本文主要介绍Hadoop的数据管理,主要包括Hadoop的分布式文件系统HDFS、分布式数据库HBase和数据仓库工具Hive。
1 HDFS的数据管理
HDFS是分布式计算的存储基石,Hadoop分布式文件系统和其他分布式文件系统有很多类似的特性:
- 对于整个集群有单一的命名空间;
- 具有数据一致性,都适合一次写入多次读取的模型,客户端在文件没有被成功创建之前是无法看到文件存在的;
- 文件会被分割成多个文件块,每个文件块被分配存储到数据节点上,而且会根据配置由复制文件块来保证数据的安全性。
HDFS 通过三个重要的角色来进行文件系统的管理:NameNode、DataNode和Client。NameNode可以看做是分布式文件系统中的管理者,主 要负责管理文件系统的命名空间、集群配置信息和存储块的复制等。NameNode会将文件系统的 Metadata存储在内存中,这些信息主要包括文件信息、每一个文件对应的文件块的信息和每一个文件块在DataNode中的信息等。DataNode 是文件存储的基本单元,它将文件块(Block)存储在本地文件系统中,保存了所有Block的Metadata,同时周期性地将所有存在的Block信 息发送给NameNode。Client就是需要获取分布式文件系统文件的应用程序。接下来通过三个具体的操作来说明HDFS对数据的管理。
(1)文件写入
1)Client向NameNode发起文件写入的请求。
2)NameNode根据文件大小和文件块配置情况,返回给Client所管理的DataNode的信息。
3)Client将文件划分为多个Block,根据DataNode的地址信息,按顺序将其写入到每一个DataNode块中。
(2)文件读取
1)Client向NameNode发起文件读取的请求。
2)NameNode返回文件存储的DataNode信息。
3)Client读取文件信息。
(3)文件块(Block)复制
1)NameNode发现部分文件的Block不符合最小复制数这一要求或部分DataNode失效。
2)通知DataNode相互复制Block。
3)DataNode开始直接相互复制。
作为分布式文件系统,HDFS在数据管理方面还有值得借鉴的几个功能:
- 文 件块(Block)的放置:一个Block会有三份备份,一份放在NameNode指定的DataNode上,另一份放在与指定DataNode不在同一 台机器上的DataNode上,最后一份放在与指定DataNode同一Rack的DataNode上。备份的目的是为了数据安全,采用这种配置方式主要 是考虑同一Rack失败的情况,以及不同Rack之间进行数据复制会带来的性能问题。
- 心跳检测:用心跳检测DataNode的健康状况,如果发现问题就采取数据备份的方式来保证数据的安全性。
- 数 据复制(场景为DataNode失败、需要平衡DataNode的存储利用率和平衡DataNode数据交互压力等情况):使用Hadoop时可以用 HDFS的balancer命令配置Threshold来平衡每一个DataNode的磁盘利用率。假设设置了Threshold为10%,那么执行 balancer命令时,首先会统计所有DataNode的磁盘利用率的平均值,然后判断如果某一个DataNode的磁盘利用率超过这个平均值,那么将 会把这个DataNode的Block转移到磁盘利用率低的DataNode上,这对于新节点的加入十分有用。
- 数据校验:采用CRC32做数据校验。在写入文件块的时候,除了会写入数据外还会写入校验信息,在读取的时候则需要先校验后读入。
- 单个NameNode:如果单个NameNode失败,任务处理信息将会记录在本地文件系统和远端的文件系统中。
- 数 据管道性的写入:当客户端要写入文件到DataNode上时,首先会读取一个Block,然后将其写到第一个DataNode上,接着由第一个 DataNode将其传递到备份的DataNode上,直到所有需要写入这个Block的DataNode都成功写入后,客户端才会开始写下一个 Block。
