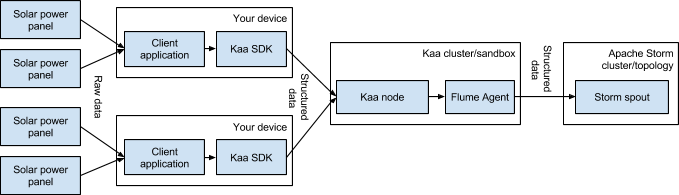
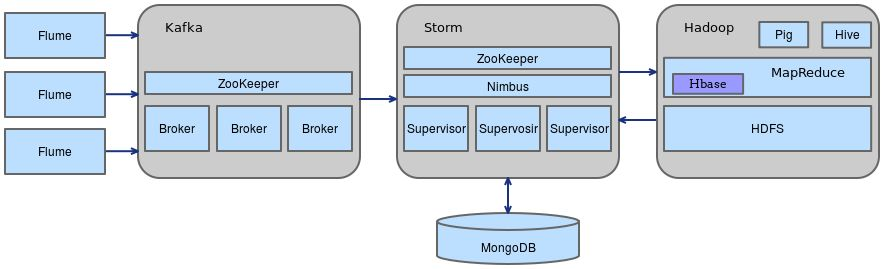
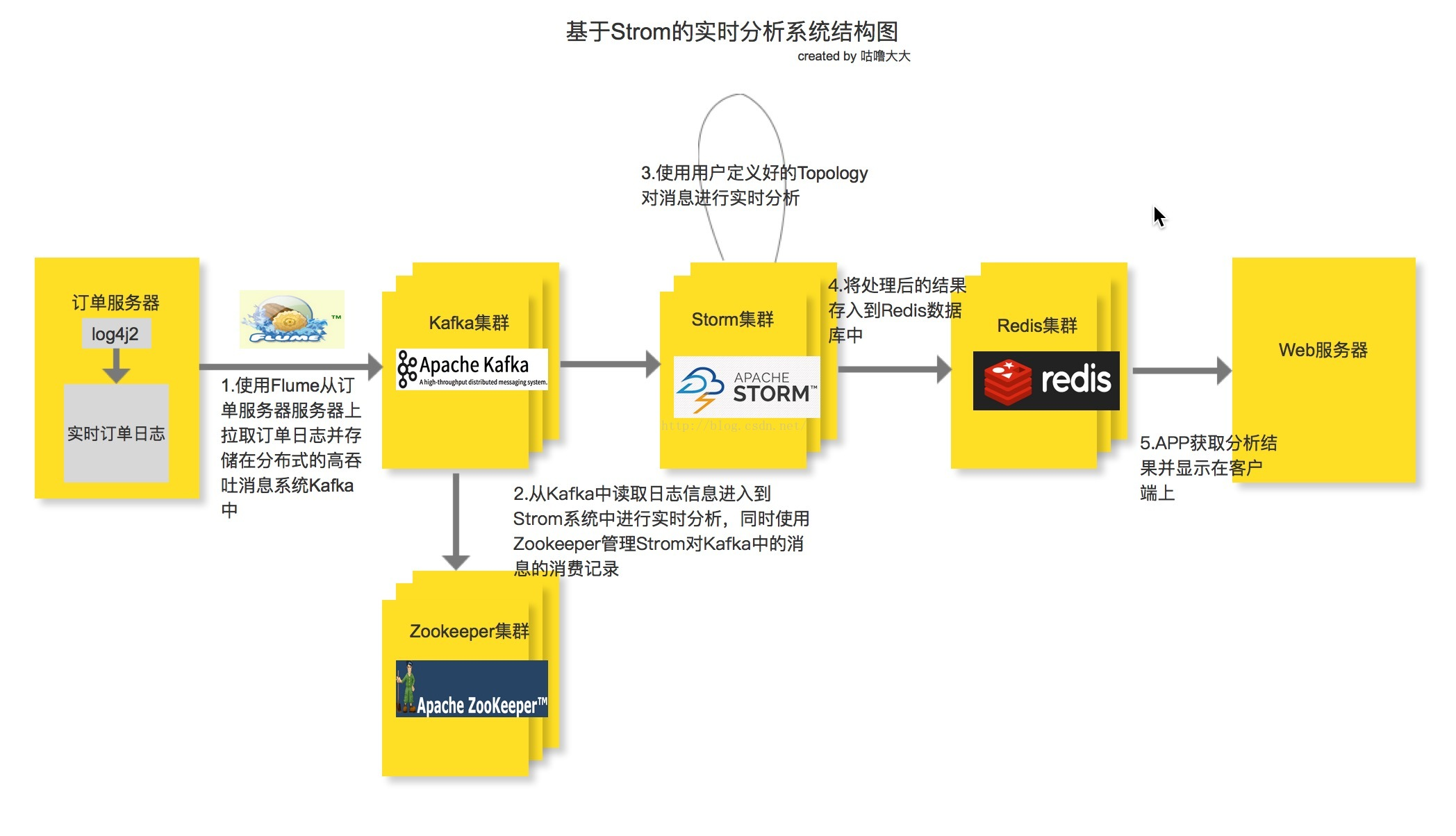
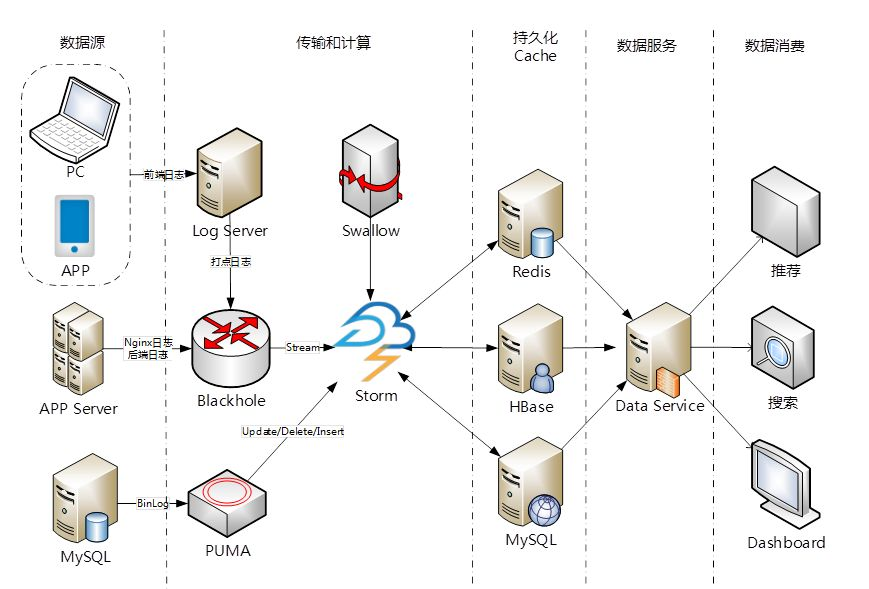
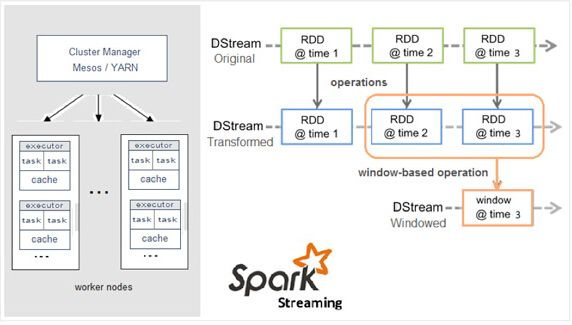
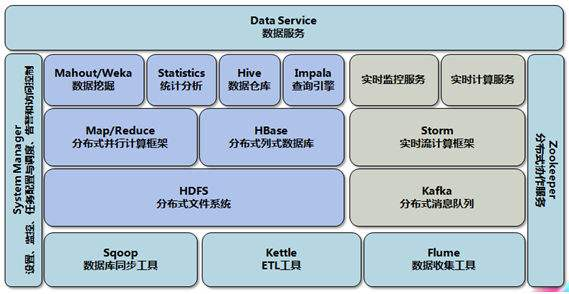
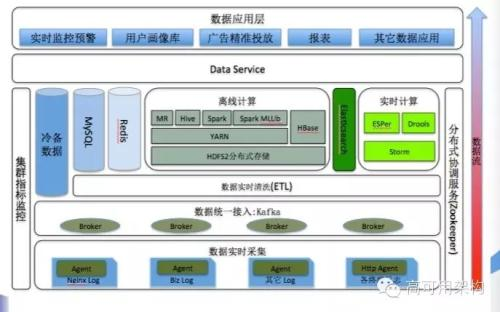
Data Collections ---> Stream to Channel (as source input) ----> Parallel Computing---> Results (as source ouput) -----> To DB ( Presentation)
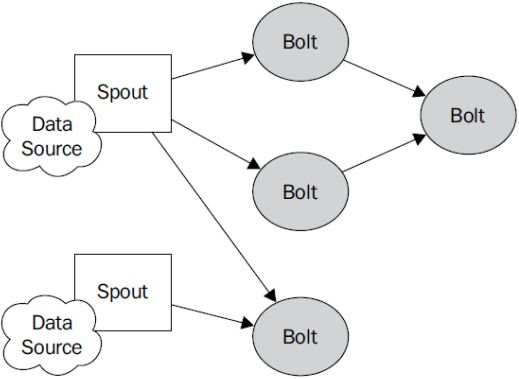
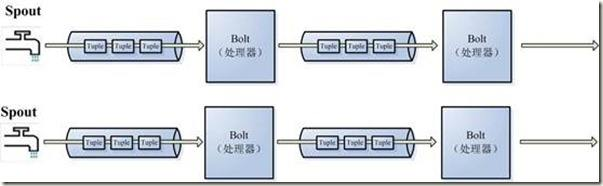
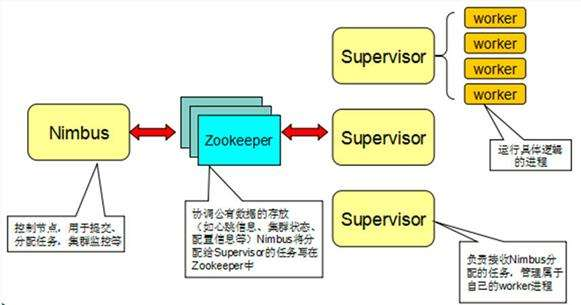
ISpout is the core interface for implementing spouts. A Spout is responsible for feeding messages into the topology for processing. For every tuple emitted by a spout, Storm will track the (potentially very large) DAG of