1、Handler介绍
- netty的组件设计:Netty的主要组件有
Channel、EventLoop、ChannelFuture、ChannelHandler、ChannelPipe等 - 我们先来复习一下
ChannelHandler和ChannelPipeline的关系。示例图如下:我们可以将pipeline理解为一个双向链表,ChannelHandlerContext看作链表中的一个节点,ChannelHandler则为每个节点中保存的一个属性对象。

ChannelHandler充当了处理入站和出站数据的应用程序逻辑的容器。例如,实现ChannelInboundHandler接口(或ChannelInboundHandlerAdapter),你就可以接收入站事件和数据,这些数据会被业务逻辑处理。当要给客户端发送响应时,也可以从ChannelInboundHandler冲刷数据。业务逻辑通常写在一个或者多个ChannelInboundHandler中。ChannelOutboundHandler原理一样,只不过它是用来处理出站数据的ChannelPipeline提供了ChannelHandler链的容器。以客户端应用程序为例,如果事件的运动方向是从客户端到服务端的,那么我们称这些事件为出站的,即客户端发送给服务端的数据会通过pipeline中的一系列ChannelOutboundHandler,并被这些Handler处理,反之则称为入站的- 简单来说,以服务器端为例:接受数据的过程就是入站,发送数据的过程就是出站。客户端也一样。
- 下面,来看看我们常用的
Handler的关系图:Inbound处理入站,Outbound处理出站

- 一般来说,在我们接收数据时将数据解码后,就进行业务的相关处理,所以上图的入站的常用类更多。在数据出站时,一般我们只需要将数据编码后直接发出。
2、Handler链式调用
我们知道,Pipeline中的Handler可以当作一个双向链表。但是,Handler却又存在着入站和出站之分。那么Netty是如何将两种类型的Handler保存在一个链表中,却又能够入站的时候调用InboundHandler,出栈的时候调用OutBoundHandler呢?看下图,黄色的表示入站,以及入站的Handler,绿色的表示出站,以及出站的Handler。
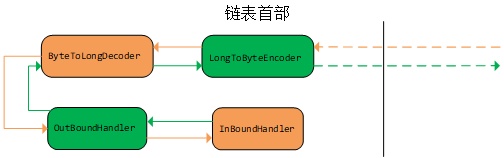
当我们调用如下代码时,我们就会获得一个上图所示的Handler链表。下面代码时在ChannelInitializer类中添加Handler的部分代码。
@Override
protected void initChannel(SocketChannel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
pipeline.addLast(new LongToByteEncoder()); //out
pipeline.addLast(new ByteToLongDecoder()); //in
pipeline.addLast(new OutBoundHandler()); //out
pipeline.addLast(new InBoundHandler()); //in
}
当一个请求来了的时候,首先会将请求发给pipeline中位于链表首部的Handler。如图所示,首先由LongToByteEncoder(这个东西不管,就是个出站的)接受到入站请求,但是这个东西是个OutBound。所以它收到入站请求时就不做处理,直接转发给它的下一个ByteToLongDecoder(这个东西也不管,它是入站的)。这个东西接受到了入站请求了,一看它自己也是一个Inbound,所以它就将请求的数据进行处理,然后转发给下一个。之后又是一个Outbound,然后再进行转发,到了最后的InBoundHandler,在这里我们可以进行业务的处理等等操作。
然后如果需要返回数据,我们就调用ctx.writeAndFlush方法(注意和ctx.channel().writeAndFlush有区别),这个方法可不简单,当他一调用,就会触发出站的请求,然后就由当前所在的Handler节点往回调用。往回调用的途中,如果遇到InBound就直接转发给下一个Handler,直到最后将消息返回。
举例:netty服务端是这个添加顺序
ch.pipeline().addLast(new InboundHandler1());
ch.pipeline().addLast(new InboundHandler2());
ch.pipeline().addLast(new OutboundHandler1());
ch.pipeline().addLast(new OutboundHandler2());
链表中的顺序为head->in1->in2->out1->out2->tail
1、如果在InboundHandler2中执行的是ctx.channel().writeAndFlush,执行顺序是:
InboundHandler1
InboundHandler2
OutboundHandler2
OutboundHandler1
结果证明:执行完InboundHandler1、InboundHandler2之后,由于InboundHandler2中执行的是ctx.channel().writeAndFlush,它会直接从tail开始往前找Outbound执行,链表中的顺序为head->in1->in2->out1->out2->tail,所以会执行out2,再执行out1
2、如果在InboundHandler2中执行的是ctx.writeAndFlush,执行顺序是:
