此次实验是在Kaggle上微软发起的一个恶意软件分类的比赛,
数据集
此次微软提供的数据集超过500G(解压后),共9类恶意软件,如下图所示。这次实验参考了此次比赛的冠军队伍实现方法。微软提供的数据包括训练集、测试集和训练集的标注。其中每个恶意代码样本(去除了PE头)包含两个文件,一个是十六进制表示的.bytes文件,另一个是利用IDA反汇编工具生成的.asm文件。下载解压后如下所示:
每个asm文件内容大致如下:
随机抽样
由于机器性能以及存储空间的限制,本次实验限制了数据集的规模,采用原数据集中大概1/10左右的训练子集。其中从每个分类的中都随机抽取了100个样本(9个分类,每个样本2个文件,共1800个文件),这样也不需要用到pypy xgboost,只需要用到numpy,pandas、PIL和`scikit-learn这些库即可。以下是随机抽样代码:
import os
from random import *
import pandas as pd
import shutil
rs = Random()
rs.seed(1)
trainlabels = pd.read_csv('D:\chrom下载\malware-classification\subtrainLabels.csv')
fids = []
opd = pd.DataFrame()
for clabel in range (1,10):
mids = trainlabels[trainlabels.Class == clabel]
mids = mids.reset_index(drop=True)
rchoice = [rs.randint(0,len(mids)-1) for i in range(150)]
print(rchoice)
# for i in rchoice:
# fids.append(mids.loc[i].Id)
# opd = opd.append(mids.loc[i])
rids = [mids.loc[i].Id for i in rchoice]
fids.extend(rids)
opd = opd.append(mids.loc[rchoice])
opd = opd.reset_index(drop=True)
print(opd)
opd.to_csv('D:\chrom下载\malware-classification\sub_subtrainLabels.csv', encoding='utf-8', index=False)
sbase = 'E:\malware_class\subtrain\'
tbase = 'E:\malware_class\sub_subtrain\'
for fid in fids:
fnames = ['{0}.asm'.format(fid),'{0}.bytes'.format(fid)]
for fname in fnames:
cspath = sbase + fname
ctpath = tbase + fname
print(cspath)
shutil.copy(cspath,ctpath)
抽样完成后是2966个文件,对应1483个不同的恶意软件,对应1483个标签,标签如下

左为Id,右边是该Id软件对应的Class。
特征提取
n-gram特征
本次实验用到的第一个特征为n-gram。
假设有一个m 个词组成的句子,那么这个句子出现的概率为 。那么
为了简化计算当前这个词仅仅跟前面的n个词相关,*因此也就不必追溯到最开始的那个词,这样便可以大幅缩减上述算式的长度*。这个n就是n-gram中的n。在本次实验中,n取3.以下是特征提取的代码
import re
from collections import *
import os
import pandas as pd
def getOpcodeSequence(filename): #获取操作码序列
opcode_seq = []
p = re.compile(r's([a-fA-F0-9]{2}s)+s*([a-z]+)')
with open(filename,mode="r",encoding='utf-8',errors='ignore') as f:
for line in f:
if line.startswith(".text"):
m = re.findall(p,line)
if m:
opc = m[0][1]
if opc != "align":
opcode_seq.append(opc)
return opcode_seq
def getOpcodeNgram(ops, n=3): #将操作码序列以3个操作码为单位切片,并统计各个单位序列
opngramlist = [tuple(ops[i:i+n]) for i in range(len(ops)-n)]
opngram = Counter(opngramlist)
return opngram
basepath = "E:\malware_class\subtrain\"
