
发表时间:2021(ICML 2021)
文章要点:这篇文章提出了一个叫REPresentation And INstance Transfer (REPAINT)的算法来做RL里的知识迁移。主要方法就是representation transfer和instance transfer。这个representation transfer就是用一个cross entropy来约束teacher policy和(pi_θ)的距离,让他俩接近
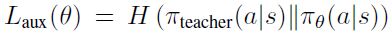
训的时候就和PPO的loss合起来就完了
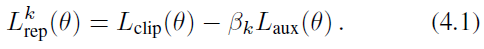
然后这个instance transfer就是说从teacher policy收集的轨迹里面也会有在现在这个task上表现好的轨迹,然后设一个阈值把好的拿出来用来训练(pi_θ),作者把这个叫advantage-based experience selection,然后用到PPO里面的时候那个ratio就不除以(pi_{ heta_{old}})了,而是除以teacher policy

然后更新就是把这两个loss合起来就完了,参见上面的算法伪代码。
总结:实验做了很多,但是从各种参数看来,trick不会少。另外,感觉理论部分的假设有点太多了,而且还没写到正文里面,可能就是实验为主吧。
疑问:这里除以teacher policy的操作修正了权重,但是采样的轨迹是用了threshold之后的,那这个分布也不是(pi_{teacher})的了啊,这么做没有问题吗?
文章里面还专门说了句In addition, our method performs policy update without importance sampling.这个ratio (
ho_ heta)不就是importance sampling吗?