核心概念
Columnar Data Store
Kudu is a columnar data store. A columnar data store stores data in strongly-typed columns. With a proper design, it is superior for analytical or data warehousing workloads for several reasons.
- 强语法性质的表,每列都严格进行类型定义,所以每列都是一样的数据类型,方便数据的压缩和统一处理
- 通过适当的设计,kudu在分析或数仓方面具比较出众
Read Efficiency
For analytical queries, you can read a single column, or a portion of that column, while ignoring other columns. This means you can fulfill your query while reading a minimal number of blocks on disk.
With a row-based store, you need to read the entire row, even if you only return values from a few columns.
列式存储,读取的时候,只针对需要的列进行读取,也可以读取列的一部分数据。这样,你可以读取更小的磁盘块数据就可以完成查询任务。可以做到减少磁盘和网络I/O的消耗。
基于行的存储模式,你需要将整行加载到内存,即使你只是需要使用到行中很少的列。
Data Compression
Because a given column contains only one type of data, pattern-based compression can be orders of magnitude more efficient than compressing mixed data types, which are used in row-based solutions. Combined with the efficiencies of reading data from columns, compression allows you to fulfill your query while reading even fewer blocks from disk
- 由于每一列都仅是一种类型的数据
- 基于模式的压缩比压缩混合数据类型的效率高出几个数量级
- 不同的列可以根据不同类型的特点采用不同的压缩方式
Table
A table is where your data is stored in Kudu. A table has a schema and a totally ordered primary key. A table is split into segments called tablets.
- kudu的表都拥有一个全排序的主键
- 每个表都被切分成多个segment,也被称为tablet
Tablet
A tablet is a contiguous segment of a table, similar to a partition in other data storage engines or relational databases. A given tablet is replicated on multiple tablet servers, and at any given point in time, one of these replicas is considered the leader tablet. Any replica can service reads, and writes require consensus(一致性) among the set of tablet servers serving the tablet.
架构构成
Tablet Server
A tablet server stores and serves tablets to clients. For a given tablet, one tablet server acts as a leader, and the others act as follower replicas of that tablet. Only leaders service write requests, while leaders or followers each service read requests. Leaders are elected using Raft Consensus Algorithm. One tablet server can serve multiple tablets, and one tablet can be served by multiple tablet servers.
Tablet Server就是启动的服务器,一个tablet的leader通过raft选举算法选择一个tablet server。一个table的所有tablet的对应的leaders,均衡分布在集群中,当然replica也是均衡分配在集群中。
Master Server
The master keeps track of all the tablets, tablet servers, the Catalog Table, and other metadata related to the cluster. At a given point in time, there can only be one acting master (the leader). If the current leader disappears, a new master is elected using Raft Consensus Algorithm.
The master also coordinates metadata operations for clients. For example, when creating a new table, the client internally sends the request to the master. The master writes the metadata for the new table into the catalog table, and coordinates the process of creating tablets on the tablet servers.
All the master’s data is stored in a tablet, which can be replicated to all the other candidate masters. 所有的master数据存储在一个tablet中,master的tablet会复制给候选的master
Tablet servers heartbeat to the master at a set interval (the default is once per second). Master也可以是leader和follower的形式。
Catalog Table
The catalog table is the central location for metadata of Kudu.
It stores information about tables and tablets. The catalog table may not be read or written directly. Instead, it is accessible only via metadata operations exposed in the client API.
Catalog Table 是Kudu的核心元数据存放的地方,包含了哪些tables以及每个table对应的tablets信息,不能够被直接的访问和改写,只能通过Kudu提供的api来实现,
The catalog table stores two categories of metadata:
1)Tables : table schemas, locations, and states
2)Tablets : the list of existing tablets, which tablet servers have replicas of each tablet, the tablet’s current state, and start and end keys.
