffmanTreeRoot = createHuffmanTree(nodes); 44 //1.3前序遍历赫夫曼树 45 huffmanTreeRoot.preOrder(); 46 //1.4生成赫夫曼编码 47 HashMap<Byte, String> huffmanCodes = getCodes(huffmanTreeRoot); 48 //System.out.println(huffmanCodes); 49 //1.5测试 50 byte[] huffmanCodeBytes = zip(contentBytes, huffmanCodes); 51 System.out.println(Arrays.toString(huffmanCodeBytes)); 52 */ 53 } 54 55 /** 56 * @param src 你传入的希望压缩的文件的全路径 57 * @param dst 我们压缩后将压缩文件放到哪个目录 58 */ 59 private static void zipFile(String src, String dst) { 60 FileInputStream is = null; 61 FileOutputStream fos = null; 62 ObjectOutputStream osw = null; 63 try { 64 65 is = new FileInputStream(src); 66 //创建一个和源文件大小一样的byte[] 67 byte[] b = new byte[is.available()]; 68 //读取文件 69 is.read(b); 70 //直接对源文件压缩 71 byte[] huffmanBytes = huffmanZip(b); 72 //创建文件的输出流, 存放压缩文件 73 fos = new FileOutputStream(dst); 74 //创建一个和文件输出流关联的ObjectOutputStream 75 osw = new ObjectOutputStream(fos); 76 //把 赫夫曼编码后的字节数组写入压缩文件 77 osw.writeObject(huffmanBytes); 78 //这里我们以对象流的方式写入 赫夫曼编码,是为了以后我们恢复源文件时使用 79 //注意一定要把赫夫曼编码 写入压缩文件 80 osw.writeObject(huffmanCodes); 81 82 } catch (IOException e) { 83 System.out.println(e.getMessage()); 84 } finally { 85 try { 86 if (is != null) 87 is.close(); 88 } catch (IOException e) { 89 e.printStackTrace(); 90 } 91 try { 92 if (osw != null) 93 osw.close(); 94 } catch (IOException e) { 95 e.printStackTrace(); 96 } 97 try { 98 if (fos != null) 99 fos.close(); 100 } catch (IOException e) { 101 e.printStackTrace(); 102 } 103 } 104 } 105 106 /** 107 * @param zipFile 准备解压的文件 108 * @param dstFile 将文件解压到哪个路径 109 */ 110 private static void unZipFile(String zipFile, String dstFile) { 111 112 FileInputStream fis = null; 113 ObjectInputStream ois = null; 114 FileOutputStream fos = null; 115 try { 116 fis = new FileInputStream(zipFile); 117 ois = new ObjectInputStream(fis); 118 //读取byte数组 huffmanBytes 119 byte[] huffmanBytes = (byte[]) ois.readObject(); 120 //读取赫夫曼编码表 121 HashMap<Byte, String> huffmanCodes = (HashMap<Byte, String>) ois.readObject(); 122 //解码 123 byte[] bytes = decode(huffmanCodes, huffmanBytes); 124 //将bytes 数组写入到目标文件 125 fos = new FileOutputStream(dstFile); 126 //写数据到 dstFile 文件 127 fos.write(bytes); 128 } catch (Exception e) { 129 System.out.println(e.getMessage()); 130 } finally { 131 try { 132 if (fis != null) { 133 fis.close(); 134 } 135 } catch (IOException e) { 136 e.printStackTrace(); 137 } 138 try { 139 if (ois != null) { 140 ois.close(); 141 } 142 } catch (IOException e) { 143 e.printStackTrace(); 144 } 145 try { 146 if (fos != null) { 147 fos.close(); 148 } 149 } catch (IOException e) { 150 e.printStackTrace(); 151 } 152 } 153 } 154 155 156 //完成数据的解压 157 //思路 158 //1. 将huffmanCodeBytes [-88, -65, -56, -65, -56, -65, -55, 77, -57, 6, -24, -14, -117, -4, -60, -90, 28] 159 // 重写先转成 赫夫曼编码对应的二进制的字符串 "1010100010111..." 160 //2. 赫夫曼编码对应的二进制的字符串 "1010100010111..." =》 对照 赫夫曼编码 =》 "i like like like java do you like a java" 161 162 //编写一个方法,完成对压缩数据的解码 163 164 /** 165 * @param huffmanCodes 赫夫曼编码表 map 166 * @param huffmanBytes 赫夫曼编码得到的字节数组 167 * @return 就是原来的字符串对应的数组 168 */ 169 private static byte[] decode(Map<Byte, String> huffmanCodes, byte[] huffmanBytes) { 170 171 //1. 先得到 huffmanBytes 对应的 二进制的字符串 , 形式 1010100010111... 