map3gram = defaultdict(Counter)
subtrain = pd.read_csv('E:\malware_class\subtrain_label.csv')
count = 1
for sid in subtrain.Id: #获取每个文件的n-gram特征并存入map3gram中
print ("counting the 3-gram of the {0} file...".format(str(count)))
count += 1
filename = basepath + sid + ".asm"
ops = getOpcodeSequence(filename)
op3gram = getOpcodeNgram(ops)
map3gram[sid] = op3gram
cc = Counter([]) #获取总的n-gram特征,计算其出现的次数,将出现次数大于500的
for d in map3gram.values(): #单位存入selectedfeatures中用于后面的处理
print(d)
cc += d
selectedfeatures = {}
tc = 0
for k,v in cc.items():
if v >= 500:
selectedfeatures[k] = v
print (k,v)
tc += 1
dataframelist = []
for fid,op3gram in map3gram.items(): #每个文件的n-gram特征为dataframelist中的一行,每一列为各单位出现的次数
standard = {}
standard["Id"] = fid
for feature in selectedfeatures:
if feature in op3gram:
standard[feature] = op3gram[feature]
else:
standard[feature] = 0
dataframelist.append(standard)
df = pd.DataFrame(dataframelist)
df.to_csv("E:\malware_class\3gramfeature.csv",index=False)
最终得出的的结果如下
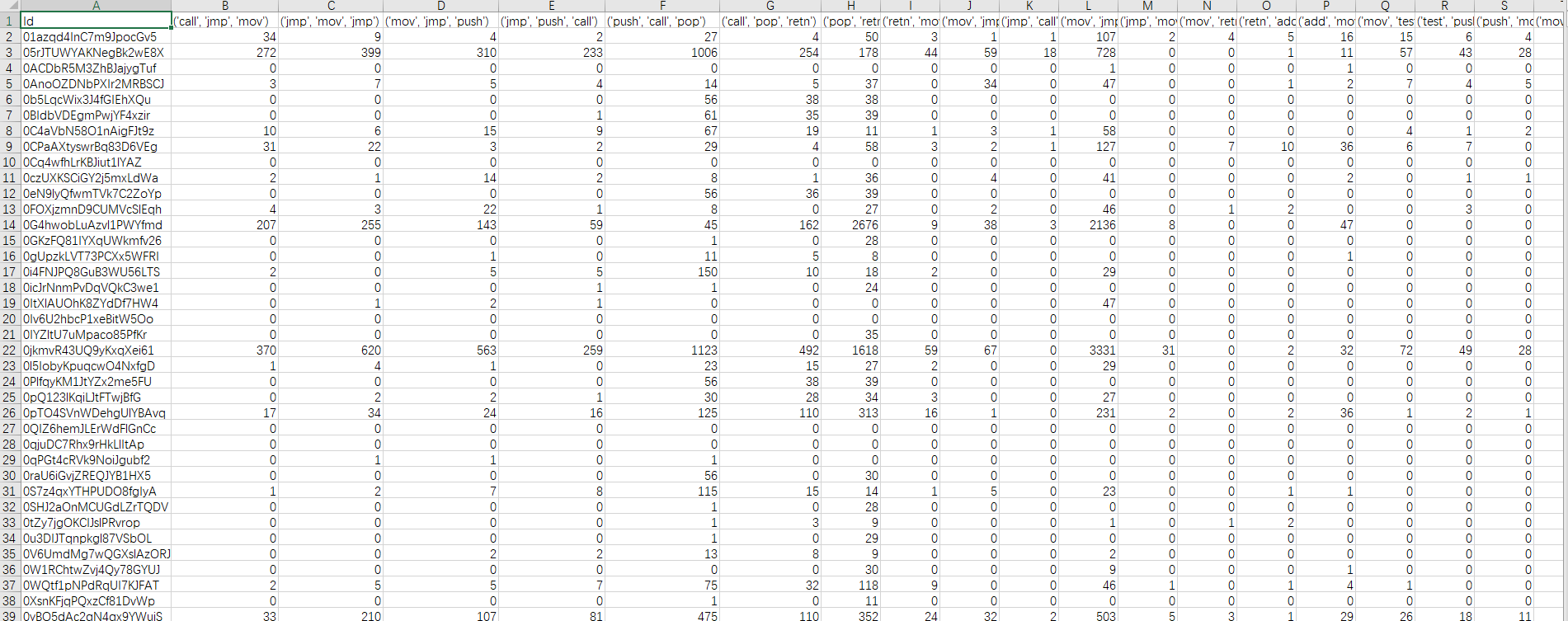
这就是这1483个软件的n-gram特征。特征表是一个1483*2730的表。接下来只要将特征输入算法就行了。本次实验所用的算法为随机森林算法。采用10交叉验证。
from sklearn.ensemble import RandomForestClassifier as RF
from sklearn.model_selection import cross_val_score
from sklearn.metrics import confusion_matrix
import pandas as pd
subtrainLabel = pd.read_csv('E:\malware_class\subtrain_label.csv')
subtrainfeature = pd.read_csv("E:\malware_class\3gramfeature.csv")
subtrain = pd.merge(subtrainLabel,subtrainfeature,on='Id')
labels = subtrain.Class
subtrain.drop(["Class","Id"], axis=1, inplace=True)
subtrain = subtrain.iloc[:,:].values
srf = RF(n_estimators=500, n_jobs=-1)
clf_s = cross_val_score(srf, subtrain, labels, cv=10)
print(clf_s)
得出的准确度如下
array([0.95302013, 0.95302013, 0.94630872, 0.94594595, 0.98648649,
0.95945946, 0.97297297, 0.93918919, 0.94594595, 0.95945946])
在未调参的情况下。最高0.98648649,最低0.93918919。
img特征
提取asm文件的前5000个字节,转化为python中的图像矩阵作为每个软件的特征。特征提取代码如下:
import os
import numpy
from collections import *
import pandas as pd
import binascii
def getMatrixfrom_asm(filename, startindex = 0, pixnum = 5000):
with open(filename, 'rb') as f:
f.s(startindex, 0)
content = f.read(pixnum)
hexst = binascii.hexlify(content)