tablets的列表,每个tablet在哪个server上,副本在哪个server上,状态,开始key和结束key等等。
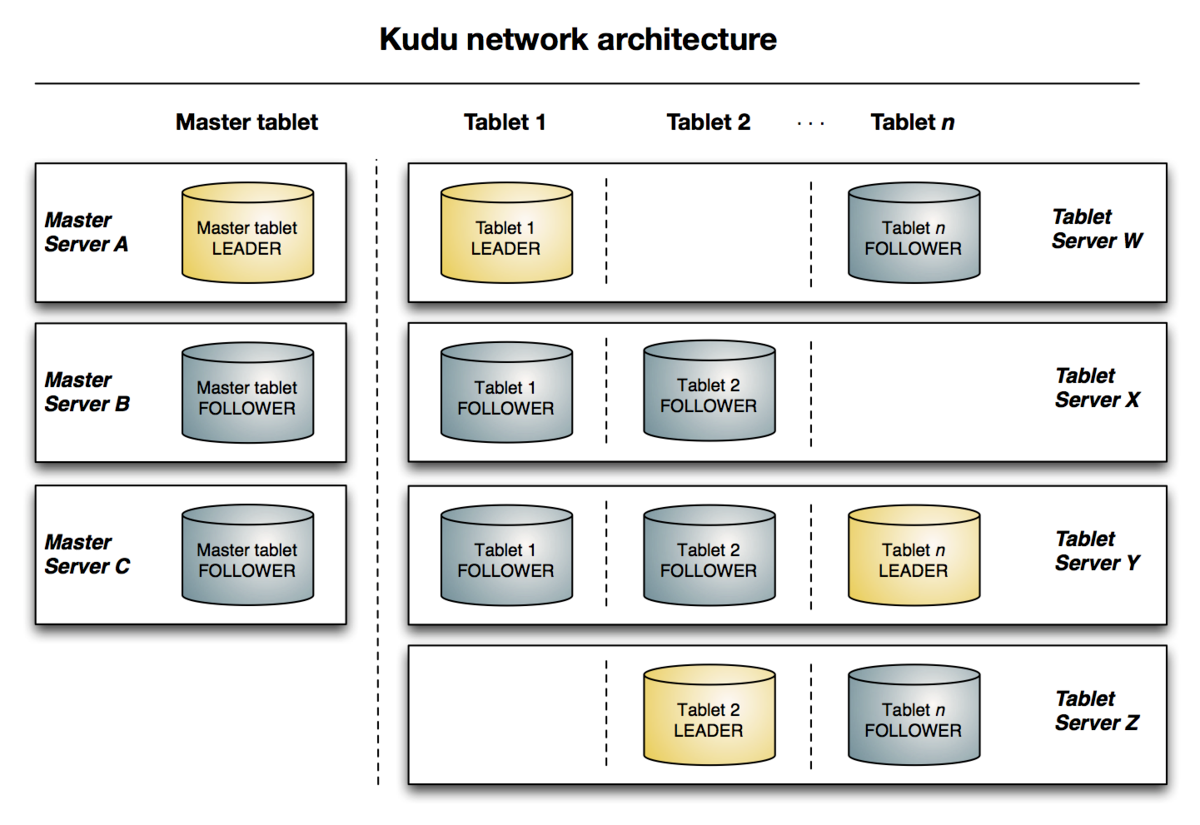
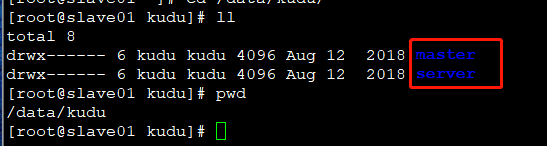
从图上可以看到,master中也有tablet,只不过不能够直接被访问而已。从kudu部署的服务器集群中可以明显看到。
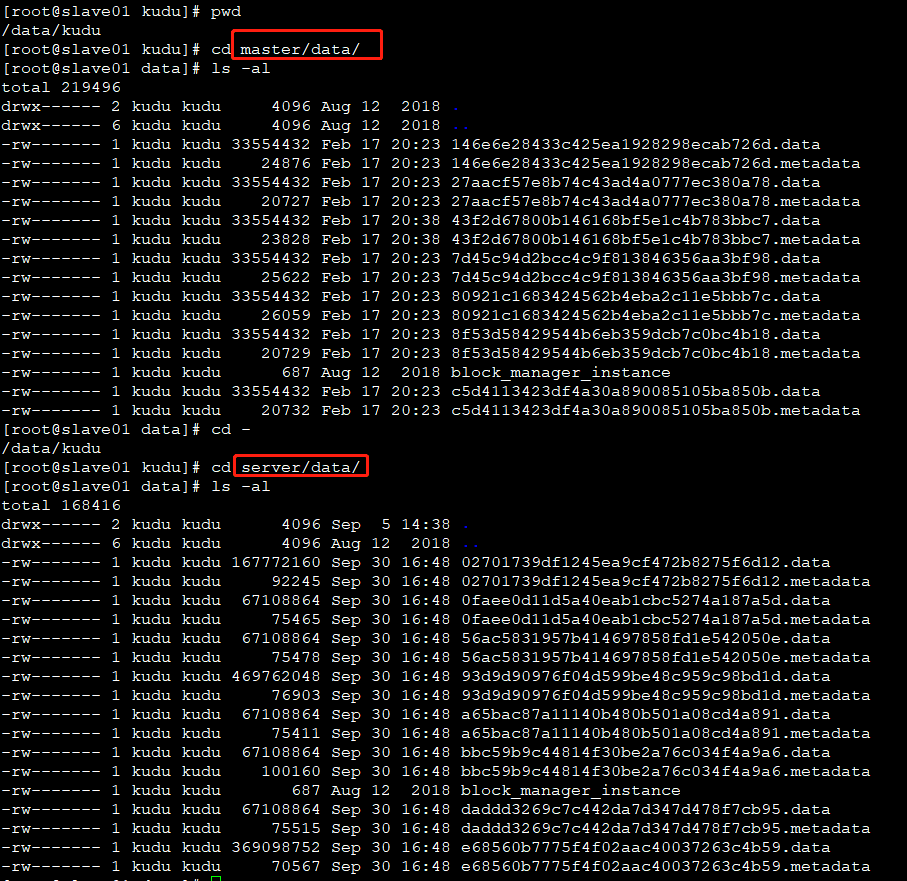
从图中可以看到,这台机器即使server又是master,并且server和master两个目录下,都有自己的data数据,即tablet数据,如下图
架构与设计
1.基本框架
Kudu是用于存储结构化(structured)的表(Table)。表有预定义的带类型的列(Columns),每张表有一个主键(primary key)。主键带有唯一性(uniqueness)限制,可作为索引用来支持快速的random access。
类似于BigTable,Kudu的表是由很多数据子集构成的,表被水平拆分成多个Tablets. Kudu用以每个tablet为一个单元来实现数据的durability。Tablet有多个副本,同时在多个节点上进行持久化。
Kudu有两种类型的组件,Master Server和Tablet Server。Master负责管理元数据。这些元数据包括talbet的基本信息,位置信息。Master还作为负载均衡服务器,监听Tablet Server的健康状态。对于副本数过低的Tablet,Master会在起replication任务来提高其副本数。Master的所有信息都在内存中cache,因此速度非常快。每次查询都在百毫秒级别。Kudu支持多个Master,不过只有一个active Master,其余只是作为灾备,不提供服务。
Tablet Server上存了10~100个Tablets,每个Tablet有3(或5)个副本存放在不同的Tablet Server上,每个Tablet同时只有一个leader副本,这个副本对用户提供修改操作,然后将修改结果同步给follower。Follower只提供读服务,不提供修改服务。副本之间使用raft协议来实现High Availability,当leader所在的节点发生故障时,followers会重新选举leader。根据官方的数据,其MTTR约为5秒,对client端几乎没有影响。Raft协议的另一个作用是实现Consistency。Client对leader的修改操作,需要同步到N/2+1个节点上,该操作才算成功。