172 StringBuilder stringBuilder = new StringBuilder(); 173 //将byte数组转成二进制的字符串 174 for (int i = 0; i < huffmanBytes.length; i++) { 175 byte b = huffmanBytes[i]; 176 //判断是不是最后一个字节 177 boolean flag = (i == huffmanBytes.length - 1); 178 stringBuilder.append(byteToBitString(!flag, b)); 179 } 180 //把字符串安装指定的赫夫曼编码进行解码 181 //把赫夫曼编码表进行调换,因为反向查询 a->100 100->a 182 Map<String, Byte> map = new HashMap<String, Byte>(); 183 for (Map.Entry<Byte, String> entry : huffmanCodes.entrySet()) { 184 map.put(entry.getValue(), entry.getKey()); 185 } 186 187 //创建要给集合,存放byte 188 List<Byte> list = new ArrayList<>(); 189 //i 可以理解成就是索引,扫描 stringBuilder 190 for (int i = 0; i < stringBuilder.length(); ) { 191 int count = 1; // 小的计数器 192 boolean flag = true; 193 Byte b = null; 194 195 while (flag) { 196 //1010100010111... 197 //递增的取出 key 1 198 String key = stringBuilder.substring(i, i + count);//i 不动,让count移动,指定匹配到一个字符 199 b = map.get(key); 200 if (b == null) {//说明没有匹配到 201 count++; 202 } else { 203 //匹配到 204 flag = false; 205 } 206 } 207 list.add(b); 208 i += count;//i 直接移动到 count 209 } 210 //当for循环结束后,我们list中就存放了所有的字符 "i like like like java do you like a java" 211 //把list 中的数据放入到byte[] 并返回 212 byte b[] = new byte[list.size()]; 213 for (int i = 0; i < b.length; i++) { 214 b[i] = list.get(i); 215 } 216 return b; 217 218 } 219 220 /** 221 * 将一个byte 转成一个二进制的字符串, 如果看不懂,可以参考我讲的Java基础 二进制的原码,反码,补码 222 * 223 * @param b 传入的 byte 224 * @param flag 标志是否需要补高位如果是true ,表示需要补高位,如果是false表示不补, 如果是最后一个字节,无需补高位 225 * @return 是该b 对应的二进制的字符串,(注意是按补码返回) 226 */ 227 private static String byteToBitString(boolean flag, byte b) { 228 //使用变量保存 b 229 int temp = b;//将 b 转成 int 230 //如果是正数我们还存在补高位 231 if (flag) { 232 temp |= 256;//按位与 256 1 0000 0000 | 0000 0001 => 1 0000 0001 233 } 234 String str = Integer.toBinaryString(temp); 235 if (flag) { 236 return str.substring(str.length() - 8); 237 } else { 238 return str; 239 } 240 } 241 //使用一个方法,将前面的方法封装起来,便于我们的调用. 242 243 /** 244 * @param bytes 原始的字符串对应的字节数组 245 * @return 是经过 赫夫曼编码处理后的字节数组(压缩后的数组) 246 */ 247 private static byte[] huffmanZip(byte[] bytes) { 248 ArrayList<Node> nodes = getNode(bytes); 249 //根据 nodes 创建的赫夫曼树 250 Node huffmanTreeRoot = createHuffmanTree(nodes); 251 //对应的赫夫曼编码(根据 赫夫曼树) 252 HashMap<Byte, String> huffmanCodes = getCodes(huffmanTreeRoot); 253 //根据生成的赫夫曼编码,压缩得到压缩后的赫夫曼编码字节数组 254 byte[] huffmanCodeBytes = zip(bytes, huffmanCodes); 255 return huffmanCodeBytes; 256 } 257 258 /** 259 * 编写一个方法,将字符串对应的byte[] 数组,通过生成的赫夫曼编码表,返回一个赫夫曼编码 压缩后的byte[] 260 * 261 * @param bytes 这时原始的字符串对应的 byte[] 262 * @param huffmanCodes 生成的赫夫曼编码map 263 * @return 返回赫夫曼编码处理后的 byte[] 264 * 举例: String content = "i like like like java do you like a java"; =》 byte[] contentBytes = content.getBytes(); 265 * 返回的是 字符串 "1010100010111111110010001011111111001000101111111100100101001101110001110000011011101000111100101000101111111100110001001010011011100" 266 * => 对应的 byte[] huffmanCodeBytes ,即 8位对应一个 byte,放入到 huffmanCodeBytes 267 * huffmanCodeBytes[0] = 10101000(补码) => byte [推导 10101000=> 10101000 - 1 => 10100111(反码)=> 11011000= -88 ] 268 * huffmanCodeBytes[1] = -88 269 */ 270 private static byte[] zip(byte[] bytes, HashMap<Byte, String> huffmanCodes) { 271 StringBuilder stringBuilder = new StringBuilder(); 272 for (byte b : bytes) { 273 stringBuilder.append(huffmanCodes.get(b)); 274 } 275 //System.out.println(stringBuilder); 276 //统计返回 byte[] huffmanCodeBytes 长度 277 //一句话 int len = (stringBuilder.length() + 7) / 8; 278 int len; 279 if (stringBuilder.length() % 8 == 0) { 280 len = stringBuilder.length() / 8; 281 } else { 282 len = stringBuilder.length() / 8 + 1; 283 } 284 byte[] huffmanCodeBytes = new byte[len]; 285 int index = 0; 286 for (int i = 0; i < stringBuilder.length(); i += 8) { 287 String b; 288 if (i + 8 > stringBuilder.length()) { 289 b = stringBuilder.substring(i); 290 } else { 291 b = stringBuilder.substring(i, i + 8); 292 } 293 //将strByte 转成一个byte,放入到 huffmanCodeBytes 294 huffmanCodeBytes[index] = (byte) Integer.parseInt(b, 2); 295 index++; 296 } 297 return huffmanCodeBytes; 298 } 299 300 private static HashMap<Byte, String> getCodes(Node root) { 301 if (root == null) { 302 return null; 303 } 304 //处理root的左子树 305 getCodes(root.left, "0", sb); 306 //处理root的右子树 307 getCodes(root.right, "1", sb); 308 return huffmanCodes; 309 } 310 311 /** 312 * 功能:将传入的node结点的所有叶子结点的赫夫曼编码得到,并放入到huffmanCodes集合 313 * 314 * @param node 传入结点 315 * @param code 路径: 左子结点是 0, 右子结点 1 316 * @param sb 用于拼接路径 317 */ 318 private static void getCodes(Node node, String code, StringBuilder sb) { 319 StringBuilder sbb = new StringBuilder(sb); 320 sbb.append(code); 321 if (node != null) { 322 //判断当前node 是叶子结点还是非叶子结点 323 if (node.data == null) {//非叶子结点,不存数据data 324 //向左递归 325 getCodes(node.left, "0", sbb); 326 //向右递归 327 getCodes(node.right, "1", sbb); 328 } else {//说明是一个叶子结点 329 //就表示找到某个叶子结点的最后 330 huffmanCodes.put(node.data, sbb.toString()); 331 } 332 } 333 } 334 335 //可以通过List 创建对应的赫夫曼树 336 private static Node createHuffmanTree(ArrayList<Node> nodes) { 337 338 while (nodes.size() > 1) { 339 //每次添加完节点,并且删除原来的节点后,是乱序的,只能每次循环都要排序 340 Collections.sort(nodes); 341 //取出第一颗最小的二叉树 342 Node left = nodes.get(0); 343 //取出第二颗最小的二叉树 344 Node right = nodes.get(1); 345 //创建一颗新的二叉树,它的根节点 没有data, 只有权值 346 Node parent = new Node(null, left.weight + right.weight); 347 348 parent.left = left; 349 parent.right = right; 350 //将已经处理的两颗二叉树从nodes删除 351 nodes.remove(left); 352 nodes.remove(right); 353 //将新的二叉树,加入到nodes 354 nodes.add(parent); 355 } 356 //nodes 最后的结点,就是赫夫曼树的根结点 357 return nodes.get(0); 358 } 359 360 /** 361 * @param bytes 接收字节数组 362 * @return 返回的就是 List 形式 [Node[date=97 ,weight = 5], Node[]date=32,weight = 9]......], 363 */ 364 private static ArrayList<Node> getNode(byte[] bytes) { 365 HashMap<Byte, Integer> map = new HashMap<>(); 366 for (byte b : bytes) { 367 Integer i = map.get(b); 368 if (i == null) { 369 map.put(b, 1); 370 } else 371 map.put(b, ++i); 372 } 373 ArrayList<Node> list = new ArrayList<>(); 374 for (Map.Entry<Byte, Integer> entry : map.entrySet()) { 375 list.add(new Node(entry.getKey(), entry.getValue())); 376 } 377 378 return list; 379 } 380 } 381 382 class Node implements Comparable<Node> { 383 // 存放数据(字符)本身,比如'a' => 97 ' ' => 32 384 Byte data; 385 //权值, 表示字符出现的次数 386 int weight; 387 Node left; 388 Node right; 389 390 public Node(Byte data, int weight) { 391 this.data = data; 392 this.weight = weight; 393 } 394 395 396 @Override 397 public String toString() { 398 return "Node{" + 399 "data=" + data + 400 ", weight=" + weight + 401 '}'; 402 } 403 404 @Override 405 public int compareTo(Node o) { 406 return this.weight - o.weight; 407 } 408 409 public void preOrder() { 410 System.out.println(this); 411 if (this.left != null) { 412 this.left.preOrder(); 413 } 414 if (this.right != null) { 415 this.right.preOrder(); 416 } 417 } 418 }