最近笔者在学习数据分析时看到一篇关于数据分析思维的总结,在此记录一下关于指数方法的总结
指数法还可分为线性加权与Log方式,通过这两种方式我们可以将一组差异巨大的数组划分在一个很小的范围,且具有较好的参考价值。
例如:当拿到一组关于全国美食的数据,其中包括省份,城市,店铺类型,店铺名称,评价数量,客单价,口味评分,环境评分,服务质量评分这几个维度。
如下图我将其中的一部分数据拿出来用做后续的数据分析
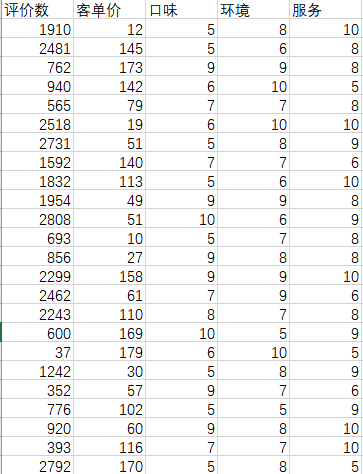
现在要分析店铺的热度,这时候我可能要从评价数量这个维度确定。因为评价数量多才能证明这个店铺客流量大。
但是从中可以发现评价数量差异巨大,最多的又几千,最少的有几十个甚至几个,这就在一定程度上没有办法确定热度的范围。
我们可能需要通过Log方式将参数进行收敛
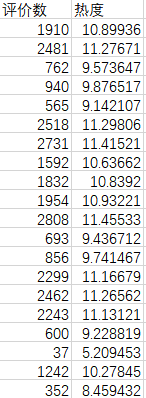
以上是将评价数量通过以10为底log求出的收敛值,可以和评价数量对比出具有更可观的参照性。
其中热度值也在预期内,评价数量越少的店铺,热度越低,评价数量越多的店铺数热度越高。
现在需要将口味、环境和服务综合起来生成一个综合指标来查看店铺的情况,这时候需要用到线性加权的方法。
方式是将三者加起来然后除以三。在这里我觉得口味和服务更重要一些,我可以在口味的参数中乘以一定权重。

上图中综合评分我将口味乘以1.6的权重加上环境再加上服务乘以1.4的权重得到的最终值。
得到的综合评分和预期的效果相似,一些口味和服务评分较高但环境分不算太出色店铺的综合评分并不会得到令人乍舌的低分。而一些口味和服务评分较低但环境分较高的店铺中,综合评分并不是太理想。
现想将综合评分、热度与客单价整合成一个推荐指数。其中,用户群体都想要物美价廉的商品,所以客单价在这里应该是个降权参数。
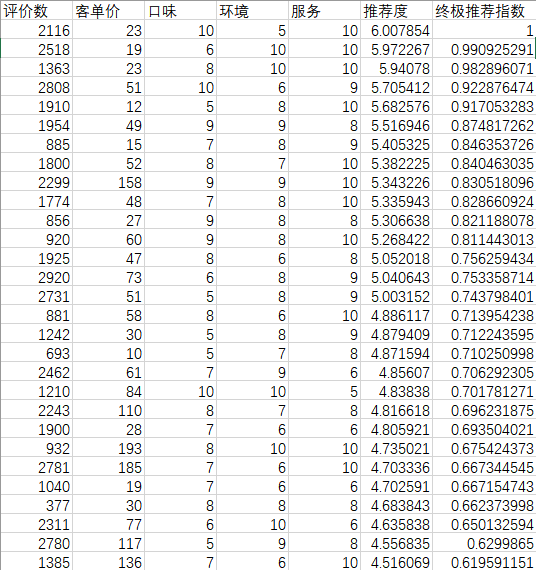
上图中,我将客单价参数进行收敛,随后把综合评分和热度相加再减去客单指数得出推荐度。然后用统计方法(推荐度-MIN(推荐度))/(MAX(推荐度)-MIN(推荐度))后拿到最终推荐指数。
可以看出和我预测的效果一样,排在首位的客单价并不高,而且评价数量很多。虽然环境只有五分,但是口味和服务都是十分。这里明显的验证了之前的加权效果。
在这个小案例中,不仅了解到线性加权和Log收敛的方法,更从一些杂乱无章的大数据中得到了显而易见的数据参考价值,能让我在数据分析过程中更容易地分析出问题所在。