Kudu采用了类似log-structured存储系统的方式,增删改 操作都放在内存中的buffer,然后才merge到持久化的列式存储中。Kudu还是用了WALs来对内存中的buffer进行灾备。
2.列式存储
持久化的列式存储,与HBase完全不同,而是使用了类似Parquet的方式,同一个列在磁盘上是作为一个连续的块进行存放的。例如,图中左边是twitter保存推文的一张表,而图中的右边表示了表在磁盘中的的存储方式,也就是将同一个列放在一起存放。
这样做的第一个好处是,对于一些聚合和join语句,我们可以尽可能地减少磁盘的访问。
例如,我们要用户名为 newsycbot 的推文数量,使用查询语句:
SELECT COUNT(*) FROM tweets WHERE user_name = ‘newsycbot’;

我们只需要查询User_name这个block即可。同一个列的数据是集中的,而且是相同格式的,Kudu可以对数据进行编码,例如字典编码,行长编码,bitshuffle等。通过这种方式可以很大的减少数据在磁盘上的大小,提高吞吐率。除此之外,用户可以选择使用通用的压缩格式对数据进行压缩,如LZ4, gzip, 或bzip2。这是可选的,用户可以根据业务场景,在数据大小和CPU效率上进行权衡。这一部分的实现上,Kudu很大部分借鉴了Parquet的代码。
HBase支持snappy存储,然而因为它的LSM的数据存储方式,使得它很难对数据进行特殊编码,这也是Kudu声称具有很快的scan速度的一个很重要的原因。不过,因为列式编码后的数据很难再进行修改,因此当这写数据写入磁盘后,是不可变的,这部分数据称之为base数据。
kudu用MVCC(多版本并发控制)来实现数据的删改功能。更新、删除操作需要记录到特殊的数据结构里,保存在内存中的DeltaMemStore或磁盘上的DeltaFIle里面。DeltaMemStore是B-Tree实现的,因此速度快,而且可修改。磁盘上的DeltaFIle是二进制的列式的块,和base数据一样都是不可修改的。因此当数据频繁删改的时候,磁盘上会有大量的DeltaFiles文件,Kudu借鉴了Hbase的方式,会定期对这些文件进行合并。
参考连接: