导读:本文通过一个Netty的一个issue来学习什么是 "http request smuggling"、它产生的原因与解决方法,从而对http协议有进一步了解。
前言
前阵子在Netty的issue里有人提了一个问题 http request smuggling, cause by obfuscating TE header ,描述了一个Netty的http解码器一直以来都存在的问题:没有正确地分割http header field名称,可能导致被骇客利用。
引起问题的那段code很简单,它的作用是从一个字符串中分割出header field-name:
for (nameEnd = nameStart; nameEnd < length; nameEnd ++) { char ch = sb.charAt(nameEnd); if (ch == ':' || Character.isWhitespace(ch)) { break; } }
这段有什么问题呢?它不应该把空格也当成header field-name的终止符,这会导致Transfer-Encoding[空格]: chunked 被解析为Transfer-Encoding 而不是Transfer-Encoding[空格] 。
乍一看可能让很多人迷惑,一个Header Field名称识别错了为什么会被骇客攻击呢?大不了就缺了一个Header嘛。但真实世界,却没这么简单。这事,还得从现代的web服务架构说起。
起因
链式处理
通常现代的Web服务器并非单体存在的,而是由一系列的程序组成(比如nginx -> tomcat),为了实现均衡负载、请求路由、缓存等等功能。这些系统都会解析HTTP协议来进行一系列处理,处理完后,会将对应的请求分发链路中的下一个(往往也是通过HTTP协议)。
假设现在一个用户的请求到达逻辑服务器B的过程为: 用户 -> A -> B 。通常会有许多个用户连接到A,而为了减少连接建立的消耗,A到B的连接数会少很多,A与B之间会保持稳定的长连接,这样能够使性能得到提升。所以可能属于不同客户端的多个请求会共用同一个连接。(以NGINX举例,Nginx从1.1.4开始支持到后端的长连接池,不过在之前是使用的HTTP/1协议与后端通信,即创建连接处理完之后销毁。)
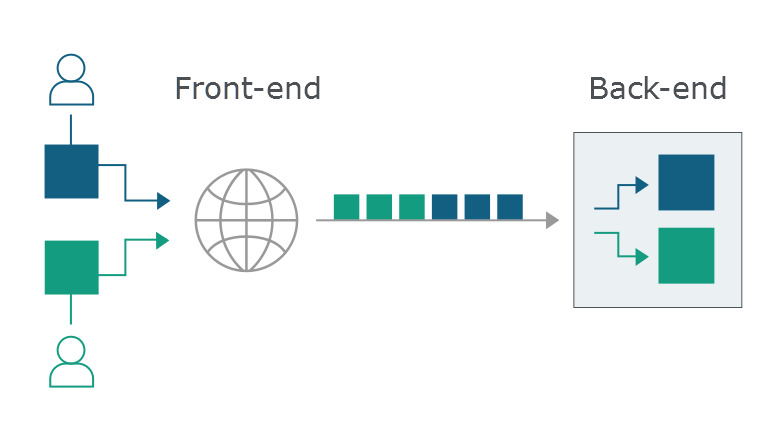
大家的请求都合在一起了,如何区分请求与请求之间的边界呢?接下来我们再来看看Http协议中的Transfer-Encoding: chunked和Content-Length。
Transfer-Encoding: chunked和Content-Length
Http协议通过Transfer-Encoding: chunked(以下简称TE)或Content-Length(以下简称CL)来确定entity的长度。
TE表示将数据以一系列分块的形式进行发送,在每一个分块的开头需要添加当前分块的长度,以十六进制的形式表示,后面紧跟着 ' ' ,之后是分块本身,后面也是' ' 。终止块是一个常规的分块,不同之处在于其长度为0。
而CL通过直接指定entity的字节长度来完成同样的使命。
那么当它们两个同时出现在Http Header里时会发生什么呢?实际上Http协议规范有明确定义,当这两种确定长度的Header都存在时,应该优先使用TE,然后忽略CL。
看到这,结合上述那段不规范的header field-name解析代码,或许你想到了一些东西?假如一个包含了TE和CL的Http请求被处理了两次会发生什么?接下来,我们来看看具体的情况。
发送攻击请求
此时我们依旧使用 用户 -> A -> B 的例子。 这里我们假设B是存在问题的Netty,而A是一个正常的只识别CL的程序。一个包含了Transfer-Encoding[空格]: chunked 和Content-Length的Http请求来了
POST / HTTP/1.1
Host: vulnerable-website.com
Content-Length: 8
Transfer-Encoding[空格]: chunked
0
FOR
然后又来了一个正常的用户请求
GET /my-info HTTP/1.1
Host: vulnerable-website.com
A
A识别到了CL为8,并将这两个请求合并到一个连接中一起传给B
B
B识别到了Transfer-Encoding[空格],按照规则忽略了CL,此时B会怎么分割这两个请求呢:
请求1
POST / HTTP/1.1
Host: vulnerable-website.com
Content-Length: 8
Transfer-Encoding[空格]: chunked
0
请求2
FORGET /my-info HTTP/1.1
Host: vulnerable-website.com
这就糟糕了:服务端报了一个错,正常用户获得了一个400的响应。
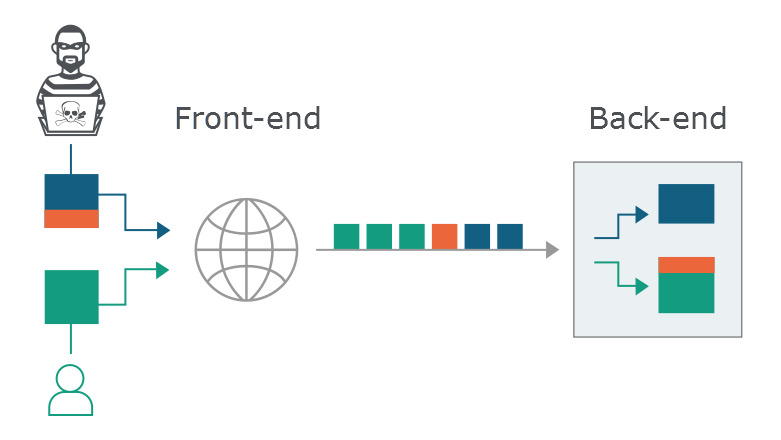
(任何上下游识别请求的分界不一致的情况都会出现这样的问题)
如何避免这样的漏洞
- 避免重用连接,这样的方式会造成性能的下降。
- 使用HTTP/2作为系统间协议,此协议避免了http header的混淆。
- 使用同一种服务器作为上下游服务器。
- 大家都按规范来,不出BUG。
其中我们展开了解一下为什么HTTP/2可以避免这种情况
HTTP/2不会有含糊不清的Header
HTTP/2是一个二进制协议,致力于避免不必要的网络流量以及提高TCP连接的利用率等等。
它对于常用的Header使用了一个静态字典来压缩。比如Content-Length使用28来表示;`
Transfer-Encoding`使用57来表示。这样一来,各种实现就不会有歧义了。更多的定义详见HTTP/2关于Header静态表的定义