通过Fiddler分析抖音app网络请求 抓取热搜视频
Filler使用方法这里不再赘述,可查看我的“爬虫”专题相关文章。
抖音热搜视频抓取很简单,分三部分:
- 热搜列表->提取热搜词语
- 热搜子列表->提取视频url
- 热搜视频url->视频下载
热搜列表get_hot_list()获取,通过永久url获取改列表,包含了热词等信息
热搜子列表get_word_detail()获取,通过热词及永久链接获取视频url
抓取结果:
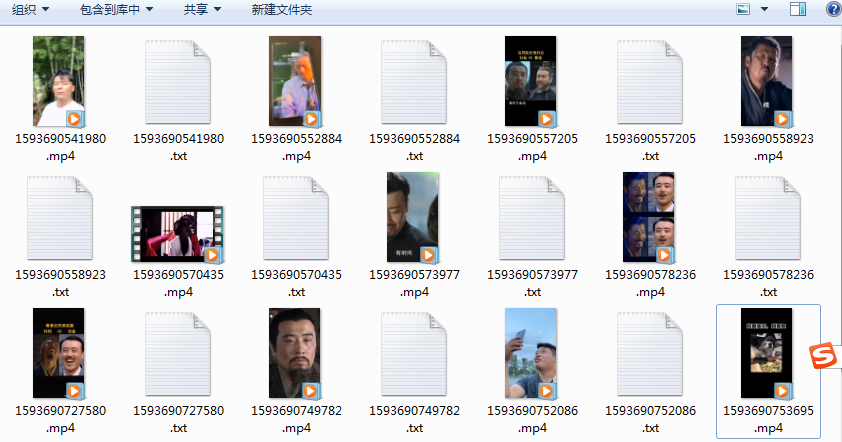
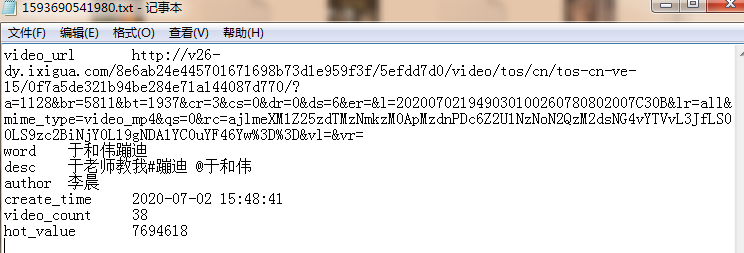
抓取主要内容:
视频、关键词、描述、作者、创建时间
完整代码如下:
import os
import requests
import pprint
import jmespath
import time
from furl import furl
this_dir = os.path.dirname(os.path.abspath(__file__))
def get_hot_list():
url = 'https://api3-normal-c-hl.amemv.com/aweme/v1/hot/search/list/?detail_list=1&mac_address=A0%3A86%3AC6%3AA8%3ADB%3A5D&source=0¤t_word&words_in_panel=+&trend_entry_word&os_api=23&device_type=MI%204LTE&ssmix=a&manifest_version_code=110502&dpi=480&uuid=865931028491629&app_name=aweme&version_name=11.5.1&ts=1593505161&cpu_support64=false&app_type=normal&ac=wifi&host_abi=armeabi-v7a&update_version_code=11519900&channel=xiaomi&_rticket=1593505161669&device_platform=android&iid=1363049466040444&version_code=110501&mac_address=A0%3A86%3AC6%3AA8%3ADB%3A5D&cdid=5d857c06-4ded-46c0-9380-ccd777da3256&openudid=db5e62a9bcba313f&device_id=34634747427&resolution=1080*1920&os_version=6.0.1&language=zh&device_brand=Xiaomi&aid=1128'
res = requests.get(url)
item = res.json()
# pprint.pprint(item)
dlist = jmespath.search('data.word_list',item)
return dlist
def get_word_detail(word):
url = 'https://api3-normal-c-hl.amemv.com/aweme/v1/hot/search/video/list/?offset=0&count=50&source=trending_page&is_ad=0&item_id_list&is_trending=0&city_code&related_gids&os_api=23&device_type=MI%204LTE&ssmix=a&manifest_version_code=110502&dpi=480&uuid=865931028491629&app_name=aweme&version_name=11.5.1&ts=1593505798&cpu_support64=false&app_type=normal&ac=wifi&host_abi=armeabi-v7a&update_version_code=11519900&channel=xiaomi&_rticket=1593505800138&device_platform=android&iid=1363049466040444&version_code=110501&mac_address=A0%3A86%3AC6%3AA8%3ADB%3A5D&cdid=5d857c06-4ded-46c0-9380-ccd777da3256&openudid=db5e62a9bcba313f&device_id=34634747427&resolution=1080*1920&os_version=6.0.1&language=zh&device_brand=Xiaomi&aid=1128'
url+='&hotword='+word
data = requests.get(url)
data = data.json()
res = []
for item in data['aweme_list']:
tmp = {}
tmp['video_url'] = jmespath.search('video.play_addr.url_list[0]',item)
tmp['word'] = word
tmp['desc'] = jmespath.search('desc', item)
tmp['author'] = jmespath.search('author.nickname', item)
ctime = jmespath.search('create_time', item)
try:
ctime = time.localtime(ctime)
tmp['create_time'] = time.strftime("%Y-%m-%d %H:%M:%S", ctime)
except Exception as e:
pass
res.append(tmp)
# pprint.pprint(res)
return res
def save_data(dlist,item):
for tmp in dlist:
name = str(int(time.time()*1000))
print('save--',tmp['word'])
tmp.update({'video_count':item.get('video_count',''),'hot_value':item.get('hot_value','')})
try:
save_text(tmp,name)
save_video(tmp['video_url'], name)
except Exception as e:
print('save error:',e)
def save_text(item,name):
with open(os.path.join(this_dir,'data',name+'.txt'),'w',encoding='utf-8') as f:
for key,value in item.items():
f.write(key+' '+str(value)+'
')
def save_video(url,name):
res = requests.get(url)
content = res.content
f = furl(url)
mime_type = f.args['mime_type']
if mime_type:
suffix = mime_type.split('_')[-1]
with open(os.path.join(this_dir,'data',name+'.'+suffix),'wb') as f:
f.write(content)
if __name__ == '__main__':
hot_list = get_hot_list()
for item in hot_list[1:]:
dlist = get_word_detail(item['word'])
save_data(dlist,item)