一、Liunx环境准备
VMware+CentOS-7.6,
- 1.1下面是VMware和Centos的资源地址,也可以自己从网上下载相应的版本
百度网盘地址:链接:https://pan.baidu.com/s/1m_qvasgybY5rfJNHNjkqpw 提取码:9xka - 1.2安装Linux
- 1.3关闭Liunx防火墙
systemctl stop firewalld 关闭防火墙
systemctl disable firewalld 禁止开机启动
systemctl status firewalld 查看防火墙状态
- 1.4设置静态IP(并配置虚拟网络环境)
修改配置文件
[root@localhost ~]# vi /etc/sysconfig/network-scripts/ifcfg-ens33
改成以下模板
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=static # 修改
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ens33
UUID=79acf3f7-0d64-4244-b531-daffc9c8e771
DEVICE=ens33
ONBOOT=yes # 修改
# 新增
IPADDR=192.168.244.101
NETMASK=255.255.255.0
GATEWAY=192.168.244.2
DNS1=114.114.114.114
DNS2=8.8.8.8
重启网络服务
[root@localhost ~]# service network restart
- 1.5 安装常用工具
vim 编辑工具 yum -y install vim*
wget 云端下载 yum -y install wget
- 1.6 修改主机名
查看主机名
[root@localhost ~]# echo $HOSTNAME
修改主机名
[root@localhost ~]# vim /etc/sysconfig/network
增加以下内容,以后只需要更改 HOSTNAME 那一行
NETWORKING=yes
NETWORKING_IPV6=no
HOSTNAME=hdp-101
注意:主机名称中不能有“_”下划线
增加ip和主机的映射关系
[root@localhost ~]# vim /etc/hosts
增加以下内容
192.168.244.101 hdp-101
192.168.244.102 hdp-102
192.168.244.103 hdp-103
重启虚拟机(命令:reboot),主机名生效
测试 ping hdp-101
ping 通代表修改成功
- 1.7在/opt目录下创建两个文件夹module和software
[root@hdp-101 ~]# mkdir /opt/module /opt/sofaware
到此基础配置已完成,其他两台也要配置好,再开始下面的配置,要不然会找不到主机
二、Hadoop运行环境搭建
- 2.1安装jdk、Hadoop
进入到 /opt/sofaware/目录下
[root@hdp-101 ~]# cd /opt/sofaware/
[root@hdp-101 sofaware]# wget --no-cookies --no-check-certificate --header "Cookie: gpw_e24=http%3A%2F%2Fwww.oracle.com%2F; oraclelicense=accept-securebackup-cookie" "http://download.oracle.com/otn-pub/java/jdk/8u141-b15/336fa29ff2bb4ef291e347e091f7f4a7/jdk-8u141-linux-x64.tar.gz"
[root@hdp-101 sofaware]# wget http://mirrors.hust.edu.cn/apache/hadoop/core/hadoop-2.7.7/hadoop-2.7.7.tar.gz
[root@hdp-101 sofaware]# tar -zxvf jdk-8u144-linux-x64.tar.gz -C /opt/module/
[root@hdp-101 sofaware]# tar -zxvf hadoop-2.7.7.tar.gz -C /opt/module/
[root@hdp-101 sofaware]# cd /opt/moude/
配置环境变量
[root@hdp-101 sofaware]# sudo vi /etc/profile
在文件末尾添加jdk路径和hadoop路径
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_141
export PATH=$PATH:$JAVA_HOME/bin
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-2.7.7
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
保存、退出,让修改后的文件生效
[root@hdp-101 sofaware]# source /etc/profile
测试环境变量是否配置成功