fh = numpy.array([int(hexst[i:i+2],16) for i in range(0, len(hexst), 2)])
fh = numpy.uint8(fh)
return fh
basepath = "E:\malware_class\subtrain\"
mapimg = defaultdict(list)
subtrain = pd.read_csv('E:\malware_class\subtrain_label.csv')
i = 0
for sid in subtrain.Id:
i += 1
print ("dealing with {0}th file...".format(str(i)))
filename = basepath + sid + ".asm"
im = getMatrixfrom_asm(filename, startindex = 0, pixnum = 1500)
mapimg[sid] = im
dataframelist = []
for sid,imf in mapimg.items():
standard = {}
standard["Id"] = sid
for index,value in enumerate(imf):
colName = "pix{0}".format(str(index))
standard[colName] = value
dataframelist.append(standard)
df = pd.DataFrame(dataframelist)
df.to_csv("E:\malware_class\imgfeature.csv",index=False)
提取后的特征表如下图所示:
随机森林训练代码同上,最终结果如下
array([0.95302013, 0.94630872, 0.96644295, 0.95945946, 0.98648649,
0.93918919, 0.93243243, 0.9527027 , 0.97297297, 0.96621622])
特征结合
将n-gram特征和img特征结合起来,一起作为特征输入算法中,代码如下:
from sklearn.ensemble import RandomForestClassifier as RF
from sklearn.model_selection import cross_val_score
from sklearn.metrics import confusion_matrix
import pandas as pd
import numpy as np
subtrainLabel = pd.read_csv('E:\malware_class\subtrain_label.csv')
subtrainfeature1 = pd.read_csv("E:\malware_class\3gramfeature.csv")
subtrainfeature2 = pd.read_csv("E:\malware_class\imgfeature.csv")
subtrain = pd.merge(subtrainfeature1,subtrainfeature2,on='Id')
labels = subtrain.Class
subtrain.drop(["Class","Id"], axis=1, inplace=True)
subtrain = subtrain.iloc[:,:].values
srf = RF(n_estimators=500, n_jobs=-1)
clf_s = cross_val_score(srf, subtrain, labels, cv=10)
最终结果如下
array([0.99328859, 0.97986577, 0.98657718, 0.97297297, 0.99324324,0.98648649, 0.99324324, 0.98648649, 0.99324324, 0.99324324])
总结
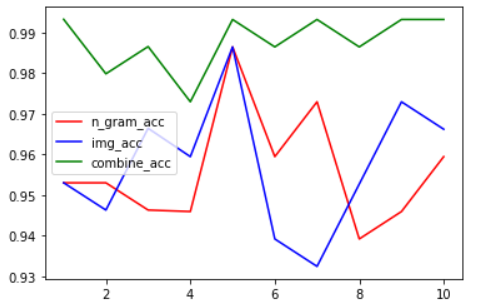
三次实验准确度汇总如下:
n-gram
n-gram
array([0.95302013, 0.95302013, 0.94630872, 0.94594595, 0.98648649,0.95945946, 0.97297297, 0.93918919, 0.94594595, 0.95945946])
img
array([0.95302013, 0.94630872, 0.96644295, 0.95945946, 0.98648649,0.93918919, 0.93243243, 0.9527027 , 0.97297297, 0.96621622])
结合
array([0.99328859, 0.97986577, 0.98657718, 0.97297297, 0.99324324,0.98648649, 0.99324324, 0.98648649, 0.99324324, 0.99324324])
绘图如下