- 安全模式:分布式文件系统启动时会进入安全模式(系统运行期间也可以通过命令进入安全模式),当分布式文件系统处于安全模 式时,文件系统中的内容不允许修改也不允许删除,直到安全模式结束。安全模式主要是为了在系统启动的时候检查各个DataNode上数据块的有效性,同时 根据策略进行必要的复制或删除部分数据块。在实际操作过程中,如果在系统启动时修改和删除文件会出现安全模式不允许修改的错误提示,只需要等待一会儿即 可。
2 HBase的数据管理
HBase是一个类 似Bigtable的分布式数据库,它的大部分特性和Bigtable一样,是一个稀疏的、长期存储的(存在硬盘上)、多维度的排序映射表,这张表的索引 是行关键字、列关键字和时间戳。表中的每个值是一个纯字符数组,数据都是字符串,没有类型。用户在表格中存储数据,每一行都有一个可排序的主键和任意多的 列。由于是稀疏存储的,所以同一张表中的每一行数据都可以有截然不同的列。列名字的格式是 “<family>:<label>”,它是由字符串组成的,每一张表有一个family集合,这个集合是固定不变的,相当于表 的结构,只能通过改变表结构来改变表的family集合。但是label值相对于每一行来说都是可以改变的。
HBase把同一个 family中的数据存储在同一个目录下,而HBase的写操作是锁行的,每一行都是一个原子元素,都可以加锁。所有数据库的更新都有一个时间戳标记,每 次更新都会生成一个新的版本,而HBase会保留一定数量的版本,这个值是可以设定的。客户端可以选择获取距离某个时间点最近的版本,或者一次获取所有版 本。
以上从微观上介绍了HBase的一些数据管理措施。那么HBase作为分布式数据库在整体上从集群出发又是如何管理数据的呢?
HBase在分布式集群上主要依靠由HRegion、HMaster、HClient组成的体系结构从整体上管理数据。
HBase体系结构有三大重要组成部分:
- HBaseMaster:HBase主服务器,与Bigtable的主服务器类似。
- HRegionServer:HBase域服务器,与Bigtable的Tablet服务器类似。
- HBase Client:HBase客户端是由org.apache.hadoop.HBase.client.HTable定义的。
下面将对这三个组件进行详细的介绍。
(1)HBaseMaster
一个HBase只部署一台主服务器,它通过领导选举算法(Leader Election Algorithm)确保只有唯一的主服务器是活跃的,ZooKeeper保存主服务器的服务器地址信息。如果主服务器瘫痪,可以通过领导选举算法从备用服务器中选择新的主服务器。
主 服务器承担着初始化集群的任务。当主服务器第一次启动时,会试图从HDFS获取根或根域目录,如果获取失败则创建根或根域目录,以及第一个元域目录。在下 次启动时,主服务器就可以获取集群和集群中所有域的信息了。同时主服务器还负责集群中域的分配、域服务器运行状态的监视、表格的管理等工作。
(2)HRegionServer
HBase域服务器的主要职责有服务于主服务器分配的域、处理客户端的读写请求、本地缓冲区回写、本地数据压缩和分割域等功能。
每 个域只能由一台域服务器来提供服务。当它开始服务于某域时,它会从HDFS文件系统中读取该域的日志和所有存储文件,同时还会管理操作HDFS文件的持久 性存储工作。客户端通过与主服务器通信获取域和域所在域服务器的列表信息后,就可以直接向域服务器发送域读写请求,来完成操作。
(3)HBaseClient
HBase客户端负责查找用户域所在的域服务器地址。HBase客户端会与HBase主机交换消息以查找根域的位置,这是两者之间唯一的交流。
定 位根域后,客户端连接根域所在的域服务器,并扫描根域获取元域信息。元域信息中包含所需用户域的域服务器地址。客户端再连接元域所在的域服务器,扫描元域 以获取所需用户域所在的域服务器地址。定位用户域后,客户端连接用户域所在的域服务器并发出读写请求。用户域的地址将在客户端被缓存,后续的请求无须重复 上述过程。
综上所述,在HBase的体系结构中,HBase主要由主服务器、域服务器和客户端三部分组成。主服务器作为HBase的中心, 管理整个集群中的所有域,监控每台域服务器的运行情况等;域服务器接收来自服务器的分配域,处理客户端的域读写请求并回写映射文件等;客户端主要用来查找 用户域所在的域服务器地址信息。
3 Hive的数据管理
Hive 是建立在Hadoop上的数据仓库基础构架。它提供了一系列的工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的 大规模数据的机制。Hive定义了简单的类SQL的查询语言,称为Hive QL,它允许熟悉SQL的用户用SQL语言查询数据。作为一个数据仓库,Hive的数据管理按照使用层次可以从元数据存储、数据存储和数据交换三方面来介 绍。
(1)元数据存储
Hive将元数据存储在RDBMS中,有三种模式可以连接到数据库:
- Single User Mode:此模式连接到一个In-memory的数据库Derby,一般用于Unit Test。
- Multi User Mode:通过网络连接到一个数据库中,这是最常用的模式。
- Remote Server Mode:用于非Java客户端访问元数据库,在服务器端启动一个 MetaStoreServer,客户端利用Thrift协议通过 MetaStoreServer来访问元数据库。
(2)数据存储
首先,Hive没有专门的数据存储格式,也没有为数据建立索引,用户可以非常自由地组织Hive中的表,只需要在创建表的时候告诉Hive数据中的列分隔符和行分隔符,它就可以解析数据了。
其次,Hive中所有的数据都存储在HDFS中,Hive中包含4种数据模型:Table、External Table、Partition和Bucket。
Hive 中的Table和数据库中的Table在概念上是类似的,每一个Table在Hive中都有一个相应的目录来存储数据。例如,一个表pvs,它在HDFS 中的路径为:/wh/pvs,其中,wh是在hive-site.xml中由${hive.metastore.warehouse.dir}指定的数据 仓库的目录,所有的 Table数据(不包括External Table)都保存在这个目录中。
(3)数据交换
数据交换主要分为以下几部分,如图1所示。
- 用户接口:包括客户端、Web界面和数据库接口。
- 元数据存储:通常存储在关系数据库中,如MySQL、Derby等。
- 解释器、编译器、优化器、执行器。
- Hadoop:利用HDFS进行存储,利用MapReduce进行计算。
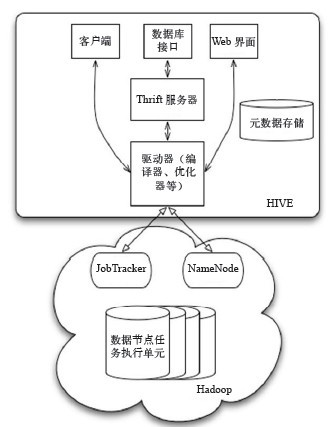
图1 Hive数据交换图
用 户接口主要有三个:客户端、数据库接口和Web界面,其中最常用的是客户端。Client是Hive的客户端,当启动Client模式时,用户会想要连接 Hive Server,这时需要指出 Hive Server所在的节点,并且在该节点启动HiveServer。Web界面是通过浏览器访问Hive的。
Hive将元数据存储在数据库中,如MySQL、Derby中。Hive 中的元数据包括表的名字、表的列、表的分区、表分区的属性、表的属性(是否为外部表等)、表的数据所在目录等。
解释器、编译器、优化器完成Hive QL查询语句从词法分析、语法分析、编译、优化到查询计划的生成。生成的查询计划存储在HDFS中,并且随后由MapReduce调用执行。
Hive的数据存储在HDFS中,大部分的查询由MapReduce完成(包含*的查询不会生成MapRedcue任务,比如select * from tbl)。
以上从Hadoop的分布式文件系统HDFS、分布式数据库HBase和数据仓库工具Hive入手介绍了Hadoop的数据管理,它们都通过自己的数据定义、体系结构实现了数据从宏观到微观的立体化管理,完成了Hadoop平台上大规模的数据存储和任务处理。
-----------------------------------------
 本文节选自《Hadoop实战(第2版)》一书。本书由陆嘉恒著,机械工业出版社出版。
本文节选自《Hadoop实战(第2版)》一书。本书由陆嘉恒著,机械工业出版社出版。
《Hadoop实战(第2版)》
陆嘉恒,资深数据库专家和云计算技术专家,对Hadoop及其相关技术有非常深入的研究,主持了多个分布式云计算项目的研究与实施,积累了丰富的实践经验。获得新加坡国立大学博士学位,美国加利福尼亚大学尔湾分校 (University of California, Irvine) 博士后,现为中国人民大学教授,博士生导师。此外,他对数据挖掘和Web信息搜索等技术也有深刻的认识。