发表时间:2020(NeurIPS 2020)
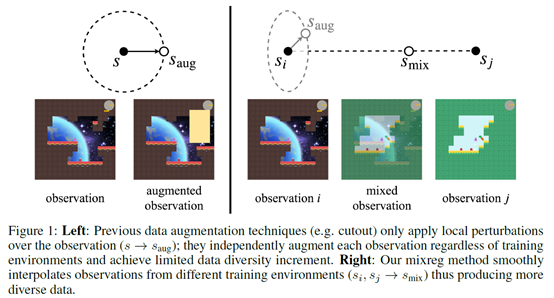
文章要点:这篇文章提出了一个叫mixreg的方法来提高agent泛化性。大致方法就是说用多个环境训练,并且对环境做插值,这样学到的策略就会更平滑,泛化性就更好。具体的,我有两个状态,通过加权插值的方式得到一个新的状态

这里权重λ通过从贝塔分布采样得到

对应的所有的监督信号都要做相应的插值

比如PPO里面advantage和action

DQN里面也同理。然后整个方法就介绍完了,就是这么简单。。
总结:感觉也太简单粗暴了,这也可以是NIPS,还是有点吃惊的,可能就是效果不错?不过这也给了我们这些人一些中NIPS的希望吧。
疑问:如果不同环境的动作空间不一样的话,是不是就没法这么做插值了?
看文章里说,不同环境主要是背景颜色之类的区别,是不是因为这样这个方法才work的?如果真的有两个完全不一样的环境给你插值,插出来的状态可能就四不像了吧。
文章里面提了很多别人做的增强泛化性的方法,结果一做实验甚至比PPO的baseline还差,这感觉有点说不过去啊,难道别人之前的方法都是假的,还是说这些方法不适合强化,就像文章说的这些方法只加了局部扰动,对泛化性没用,而且反而增加了无关的discrepancy,这个解释说得通吗?