InboundHandler1
InboundHandler2
结果证明,由于OutboundHandler1与OutboundHandler2的add在InboundHandler2之后,而InboundHandler2中执行的是ctx.writeAndFlush,它会从当前InboundHandler2的位置,往前找Outbound执行,根据链表中的顺序为head->in1->in2->out1->out2->tail,in2之前已经无Outbound,所以不会再有Outbound会执行
上面两个已经能说明问题,为了方便对netty的handler执行不是太熟悉的读者理解,再举个例子:
ch.pipeline().addLast(new OutboundHandler1());
ch.pipeline().addLast(new OutboundHandler2());
ch.pipeline().addLast(new InboundHandler1());
ch.pipeline().addLast(new InboundHandler2());
链表中的顺序为head->out1->out2->in1->in2->tail
1、如果在InboundHandler2中执行的是ctx.channel().writeAndFlush,执行顺序是:
InboundHandler1
InboundHandler2
OutboundHandler2
OutboundHandler1
结果证明,执行完InboundHandler2后,由于InboundHandler2中执行的是ctx.channel().writeAndFlush,它会从tail往前找Outbound执行,而链表中的顺序为head->out1->out2->in1->in2->tail,所以会继续执行到out2、out1
2、如果在InboundHandler2中执行的是ctx.writeAndFlush,执行顺序是:
InboundHandler1
InboundHandler2
OutboundHandler2
OutboundHandler1
结果证明,执行完InboundHandler2后,由于InboundHandler2中执行的是ctx.writeAndFlush,它会从InboundHandler2位置往前找Outbound执行,而链表中的顺序为head->out1->out2->in1->in2->tail,所以会继续执行到out2、out1
通过上面的描述,我们可以总结添加Handler的以下节点总结:
- 调用
InboundHandler的顺序和添加的顺序是一致的。 - 调用
OutboundHandler的顺序和添加它的顺序是相反的。 ctx.writeAndFlush只会从当前的handler位置开始,往前找outbound执行ctx.pipeline().writeAndFlush与ctx.channel().writeAndFlush会从tail的位置开始,往前找outbound执行
3、Handler编解码器
- 当Netty发送或者接受一个消息的时候,就将会发生一次数据转换。入站消息会被解码:从字节转换为另一种格式(比如java对象);如果是出站消息,它会被编码成字节。
- Netty提供一系列实用的编解码器,他们都实现了ChannelInboundHadnler或者ChannelOutboundHandler接口。在这些类中,channelRead方法已经被重写了。以入站为例,对于每个从入站Channel读取的消息,这个方法会被调用。随后,它将调用由解码器所提供的decode()方法进行解码,并将已经解码的字节转发给ChannelPipeline中的下一个ChannelInboundHandler。
解码器-ByteToMessageDecoder
-
由于不可能知道远程节点是否会一次性发送一个完整的信息,tcp有可能出现粘包拆包的问题,这个类会对入站数据进行缓冲,直到它准备好被处理。
-
下面是段示例代码:
public class ToIntegerDecoder extends ByteToMessageDecoder { @Override protected void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception { if (in.readableBytes() >= 4) { out.add(in.readInt()); } } }- 这个例子,每次入站从
ByteBuf中读取4字节,将其解码为一个int,然后将它添加到下一个List中。当没有更多元素可以被添加到该List中时,它的内容将会被发送给下一个ChannelInboundHandler。int在被添加到List中时,会被自动装箱为Integer。在调用readInt()方法前必须验证所输入的ByteBuf是否具有足够的数据

- 这个例子,每次入站从
解码器-ReplayingDecoder
-
public abstract class ReplayingDecoder extends ByteToMessageDecoder{ } -
ReplayingDecoder扩展了ByteToMessageDecoder类,使用这个类,我们不必调用readableBytes()方法。参数S指定了用户状态管理的类型,其中Void代表不需要状态管理 -
下面是代码示例:这段代码起到了上面