[root@hdp-101 sofaware]# java -version
java version "1.8.0_141"
[root@hdp-101 sofaware]# hadoop version
Hadoop 2.7.7
- 2.2Hadoop目录结构
查看Hadoop目录结构
[root@hdp-101 ~]$ cd /opt/module/hadoop-2.7.7
[root@hdp-101 hadoop-2.7.7]# ll
总用量 52
drwxr-xr-x. 2 root root 4096 5月 22 2017 bin
drwxr-xr-x. 3 root root 4096 5月 22 2017 etc
drwxr-xr-x. 2 root root 4096 5月 22 2017 include
drwxr-xr-x. 3 root root 4096 5月 22 2017 lib
drwxr-xr-x. 2 root root 4096 5月 22 2017 libexec
-rw-r--r--. 1 root root 15429 5月 22 2017 LICENSE.txt
-rw-r--r--. 1 root root 101 5月 22 2017 NOTICE.txt
-rw-r--r--. 1 root root 1366 5月 22 2017 README.txt
drwxr-xr-x. 2 root root 4096 5月 22 2017 sbin
drwxr-xr-x. 4 root root 4096 5月 22 2017 share
重要目录
(1)bin目录:存放对Hadoop相关服务(HDFS,YARN)进行操作的脚本
(2)etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件
(3)lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能)
(4)sbin目录:存放启动或停止Hadoop相关服务的脚本
(5)share目录:存放Hadoop的依赖jar包、文档、和官方案例
三、Hadoop运行模式
- 3.1开始配置Hadoop
[root@hdp-102 hadoop-2.7.7]# cd etc/hadoop/
配置:hadoop-env.sh
vim hadoop-env.sh
修改JAVA_HOME 路径:
export JAVA_HOME=/opt/module/jdk1.8.0_141
配置core-site.xml
vim core-site.xml
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hdp-101:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.7/data/tmp</value>
</property>
配置hdfs-site.xml
vim hdfs-site.xml
<!-- 指定HDFS副本的数量 单一节点至多设置一个副本-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 指定Hadoop辅助名称节点主机配置 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hdp-102:50090</value>
</property>
四、配置YARN
- 4.1配置YARN
(a)配置yarn-env.sh
vim yarn-env.sh
找到以下
# export JAVA_HOME=/home/y/libexec/jdk1.6.0/
取消注释并配置一下JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_141
(b)配置yarn-site.xml
vim yarn-site.xml
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hdp-103</value>
</property>
<!-- 日志聚集功能使能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间设置7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
(c)配置:mapred-env.sh
vim mapred-env.sh
配置一下JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_141
(d)配置: (对mapred-site.xml.template重新命名为) mapred-site.xml
[root@hdp-101 hadoop]$ mv mapred-site.xml.template mapred-site.xml
[root@hdp-101 hadoop]$ vim mapred-site.xml
<!-- 指定MR运行在YARN上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hdp-101:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hdp-101:19888</value>
</property>
五、配置SSH免密登录