tuples generated based on a tuple emitted by the spout. When Storm detects that every tuple in that DAG has been successfully processed, it will send an ack message to the Spout.
An IBolt represents a component that takes tuples as input and produces tuples as output. An IBolt can do everything from filtering to joining to functions to aggregations. It does not have to process a tuple immediately and may hold onto tuples to process later
The tuple is the main data structure in Storm. A tuple is a named list of values, where each value can be any type. Tuples are dynamically typed -- the types of the fields do not need to be declared. Tuples have helper methods like getInteger and getString to get field values without having to cast the result. Storm needs to know how to serialize all the values in a tuple. By default, Storm knows how to serialize the primitive types, strings, and byte arrays. If you want to use another type, you'll need to implement and register a serializer for that type.
Integration With External Systems, and Other Libraries
- Apache Kafka Integration, New Kafka Consumer Integration
- Apache HBase Integration
- Apache HDFS Integration
- Apache Hive Integration
- Apache Solr Integration
- Apache Cassandra Integration
- Apache RocketMQ Integration
- JDBC Integration
- JMS Integration
- MQTT Integration
- Redis Integration
- Event Hubs Intergration
- Elasticsearch Integration
- Mongodb Integration
- OpenTSDB Integration
- Kinesis Integration
- Druid Integration
- PMML Integration
- Kestrel Integration