ByteToMessageDecoder一样的作用public class ByteToLongDecoder2 extends ReplayingDecoder<Void> { @Override protected void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception { out.add(in.readLong()); } } -
ReplayingDecoder使用方便,但它也有一些局限性:- 并不是所有的
ByteBuf操作都被支持,如果调用了一个不被支持的方法,将会抛出一个UnsupportedOperationException。 ReplayingDecoder在某些情况下可能稍慢于ByteToMessageDecoder,例如网络缓慢并且消息格式复杂时,消息会被拆成了多个碎片,速度变慢
- 并不是所有的
其他解码器
LineBasedFrameDecoder:这个类在Netty内部也有使用,它使用行尾控制字符( 或者 )作为分隔符来解析数据。DelimiterBasedFrameDecoder:使用自定义的特殊字符作为消息的分隔符。HttpObjectDecoder:一个HTTP数据的解码器LengthFieldBasedFrameDecoder:通过指定长度来标识整包消息,这样就可以自动的处理黏包和半包消息。
4、简单实例
实例要求
- 使用自定义的编码器和解码器来说明Netty的handler 调用机制
- 客户端发送long -> 服务器
- 服务端发送long -> 客户端
实例代码
这里只展示,Handler相应的代码和添加Handler的关键代码。
Decoder:
public class ByteToLongDecoder extends ByteToMessageDecoder {
/**
* decode 方法会根据接收到的数据,被调用多次,知道确定没有新的元素被添加到list,或者是ByteBuf 没有更多的可读字节为止
* 如果 list out不为空,就会将list的内容传递给下一个 Handler 进行处理,该处理器的方法也会被调用多次。
* @param ctx 上下文对象
* @param in 入栈的 ByteBuf
* @param out list集合,将解码后的数据传给下一个Handler
* @throws Exception
*/
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {
//因为long为8个字节,所以需要8个字节才能读取成一个long类型的数据
System.out.println("ByteToLongDecoder:入栈数据被解码");
if (in.readableBytes() >= 8){
out.add(in.readLong());
}
}
}
Encoder:
public class LongToByteEncoder extends MessageToByteEncoder<Long> {
@Override
protected void encode(ChannelHandlerContext ctx, Long msg, ByteBuf out) throws Exception {
System.out.println("LongToByteEncoder: 出栈数据,msg = " + msg);
out.writeLong(msg);
}
}
服务端添加Handler:
@Override
protected void initChannel(SocketChannel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
pipeline.addLast(new LongToByteEncoder()); //编码器,出站
pipeline.addLast(new ByteToLongDecoder()); //解码器,入站
pipeline.addLast(new ServerInBoundHandler()); //业务处理,入站
}
客户端添加Handler:
@Override
protected void initChannel(SocketChannel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
pipeline.addLast(new LongToByteEncoder()); //编码器,出站
pipeline.addLast(new ByteToLongDecoder()); //解码器,入站
pipeline.addLast(new ClientInBoundHandler()); //业务处理,入站。
}
这里当客户端或者服务端接受消息的时候,首先会调用入站的解码器,然后业务处理,然后调用出站的编码器返回消息。后面可以在业务处理类中,增加发送消息的代码,此处省略。
5、Log4j整合到Netty
添加依赖
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.25</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.25</version>
</dependency>
添加配置文件:
在resource目录下新建log4j.properties即可
log4j.rootLogger=DEBUG, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=[%p] %C{1} - %m%n
原文链接:https://blog.csdn.net/qq_35751014/article/details/104548228
本文在原文的基础上添加一些笔记和个人的理解