- 5.1生成公钥和私钥
[root@hdp-101 ~]# ssh-keygen -t rsa
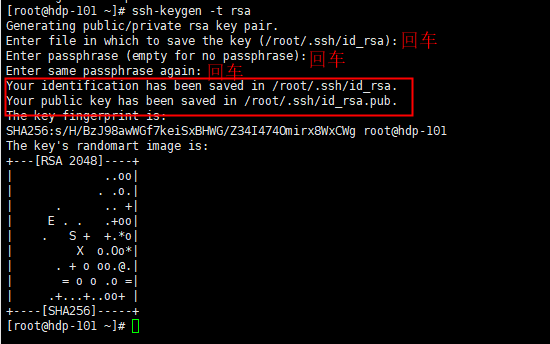
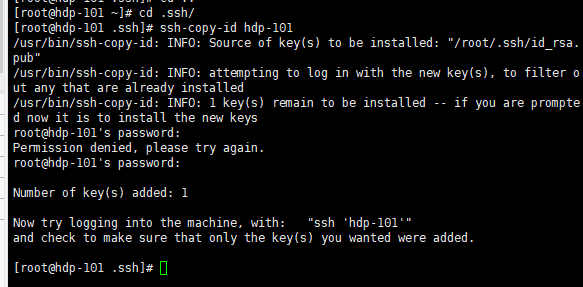
- 5.2将公钥拷贝到要免密登录的目标机器上
[root@hdp-101 ~]# cd .ssh/
[root@hdp-101 .ssh]# ssh-copy-id hdp-101
[root@hdp-101 .ssh]# ssh-copy-id hdp-102
[root@hdp-101 .ssh]# ssh-copy-id hdp-103
六、群起集群
- 6.1配置slaves
/opt/module/hadoop-2.7.7/etc/hadoop/slaves
[root@hdp-101 hadoop]# vim slaves
在该文件中增加如下内容:
hdp-101
hdp-102
hdp-103
注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
- 6.2 同步所有节点配置
安装rsync远程同步工具,其他机器上也要安装rsync,不然无法执行
yum install rsync -y
rsync -av /opt/module/ hdp-101:/opt/module/
rsync -av /opt/module/ hdp-102:/opt/module/
复制配置文件
rsync -av /etc/profile hdp-101:/etc/profile
rsync -av /etc/profile hdp-102:/etc/profile
在相应的主机上使配置文件生效
source /etc/profile
- 6.3启动集群
(a)如果集群是第一次启动,需要格式化NameNode(注意格式化之前,一定要先停止上次启动的所有namenode和datanode进程,然后再删除data和log数据)
[root@hdp-101 hadoop-2.7.7]# bin/hdfs namenode -format
(b))启动HDFS http://hdp-101:50070/dfshealth.html#tab-datanode
在windows上访问需要做ip和网址的配置,在C:WindowsSystem32driversetchosts上添加
192.168.160.101 hdp-101
也可以直接用ip请求 http://192.168.160.101:50070/dfshealth.html#tab-datanode
[root@hdp-101 hadoop-2.7.7]# sbin/start-dfs.sh
[root@hdp-101 hadoop-2.7.7]# jps
4166 NameNode
4482 Jps
4263 DataNode

(c)启动YARN http://hdp-103:8088/cluster/nodes
[root@hadoop103 hadoop-2.7.7]# sbin/start-yarn.sh
注意:NameNode和ResourceManger如果不是同一台机器,不能在NameNode上启动 YARN,应该在ResouceManager所在的机器上启动YARN。
(d)启动历史服务器 http://hdp-101:19888/jobhistory
[root@hdp-101 hadoop-2.7.7]# sbin/mr-jobhistory-daemon.sh start historyserver
[root@hdp-101 hadoop-2.7.7]# jps
七、集群启动/停止方式总结
- 7.1各个服务组件逐一启动/停止
分别启动/停止HDFS组件
hadoop-daemon.sh start / stop namenode / datanode / secondarynamenode
启动/停止YARN
yarn-daemon.sh start / stop resourcemanager / nodemanager
- 7.2各个模块分开启动/停止
整体启动/停止HDFS
start-dfs.sh / stop-dfs.sh
整体启动/停止YARN
start-yarn.sh / stop-yarn.sh
八、HDFS常见命令
创建一个文件夹 hdfs dfs -mkdir /myTask
创建多个文件夹 hdfs dfs -mkdir -p /myTask1/input1
上传文件 hdfs dfs -put /opt/wordcount.txt /myTask/input
查看总目录下的文件和文件夹 hdfs dfs -ls /
查看myTask下的文件和文件夹 hdfs dfs -ls /myTask
查看myTask下的wordcount.txt的内容 hdfs dfs -cat /myTask/wordcount.txt
删除总目录下的myTask2文件夹以及里面的文件和文件夹 hdfs dfs -rmr /myTask2
删除myTask下的wordcount.txt hdfs dfs -rmr /myTask/wordcount.txt
下载hdfs中myTask/input/wordcount.txt到本地opt文件夹中 hdfs dfs -get /myTask/input/wordcount.txt /opt