在设计分布式系统时,通常要考虑到 数据的一致性(consistency)、系统的可用性(availability)、以及分区容忍性( partition tolerance)。即CAP定理。
概念
我们知道,分布式系统有多个节点。
数据一致性是指, 对每个节点,在同一时刻,读写的数据是相同的。
举例:用户User1的账户余额是100,在节点Node1我们更改了User1的账户余额,改成了200,此时在节点Node1读User1余额一定是200。如果保证了一致性,那么
在节点Node2、Node3等其他节点,读到User1的余额都是200。
系统的可用性:即使分布式系统中的一个节点挂掉了,对于请求,依然能够响应。
分区容忍性:即使系统中出现了 一个节点与其他节点无法通信的情况,系统依然能够工作。
举例:分布式系统中两节点间无法传递数据或数据丢失,此时这个分布式系统依然可以工作。
通过了解以上概念,我们知道,分区容忍性是要保证的。当系统中的出现节点Node1和Node2无法同步数据的情况时,数据一致性和可用性是无法同时保证的,需要
有取舍。
保证数据的一致性以及分区容忍性(CP):所有节点数据一致,当 出现 一个节点与其他节点失去联系,此时系统服务不可用。
保证系统的可用性以及分区容忍性(AP):即便出现一个节点与其他节点无法通信的情况,该节点也提供服务,此时不保证改节点的数据与其他节点的数据一致;
当该节点可以通信时,同步数据。
举例
假设我们的服务是博客系统。
最初系统服务的访问量并不大,单个服务节点足以支撑。
随着用户数量的发展,单个节点支撑不住了,于是考虑做水平扩展。我们的服务节点由一个扩展到了两个,并且,每个服务节点都保存一份数据。由于我们有两个服务
节点,所以在这两个节点前,增加了Load Balancer用于做调度,如图1
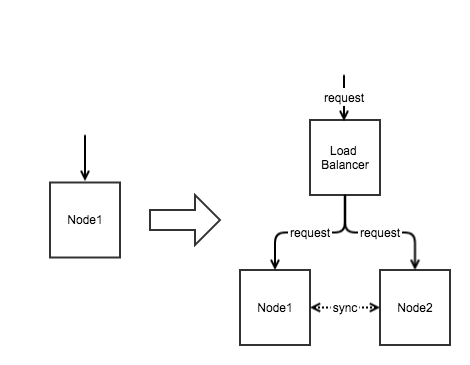
图1
对于读请求不做描述。
对于写请求,过程如下
1. 请求到达Load Balancer
2. Load Balancer做判断,将请求分配给某一个节点,如Node1
3. Node1执行写操作。如果此时返回处理结果给客户端,那么 假如有相同的请求,但是落到了Node2时,数据时不一致的,所以我们要做数据同步。我们先做
一个假设,数据同步一定成功且耗时很短很短。
我们可以有两种方式同步。
第一种,直到Node2的数据同步了,Node1才返回。第二种,Node1执行同步数据操作,不等待同步完成,立即返回结果。
现在假设Node1和Node2的通信断开了,如图2
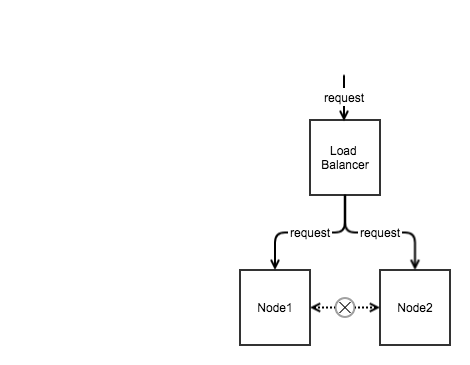
图2
无论以上哪种同步方式都行不通,那么我们要做出抉择,是要保证数据的一致性好,还是保证可用性。因为我们的服务是博客服务,即便数据暂时性地不一致也是可以
忍受的,并且,如果长时间用户得不到内容会导致用户流失,所以我们倾向保证可用性。即 修改第三部处理,当Node1和Node2的通信断开时,暂时不做数据同步,
直接返回结果。
这种处理方式,当通信断开时,Node1和Node2的数据在处理写请求后是不一致的。
现在假设Node1和Node2的数据同步过程会耗时会很长。我们依旧倾向保证可用性。因为第一种同步方法会让用户等待较长的时间,我们采用第二种同步方法。
第二种方法,会保证经过一段时间后,数据是一致的。这是所谓的最终一致性。
下面,我们再考虑这样的问题,依旧假设Node1和Node2的数据同步过程会耗时很长。来了一个写请求,Load balancer将其分配给了Node1;很快又来了一个写请求,Load Balancer将其分配给了Node2。此时数据该怎么同步呢?假如修改的都是同一个文章ID所对应的内容呢?
可以考虑将Node1 和 Node2 的同步请求加入到一个公共的队列中。即 节点在进行写操作后,将同步操作加入到公共队列中,然后 节点返回结果给用户。
我们可以实时地消费这个队列,也可以定时地消费这个队列。
消费这个队列时,将数据写到Node1和Node2中,如图3
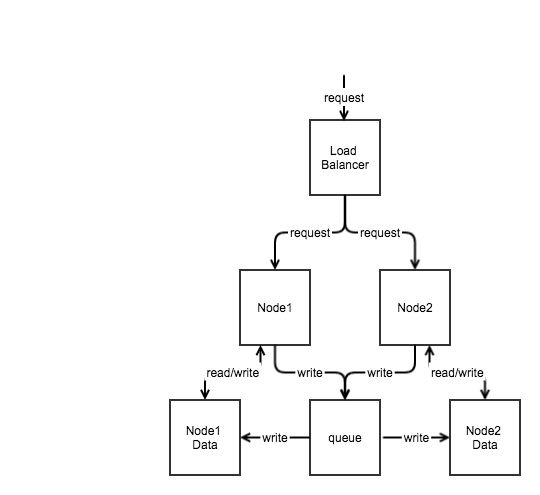
图3
这个方案依旧不够好,因为多写了一次数据。
假如写数据的操作很耗时,为了避免多写一次,我们也可以在Node1和Node2上设置缓存(偏向可用性),即写时 不写数据而是写缓存。但设置缓存又会引发Node1
与Node2缓存不一致的情况发生(需要处理数据一致性)。
好了,偏向可用性的讨论先到此为止。
假设我们做的系统不是博客系统,是交易系统。
我们的系统需要的是强一致性。即无论从Node1还是Node2读写数据,得到的结果都是一样的。因为是交易系统,所以需要做到的是数据是强一致性的,即每时每刻
数据一致。
假设写请求到了Node1,此时Node1需要写数据并将数据同步到Node2。假如Node1与Node2的通信断开了,那么我们应该给用户返回一个请等待的页面。此时数据既没有
写入Node1也没有写入Node2。
假如通信没断开的话,怎样保证写入了Node1数据,也会写入Node2数据呢?
可以使用两段提交的算法。两段提交需要 一个协调者,比如Node3,而所有待更新节点数据作为参与者。
第一阶段,请求阶段:协调者Node3 请求 Node1和Node2是否对User1的账户进行更新,参与者Node1 回复可以更新,参与者Node2 回复不可以更新(比如正在有
读操作)
第二阶段,提交阶段:只有所有参与者都同意才会提交事务。Node3根据Node1和Node2的回复,做出是否提交事务的判断,不提交。
欢迎拍砖